
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Wei Yufeng, Liang Dongtai, Liang Dan, et al. Visual identification and location algorithm for robot based on the multimodal information[J]. Opto-Electronic Engineering, 2018, 45(2): 170650. doi: 10.12086/oee.2018.170650

|
Visual identification and location algorithm for robot based on the multimodal information
-
Abstract
To overcome the problem of a single image source, complex processing and inaccurate positioning, a visual identification and location algorithm based on multi-modal information is proposed, and the fusion processing is performed by extracting the multimodal information of the two-dimensional image and the point cloud image to realize object recognition and positioning. Firstly the target 2D image information is obtained by RGB camera. The contour is recognized through the contour detection and matching process. Then the image SIFT feature is extracted for location tracking and the position of the object is obtained. Meanwhile obtaining a point cloud image by RGB-D camera and the best model can be sorted through pre-processing, Euclidean cluster segmentation, computing VFH feature and KD-tree searching, identifying the point cloud image. Then the orientation is obtained by registering the point clouds. Finally, the two-dimensional images and point cloud image are used to process object information, complete the identification and positioning of the target. The effect of the method is verified by the robotic gripping experiment. The result shows that the multi-modal information of two-dimensional image and point cloud image can be used to identify and locate different target objects. Compared with the processing method using only two-dimensional or point cloud single-mode image information, the positioning error can be reduced to 50%, the robustness and accuracy are better.-
Keywords:
- 2D image /
- point cloud /
- multimodal /
- feature recognition and positioning /
- robot
-

-
References
[1] Collet A, Srinivasa S S. Efficient multi-view object recognition and full pose estimation[C]//Proceeding of 2010 IEEE International Conference on Robotics and Automation, 2010: 2050-2055. [2] Munoz E, Konishi Y, Murino V, et al. Fast 6D pose estimation for texture-less objects from a single RGB image[C]//Proceeding of 2016 IEEE International Conference on Robotics and Automation, 2016: 5623-5630. [3] Zhu M L, Derpanis K G, Yang Y F, et al. Single Image 3D object detection and pose estimation for grasping[C]//Proceeding of 2014 IEEE International Conference on Robotics and Automation, 2014: 3936-3943. [4] Bo L F, Lai K, Ren X F, et al. Object recognition with hierarchical kernel descriptors[C]//Proceedings of 2011 IEEE Conference on Computer Vision and Pattern Recognition, 2011: 1729-1736. [5] Rusu R B, Blodow N, Beetz M. Fast point feature histograms (FPFH) for 3D registration[C]//Proceeding of 2009 IEEE International Conference on Robotics and Automation, 2009: 3212-3217. [6] Braun M, Rao Q, Wang Y K, et al. Pose-RCNN: Joint object detection and pose estimation using 3D object proposals[C]// Proceeding of the 19th International Conference on Intelligent Transportation Systems (ITSC), 2016: 1546-1551. [7] Pavlakos G, Zhou X W, Chan A, et al. 6-DoF object pose from semantic keypoints[C]//Proceeding of 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017: 2011-2018. [8] 段军, 高翔.基于统计滤波的自适应双阈值改进canny算子边缘检测算法[J].激光杂志, 2015, 36(1): 10-12. Duan J, Gao X. Adaptive statistical filtering double threshholds based on improved canny operator edge detection algorithm[J]. Laser Journal, 2015, 36(1): 10-12. [9] Sánchez-Torrubia M G, Torres-Blanc C, López-Martínez M A. Pathfinder: A visualization eMathTeacher for actively learning Dijkstra's algorithm[J]. Electronic Notes in Theoretical Computer Science, 2009, 224: 151-158. doi: 10.1016/j.entcs.2008.12.059 [10] Richtsfeld A, Vincze M. Basic object shape detection and tracking using perceptual organization[C]//Proceeding of 2009 IEEE International Conference on Advanced Robotics, 2009: 1-6. [11] Mörwald T, Prankl J, Richtsfeld A, et al. BLORT -the blocks world robotic vision toolbox[Z]. 2010: 1-8. [12] 戴静兰. 海量点云预处理算法研究[D]. 杭州: 浙江大学, 2006. DAI J L. A research on preprocessing algorithms of mass point cloud[D]. Hangzhou: Zhejiang University, 2006. http://cdmd.cnki.com.cn/Article/CDMD-10335-2006033284.htm [13] Rusu R B, Cousins S. 3D is here: Point Cloud Library (PCL)[C]//Proceeding of 2011 IEEE International Conference on Robotics and Automation, 2011: 1-4. [14] Zhao T, Li H, Cai Q, et al. Point Cloud Segmentation Based on FPFH Features[C]// Proceedings of 2016 Chinese Intelligent Systems Conference. Singapore, Springer, 2016. [15] Rusu R B, Bradski G, Thibaux R, et al. Fast 3D recognition and pose using the viewpoint feature histogram[C]//Proceeding of 2010 IEEE International Conference on Intelligent Robots and Systems, 2010: 2155-2162. [16] 朱德海.点云库PCL学习教程[M].北京:北京航空航天大学出版社, 2012: 338-355. Zhu D H. Point cloud library PCL[M]. Beijing: Beijing University of Aeronautics and Astronautics Press, 2012: 338-355. [17] 黄风山, 秦亚敏, 任玉松.成捆圆钢机器人贴标系统图像识别方法[J].光电工程, 2016, 43(12): 168-174. doi: 10.3969/j.issn.1003-501X.2016.12.026 Huang F S, Qin Y M, Ren Y S. The image recognition method on round bales robot labeling system[J]. Opto-Electronic Engineering, 2016, 43(12): 168-174. doi: 10.3969/j.issn.1003-501X.2016.12.026 -
Overview

Overview: In recent years, various kinds of robots have got studied and used with the development of the robotics technology. In industrial production, workers often need to complete a large number of handling and assembly work. Using robots instead of the workers to complete these tasks would help to increase the efficiency of factories and reduce the labor intensity. Sensing the position of objects is one of the key problems for the robots to complete the task of picking objects. Machine vision is an effective methods to solve this problem, and it is also one of the research hotspots in the robot field at present. Traditional methods are based on two-dimensional images. Because two-dimensional images can not meet the demand, researchers extend their vision to three-dimensional images. Recent years, neural networks have been applied comprehensively, and machine vision has developed rapidly. However, for the traditional research methods, most of the sources of image information are single and basically come from one type of image. As the scene is always rather complicated, the traditional methods are usually faced with the problems such as incomplete image information, large recognition error and low accuracy.
To overcome these problems, a visual identification and location algorithm based on multi-modal information is proposed, and the fusion process is performed by extracting the multimodal information of the two-dimensional image and the point cloud image to realize object recognition and positioning. Firstly, the target 2D image information is obtained by RGB camera. The contour is recognized through the contour detection and matching process. Then, the image SIFT feature is extracted for location tracking and the position of object is obtained. Meanwhile, in order to identify the point cloud image, a point cloud image is captured by RGB-D camera and the best model can be sorted through pre-processing, Euclidean cluster segmentation, computing VFH feature and KD-tree searching. Thus, the orientation can be obtained by registering the point clouds. Finally, use the two-dimensional images and point cloud image to process object information, and to complete the identification and positioning of the target. The effect of the method is verified by the robotic gripping experiment. The results show that the multi-modal information of two-dimensional image and point cloud images can be used to identify and locate different target objects. Compared with the processing method using only two-dimensional or point cloud single-mode image information, the positioning error can be reduced to 50%, and the robustness and accuracy can be improved effectively.
-
Access History
Figures(14)
Tables(5)
Article Metrics


Export File
Citation
Wei Yufeng, Liang Dongtai, Liang Dan, et al. Visual identification and location algorithm for robot based on the multimodal information[J]. Opto-Electronic Engineering, 2018, 45(2): 170650. doi: 10.12086/oee.2018.170650
Format
Content
 DownLoad:
DownLoad:




-
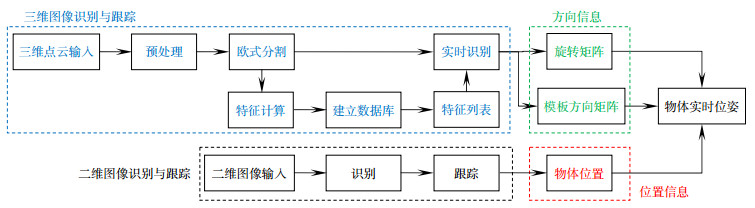
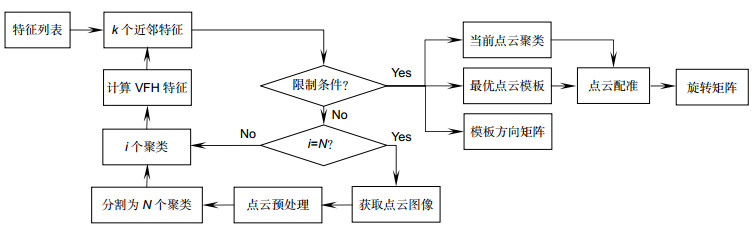
Figure 1.
The architecture of identification and location algorithm
-
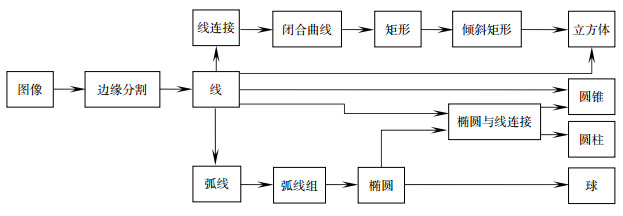
Figure 2.
The flow chart of searching contour
-
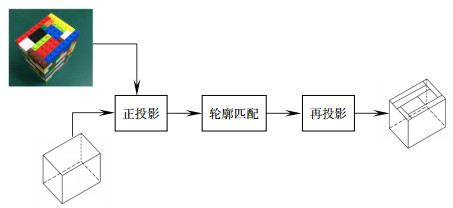
Figure 3.
Build a projection relationship
-
Figure 4.
Point cloud containing the target object. (a) The original image; (b) The image after pretreatment
-
Figure 5.
The image of point cloud after segmentation. (a) The image of other object; (b) The image of target object
-
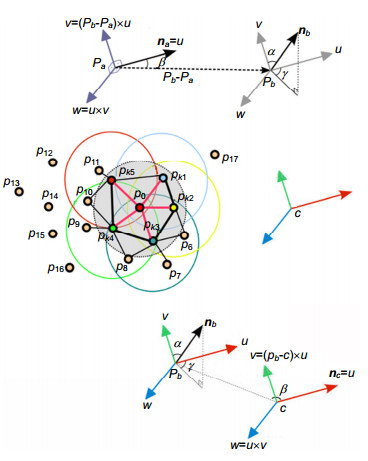
Figure 6.
Computing VFH feature[16]
-
Figure 7.
Real-time identification algorithm
-
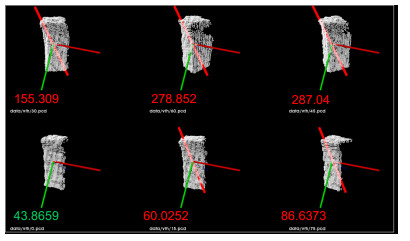
Figure 8.
The result of searching nearest neighbors
-
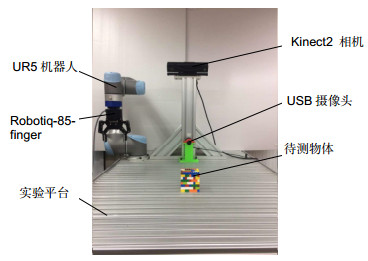
Figure 9.
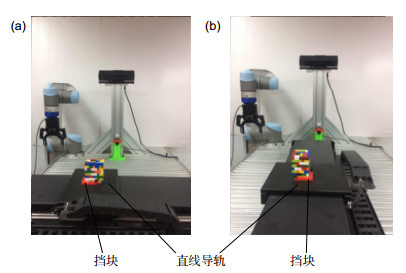
The experiment platform
-
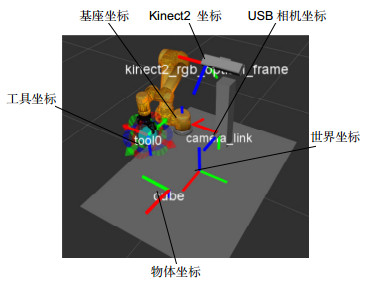
Figure 10.
The experiment platform in MoveIt
-
Figure 11.
The measurement equipment
-
Figure 12.
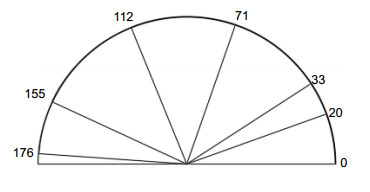
The measuring figure of rotation accuracy
-
Figure 13.
The image of object occlusion recognition effect. (a) The original image; (b) After recognizing
-
Figure 14.
The recognition effect image of different objects. (a) Cylinder; (b) Triangular prism


