
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Wang Fei, Wang Wei, Qiu Zhiliang. A single super-resolution method via deep cascade network[J]. Opto-Electronic Engineering, 2018, 45(7): 170729. doi: 10.12086/oee.2018.170729

|
A single super-resolution method via deep cascade network
-
Abstract
Convolutional neural networks have recently been shown to have the highest accuracy for single image super-resolution (SISR) reconstruction. Most of the network structures suffer from low training and reconstruction speed, and still have the problem that one model can only be rebuilt for a single scale. For these problems, a deep cascaded network (DCN) is designed to reconstruct the image step by step. L2 and the perception loss function are used to optimize the network together, and then a high quality reconstructed image will be obtained under the joint action of each cascade. In addition, our network can get reconstructions of different scales, such as 1.5×, 2×, 2.5×, 3×, 3.5× and 4×. Extensive experiments on several of the largest benchmark datasets demonstrate that the proposed approach performs better than existing methods in terms of accuracy and visual improvement.-
Keywords:
- deep learning /
- super-resolution /
- step by step /
- multi scale /
- perception loss function
-

-
References
[1] Schulter S, Leistner C, Bischof H. Fast and accurate image upscaling with super-resolution forests[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3791-3799. [2] Bevilacqua M, Roumy A, Guillemot C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding[C]//British Machine Vision Conference, 2012. [3] Chang H, Yeung D Y, Xiong Y M. Super-resolution through neighbor embedding[C]//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004: I. [4] Timofte R, De V, Van Gool L. Anchored neighborhood regression for fast example-based super-resolution[C]//IEEE International Conference on Computer Vision, 2013: 1920-1927. [5] 吴从中, 胡长胜, 张明君, 等.有监督多类字典学习的单幅图像超分辨率重建[J].光电工程, 2016, 43(11): 69-75. doi: 10.3969/j.issn.1003-501X.2016.11.011 Wu C Z, Hu C S, Zhang M J, et al. Single image super-resolution reconstruction via supervised multi-dictionary learning[J]. Opto-Electronic Engineering, 2016, 43(11): 69-75. doi: 10.3969/j.issn.1003-501X.2016.11.011 [6] 詹曙, 方琪.边缘增强的多字典学习图像超分辨率重建算法[J].光电工程, 2016, 43(4): 40-47. Zhan S, Fang Q. Image super-resolution based on edge-enhancement and multi-dictionary learning[J]. Opto-Electronic Engineering, 2016, 43(4): 40-47. [7] 汪荣贵, 汪庆辉, 杨娟, 等.融合特征分类和独立字典训练的超分辨率重建[J].光电工程, 2018, 45(1): 170542. doi: 10.12086/oee.2018.170542 Wang R G, Wang Q H, Yang J, et al. Image super-resolution reconstruction by fusing feature classification and independent dictionary training[J]. Opto-Electronic Engineering, 2018, 45(1), 170542 doi: 10.12086/oee.2018.170542 [8] Dong C, Loy C C, He K M, et al. Learning a deep convolutional network for image super-resolution[C]//Computer Vision ECCV 2014. Springer International Publishing, 2014: 184-199. [9] Dong C, Loy C C, He K M, et al. Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(2): 295-307. doi: 10.1109/TPAMI.2015.2439281 [10] Shi W, Caballero J, Huszar F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network[C]// Computer Vision and Pattern Recognition. IEEE, 2016: 1874-1883. [11] Kim J, Lee J K, Lee K M. Accurate image super-resolution using very deep convolutional networks[C]//Computer Vision and Pattern Recognition. IEEE, 2016: 1646-1654. [12] Tai Y, Yang J, Liu X M. Image super-resolution via deep recursive residual network[C]//IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2790-2798. [13] Kim J, Lee J K, Lee K M. Deeply-recursive convolutional network for image super-resolution[C]//Computer Vision and Pattern Recognition. IEEE, 2016: 1637-1645. [14] Dong C, Loy C C, Tang X O. Accelerating the super-resolution convolutional neural network[C]//Computer Vision ECCV, 2016: 391-407. [15] Johnson J, Alahi A, Li F F. Perceptual losses for real-time style transfer and super-resolution[C]//Computer Vision-ECCV 2016, 2016, 9906: 694-711. [16] Wang L, Guo S, Huang W, et al. Places205-VGGNet models for scene recognition[EB/OL]. https://arxiv.org/abs/1508.01667. [17] Yang J, Wright J, Huang T S, et al. Image super-resolution via sparse representation[J]. IEEE Transactions on Image Processing, 2010, 19(11): 2861-2873. doi: 10.1109/TIP.2010.2050625 [18] Martin D, Fowlkes C, Tal D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Proceedings 8th IEEE International Conference on Computer Vision, 2001, 2: 416-423. [19] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations[C]//International Conference on Curves and Surfaces, 2010, 6920: 711-730. [20] Huang J B, Singh A, Ahuja N. Single image super-resolution from transformed self-exemplars[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 5197-5206. [21] Martin D, Fowlkes C, Tal D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Proceedings 8th IEEE International Conference on Computer Vision, 2001, 2: 416-423. [22] Jia Y Q, Shelhamer E. Caffe: Convolutional Architecture for fast feature embedding[EB/OL]. https: //arxiv. org/abs/1408. 5093. [23] Timofte R, De Smet V, Van Gool L. A+: Adjusted anchored neighborhood regression for fast super-resolution[C]// Cremers D, Reid I, Saito H, et al. Computer Vision--ACCV 2014, 2014, 9006: 111-126. [24] Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612. doi: 10.1109/TIP.2003.819861 -
Overview

Overview: Recovering high resolution (HR) image from its low resolution (LR) image is an important issue in the field of digital image processing and other vision tasks. Recently, Dong et al. found that a convolutional neural network (CNN) can be used to learn end-to-end mapping from LR to HR. The network is expanded into many different forms, using sub-pixel convolutional network, very deep convolutional network, and recursive residual network. Although these models have achieved the desired results, the issues still exist some problems as described as following. First, most methods use up-sampling operators, such as bi-cubic interpolation, to upscale the input image to the bigger size. This pre-processing adds considerable unnecessary computations and often results in visible reconstruction artifacts. To solve this problem, there are several algorithms such as ESPCN using sub-pixels and FSRCNN with transposed convolution. However, the network structures of these methods are extremely too simple to lean complex and detailed mappings. Second, most existing methods use only L2 to optimize the network, which will result in an excessively smooth image less suitable for human vision. Third, those methods cannot reconstruct more than one scale, which means a model is only for one scale, and this will increase the extra-works of training for the other scales, especially for large-scale training.
To address these defects, we propose a deep cascaded network (DCN). DCN is a cascade structure, and it takes an LR image as input and predicts a residual image in each scale. The predicted residual for each scale is used to efficiently reconstruct the HR image through up-sampling and adding operations. We train the DCN with L2 and perceptual loss function to obtain a robust image.
Our approach differs from existing CNN-based methods in the following aspects:
1) Multiple scales with cascade layers. Our network has a cascade structure and generates multiple intermediate SR predictions in feed-forward process. This progressive reconstruction can get more accurate results. Our 4× model can obtain 1.5×, 2×, 2.5×, 3×, 3.5× reconstructed images.
2) Optimize network with L2 and perceptual loss function. Using L2 can get more accurate pixel-level reconstruction and using perceptual loss function may be closer to human vision.
3) Features extraction on LR image. Our method does not require traditional interpolation methods to up-sample images as a pre-processing, thus greatly reducing the computational complexity.
Extensive experiments on several large benchmark datasets show that the proposed approach performs better than existing methods in terms of accuracy and visual improvement.
-
Access History
Figures(6)
Tables(2)
Article Metrics

Export File
Citation
Wang Fei, Wang Wei, Qiu Zhiliang. A single super-resolution method via deep cascade network[J]. Opto-Electronic Engineering, 2018, 45(7): 170729. doi: 10.12086/oee.2018.170729
Format
Content
 DownLoad:
DownLoad:



-
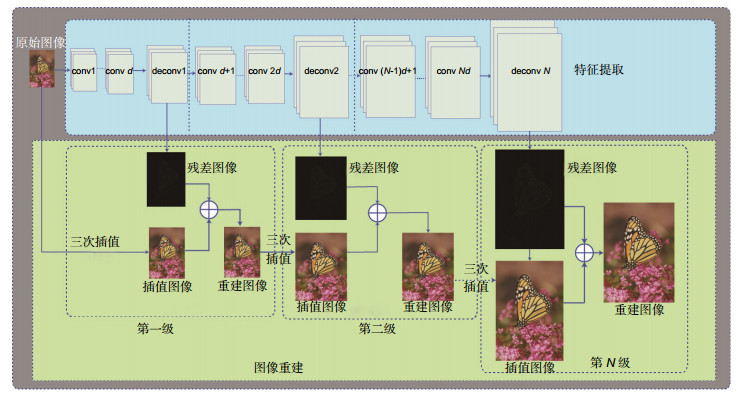
Figure 1.
Deep cascaded network architectures. The light green part is the image reconstruction of each cascade, while the light blue part is the part of the feature extraction and for each cascade. This network includes several convolution layers and one transposed convolutions layer (upsampling) in each cascade
-
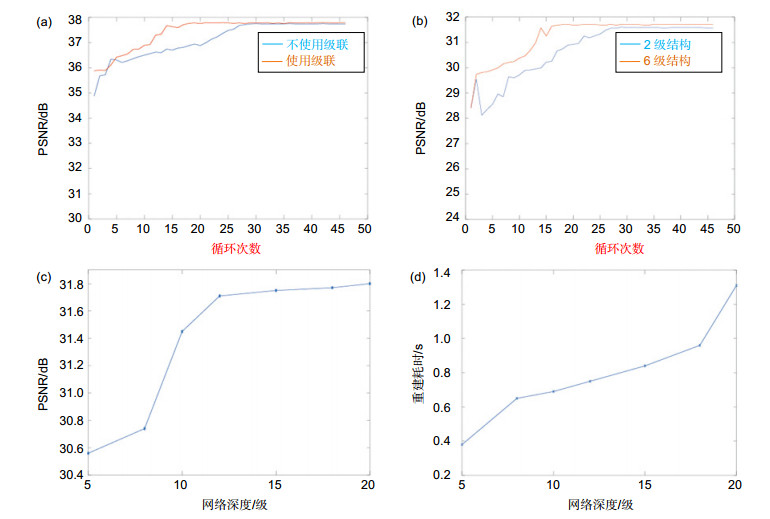
Figure 2.
The effects of different network parameters on the reconstruction effect and time consuming
-
Figure 3.
"Baby" from Set5 with an upscaling factor 4, DCN can reconstruct eyelashes better, DCN- L2 is lower than DCN on both PSNR and SSIM (using L2 and perceptual loss optimization)
-
Figure 4.
"img-092" image from URBAN100 with an upscaling factor 3, DCN model is 3× reconstruction in 4× model, only DCN and DCN-L2 can correctly recover sharp lines, DCN performance is better
-
Figure 5.
4× reconstruction of single frame image in video surveillance, the visual effect of the DCN in the rear window part of the vehicle is more authentic
-
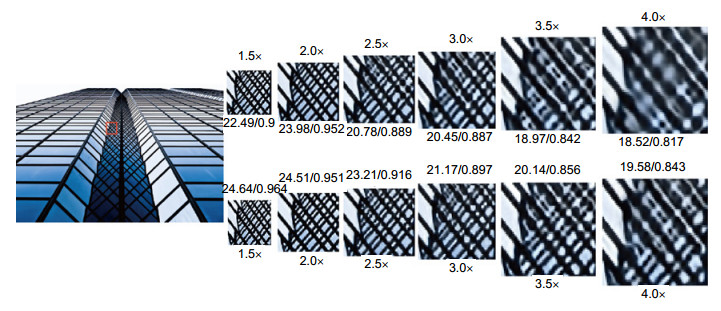
Figure 6.
The comparison between our model and VDSR at different scales(1.5×, 2×, 2.5×, 3×, 3.5×, 4×). The first line is the result of VDSR reconstruction. The second line is reconstructed by our model


