
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Wang Ronggui, Yao Xuchen, Yang Juan, et al. Deep transfer learning for fine-grained categorization on micro datasets[J]. Opto-Electronic Engineering, 2019, 46(6): 180416. doi: 10.12086/oee.2019.180416

|
Deep transfer learning for fine-grained categorization on micro datasets
-
Abstract
Existing fine-grained categorization models require extra manual annotation in addition to the image category labels. To solve this problem, we propose a novel deep transfer learning model, which transfers the learned representations from large-scale labelled fine-grained datasets to micro fine-grained datasets. Firstly, we introduce a cohesion domain to measure the degree of correlation between source domain and target domain. Secondly, select the transferrable feature that are suitable for the target domain based on the correlation. Finally, we make most of perspective-class labels for auxiliary learning, and learn all the attributes through joint learning to extract more feature representations. The experiments show that our model not only achieves high categorization accuracy but also economizes training time effectively, it also verifies the conclusion that the inter-domain feature transition can accelerate learning and optimization. -

-
References
[1] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Proceedings of 2012 International Conference on Neural Information Processing Systems, Lake Tahoe, USA, 2012: 1097-1105. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.299.205 [2] Zhang N, Donahue J, Girshick R, et al. Part-based R-CNNs for fine-grained category detection[C]//Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 834-849. http://citeseerx.ist.psu.edu/viewdoc/similar?doi=10.1.1.431.8701&type=ab [3] Branson S, Van Horn G, Belongie S, et al. Bird species categorization using pose normalized deep convolutional nets[OL]. arXiv preprint arXiv: 1406.2952[cs.CV]. [4] Simon M, Rodner E. Neural activation constellations: unsupervised part model discovery with convolutional networks[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 1143-1151. https://arxiv.org/abs/1504.08289v2 [5] Tan B, Song Y Q, Zhong E H, et al. Transitive transfer learning[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 2015: 1155-1164. https://dl.acm.org/citation.cfm?doid=2783258.2783295 [6] Tzeng E, Hoffman J, Darrell T, et al. Simultaneous deep transfer across domains and tasks[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 2015: 4068-4076. https://ieeexplore.ieee.org/document/7410820?arnumber=7410820 [7] Ge W F, Yu Y Z. Borrowing treasures from the wealthy: deep transfer learning through selective joint fine-tuning[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 10-19. https://ieeexplore.ieee.org/document/8099492 [8] Yosinski J, Clune J, Bengio Y, et al. How transferable are features in deep neural networks?[C]//Proceedings of 2014 International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 3320-3328. https://arxiv.org/abs/1411.1792 [9] Chopra S, Hadsell R, LeCun Y. Learning a similarity metric discriminatively, with application to face verification[C]//Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 2005, 1: 539-546. https://ieeexplore.ieee.org/document/1467314 [10] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5MB model size[OL]. arXiv preprint arXiv: 1602.07360[cs.CV]. [11] Jia Y Q, Shelhamer E, Donahue J, et al. Caffe: convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, USA, 2014: 675-678. https://arxiv.org/abs/1408.5093 [12] Xie S N, Yang T B, Wang X Y, et al. Hyper-class augmented and regularized deep learning for fine-grained image classification[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 2645-2654. https://ieeexplore.ieee.org/document/7298880 [13] Deng J, Dong W, Socher R, et al. ImageNet: A large-scale hierarchical image database[C]//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 2009: 248-255. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5206848 [14] Wah C, Branson S, Welinder P, et al. The Caltech-UCSD birds-200-2011 dataset[R]. California: California Institute of Technology, 2011. [15] Stark M, Krause J, Pepik B, et al. Fine-grained categorization for 3D scene understanding[J]. International Journal of Robotics Research, 2011, 30(13): 1543-1552. doi: 10.1177/0278364911400640 [16] Krause J, Stark M, Deng J, et al. 3D object representations for fine-grained categorization[C]//Proceedings of 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2013: 554-561. [17] Parkhi O M, Vedaldi A, Zisserman A, et al. Cats and dogs[C]//Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, USA, 2012: 3498-3505. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6248092 [18] Lazebnik S, Schmid C, Ponce J. A maximum entropy framework for part-based texture and object recognition[C]//Proceedings of the 10th IEEE International Conference on Computer Vision, Beijing, China, 2005, 1: 832-838. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=1541339 [19] Bo L F, Ren X F, Fox D. Kernel descriptors for visual recognition[C]//Proceedings of the 23rd International Conference on Neural Information Processing Systems, Vancouver, Canada, 2010: 244-252. https://ieeexplore.ieee.org/document/6619212 [20] Murray N, Perronnin F. Generalized max pooling[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 2014: 2473-2480. https://ieeexplore.ieee.org/document/6909713 [21] Khamis S, Lampert C H. CoConut: co-classification with output space regularization[C]//Proceedings of 2014 British Machine Vision Conference, Nottingham, UK, 2014. [22] Wang Y M, Choi J, Morariu V I, et al. Mining discriminative triplets of patches for fine-grained classification[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 2016: 1163-1172. http://ieeexplore.ieee.org/document/7780500/ [23] Deng J, Krause J, Li F F. Fine-grained crowdsourcing for fine- grained recognition[C]//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, USA, 2013: 580-587. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6618925 [24] Wu X M, Mori M, Kashino K. Data-driven taxonomy forest for fine-grained image categorization[C]//Proceedings of 2015 IEEE International Conference on Multimedia and Expo, Turin, Italy, 2015: 1-6. [25] Escalante H J, Ponce-López V, Escalera S, et al. Evolving weighting schemes for the bag of visual words[J]. Neural Computing and Applications, 2017, 28(5): 925-939. doi: 10.1007/s00521-016-2223-x [26] Iscen A, Tolias G, Gosselin P H, et al. A comparison of dense region detectors for image search and fine-grained classification[J]. IEEE Transactions on Image Processing, 2015, 24(8): 2369-2381. doi: 10.1109/TIP.2015.2423557 [27] Kobayashi T. Low-rank bilinear classification: efficient convex optimization and extensions[J]. International Journal of Computer Vision, 2014, 110(3): 308-327. doi: 10.1007/s11263-014-0709-5 [28] Hang S T, Aono M. Bi-linearly weighted fractional max pooling. An extension to conventional max pooling for deep convolutional neural network[J]. Multimedia Tools and Applications, 2017, 76(21): 22095-22117. doi: 10.1007/s11042-017-4840-5 [29] Ionescu R T, Popescu M. Have a SNAK. Encoding spatial information with the spatial non-alignment kernel[C]//Proceedings of 18th International Conference on Image Analysis and Processing, Genoa, Italy, 2015: 97-108. http://link.springer.com/content/pdf/10.1007/978-3-319-23231-7_9.pdf [30] Qian Q, Jin R, Zhu S H, et al. Fine-grained visual categorization via multi-stage metric learning[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, USA, 2015: 3716-3724. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7298995&navigation=1 [31] Wang J J, Yang J C, Yu K, et al. Locality-constrained linear coding for image classification[C]//Proceedings of 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, UAS, 2010: 3360-3367. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5540018 -
Overview

Overview: Fine-grained categorization is challenging due to its small inter-class and large intra-class variance. Moreover, requiring domain expertise makes fine-grained labelled data much more expensive to acquire. Existing models predominantly require extra information such as bounding box and part annotation in addition to the image category labels, which involves heavy human manual labor. To solve this problem, we propose a novel deep transfer learning model, which transfers the learned representations from large-scale labelled fine-grained datasets to micro fine-grained datasets. While the network in deep learning is a unified training and prediction framework that combines multi-level feature extractors and recognizers, end-to-end processing is particularly important. The design concept for our model is to take full advantage of the ability that the convolutional neural network itself can perform end-to-end processing. As is known that feature transfer learning can use the existing data to rapidly construct the corresponding network parameters for new data through end-to-end training, which assumes that the source domain and the target domain contains some common cross-features, data from each domain can be transformed into the same feature space for the following learning. We present a novel discriminative training method that is used to learn similarity measurement, introducing the cohesion-domain quantitative calculation for the correlation between the two domains. Firstly, we introduce a cohesion domain to measure the degree of correlation between source domain and target domain. Secondly, selecting the transferrable feature that are suitable for the target domain based on the correlation. Finally, we make most of perspective-class labels for auxiliary learning, and learn all the attributes through joint learning to extract more feature representations. Our model aims to make joint adjustments from end to end, we expect to explore abundant source-domain attributes through cross-domain learning and capture more complex cross-domain knowledge by embedding cross-dataset information, in order to minimize the original function loss for the learning tasks in two domains as much as possible. For the problem of inter-domain transition network, we freeze part of the network layers to extract relatively more well-defined representations of labelled fine-grained samples for transferring to target domain. Since feature learning has the ability to collect hierarchical information which is not affected by the training data. In this way, the problem of high non-convex model optimization is not only simplified, but also can be modified from a more local perspective. So that subsequent incremental learning can limit the switching task to its own domain, and it is also conducive for multi-task parallel training to share the learned representation from different tasks. The experiments show that our model not only achieves high categorization accuracy but also economizes training time effectively, it also verifies the conclusion that the inter-domain feature transition can accelerate learning and optimization.
-
Access History

Figures(6)
Tables(4)
Article Metrics


Export File
Citation
Wang Ronggui, Yao Xuchen, Yang Juan, et al. Deep transfer learning for fine-grained categorization on micro datasets[J]. Opto-Electronic Engineering, 2019, 46(6): 180416. doi: 10.12086/oee.2019.180416
Format
Content
 DownLoad:
DownLoad:


-
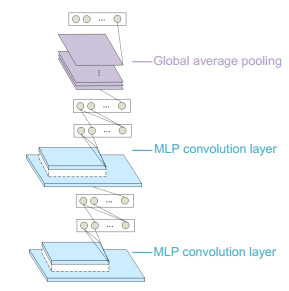
Figure 1.
Overall view of network architecture
-
Figure 2.
Micro network in cohesion domain
-
Figure 3.
Each category in perspective class
-
Figure 4.
Time performance on the source-domain dataset Stanford Cars with and without our method
-
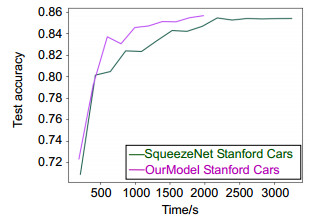
Figure 5.
Time performance on the source-domain dataset Stanford Cars with and without our method
-
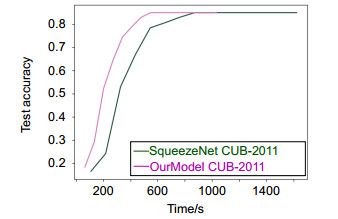
Figure 6.
Time performance on the source-domain dataset CUB-200-2011 with and without our method


