
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Xue Lixia, Jiang Di, Wang Ronggui, et al. Multi-label classification based on attention mechanism and semantic dependencies[J]. Opto-Electronic Engineering, 2019, 46(9): 180468. doi: 10.12086/oee.2019.180468

|
Multi-label classification based on attention mechanism and semantic dependencies
-
Abstract
Multi-label image classification which is a generalization of the single-label image classification is aimed to assign multi-labels to the image to full express the specific visual concepts contained in the image. We propose a method based on convolutional neural networks, which combines attention mechanism and semantic relevance, to solve the multi label problem. Firstly, we use convolution neural network to extract features. Then, we apply the attention mechanism to obtain the correspondence between the label and channel of the feature map. Finally, we explore the channel-wise correlation which is essentially the semantic dependencies between labels by means of supervised learning. The experimental results show that the proposed method can exploit the dependencies between multiple tags to improve the performance of multi label image classification. -

-
References
[1] Sivic J, Zisserman A. Video Google: a text retrieval approach to object matching in videos[C]//Proceedings 9th IEEE International Conference on Computer Vision, 2003: 1470-1477. [2] 汪荣贵, 丁凯, 杨娟, 等.三角形约束下的词袋模型图像分类方法[J].软件学报, 2017, 28(7): 1847-1861. Wang R G, Ding K, Yang J, et al. Image classification based on bag of visual words model with triangle constraint[J]. Journal of Software, 2017, 28(7): 1847-1861. [3] 黄启宏, 刘钊.基于多超平面支持向量机的图像语义分类算法(英文)[J].光电工程, 2007, 34(8): 99-104. doi: 10.3969/j.issn.1003-501X.2007.08.021 Huang Q H, Liu Z. Multiple-hyperplane SVMs algorithm in image semantic classification[J]. Opto-Electronic Engineering, 2007, 34(8): 99-104. doi: 10.3969/j.issn.1003-501X.2007.08.021 [4] Chang C C, Lin C J. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): 27. [5] Breiman L. Random forests[J]. Machine Learning, 2001, 45(1): 5-32. [6] Harzallah H, Jurie F, Schmid C. Combining efficient object localization and image classification[C]//Proceedings of the 12th International Conference on Computer Vision, 2009: 237-244. http://www.researchgate.net/publication/224135968_Combining_efficient_object_localization_and_image_classification [7] Lowe D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. doi: 10.1023/B:VISI.0000029664.99615.94 [8] Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]//Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005: 886-893. http://www.researchgate.net/publication/303607641_Histograms_of_oriented_gradients_for_human_detection [9] Ojala T, Pietikäinen M, Harwood D. A comparative study of texture measures with classification based on featured distributions[J]. Pattern Recognition, 1996, 29(1): 51-59. [10] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv: 1409.1556[cs.CV], 2015. http://www.oalib.com/paper/4068791 [11] Huang G, Liu Z, van der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of 2017 IEEE Computer Vision and Pattern Recognition, 2017: 2261-2269. [12] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770-778. [13] Razavian A S, Azizpour H, Sullivan J, et al. CNN features off-the-shelf: an astounding baseline for recognition[C]// Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 512-519. [14] Deng J, Dong W, Socher R, et al. ImageNet: a large-scale hierarchical image database[C]//Proceedings of 2009 IEEE Computer Vision and Pattern Recognition, 2009: 248-255. http://www.researchgate.net/publication/221361415 [15] Wei Y C, Xia W, Lin M, et al. HCP: a flexible CNN framework for multi-label image classification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(9): 1901-1907. doi: 10.1109/TPAMI.2015.2491929 [16] Cheng M M, Zhang Z M, Lin W Y, et al. BING: binarized normed gradients for objectness estimation at 300fps[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 3286-3293. [17] Wang J, Yang Y, Mao J H, et al. CNN-RNN: a unified framework for multi-label image classification[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 2285-2294. [18] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. doi: 10.1162/neco.1997.9.8.1735 [19] Zhang J J, Wu Q, Shen C H, et al. Multilabel image classification with regional latent semantic dependencies[J]. IEEE Transactions on Multimedia, 2018, 20(10): 2801-2813. doi: 10.1109/TMM.2018.2812605 [20] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proceedings of the 32nd International Conference on Machine Learning, 2015: 448-456. http://www.researchgate.net/publication/272194743_Batch_Normalization_Accelerating_Deep_Network_Training_by_Reducing_Internal_Covariate_Shift [21] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C]//Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, 2011: 315-323. [22] Ba J, Mnih V, Kavukcuoglu K. Multiple object recognition with visual attention[J]. arXiv: 1412.7755[cs.LG], 2015. [23] Xu K, Ba J, Kiros R, et al. Show, attend and tell: neural image caption generation with visual attention[J]. arXiv: 1502.03044[cs.LG], 2015. [24] Wang Z X, Chen T S, Li G B, et al. Multi-label image recognition by recurrently discovering attentional regions[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 464-472. [25] Everingham M, van Gool L, Williams C K I, et al. The Pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338. doi: 10.1007/s11263-009-0275-4 [26] Srivastava N, Salakhutdinov R. Learning representations for multimodal data with deep belief nets[C]//Proceedings of 2012 ICML Representation Learning Workshop, 2012: 79. [27] Wang R G, Xie Y F, Yang J, et al. Large scale automatic image annotation based on convolutional neural network[J]. Journal of Visual Communication and Image Representation, 2017, 49: 213-224. doi: 10.1016/j.jvcir.2017.07.004 [28] Li Y N, Yeh M C. Learning image conditioned label space for multilabel classification[J]. arXiv: 1802.07460[cs.CV], 2018. http://www.researchgate.net/publication/323335326_Learning_Image_Conditioned_Label_Space_for_Multilabel_Classification -
Overview

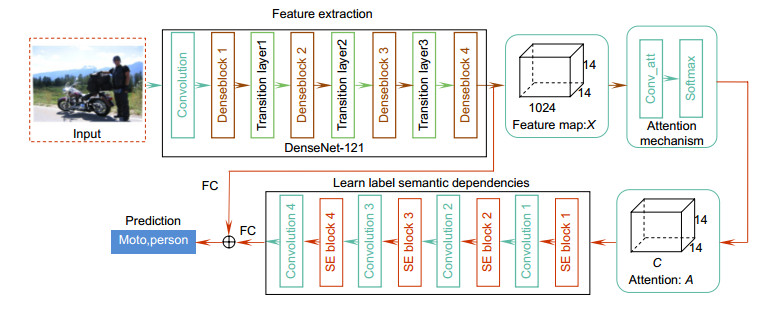
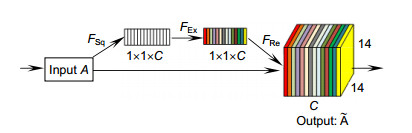
Overview: As a fundamental task of image classification problems, single-label image classification has been researched for decades and has made good progress. However, multi-label image classification task is not only a general and practical problem, but also a challenging task, because most real-world images often contain rich semantic information, such as multiple objects, scenes, attributes, and actions. In this paper, combines attention mechanism and semantic relevance, a method based on convolutional neural networks is proposed to solve the multi label problem. Firstly, we use the recent most popular convolutional neural network denseNet-121 to extract image features. Traditional methods usually to pre-process the images by extracting hand-craft features and train a classifier. However, these hand-craft are designed for different visual tasks. In contrast, the method based on convolutional neural network can extract more discriminative features from images by powerful feature learning ability. Secondly, the attention mechanism which can explore the basic spatial relation has recently been applied to many computer vision tasks. For multi-label images classification, most of the images have different semantic information and we tag them with several labels. We hope that we will use the attention mechanism to focus on the areas of interest where we need to identify and the channels of the feature map can correspond to the categories of the dataset so as to better explore the dependencies between labels. Consequently, we use the image feature map extracted from the network as the input of the attention mechanism and utilize convolution operation to preliminarily learn the conversion relationship between the label and the channel. Then, we employ the softmax function to ensure that each group channel of the feature map has a tag response. The softmax operation may cause visual feature redundancies, because the network also learns some negative feature information, that is, the corresponding labels that are not existed in the images. So, we exploit the SE module to eliminate the negative feature information. The Squeeze-and-Excitation (SE) block which is a structural unit is able to definitely model inter-dependencies between channels. And this unit focuses on channels through adaptively adjusting channel-wise feature information. Finally, we explore the channel-wise correlation which is essentially the semantic dependencies between labels by means of supervised learning. This special approach using the SE block and the convolution operation alternately is able to more accurately learn the dependencies between channels. The experimental results show that the proposed method can exploit the dependencies between multiple tags to improve the performance of multi label image classification.
-
Access History


Export File
Citation
Xue Lixia, Jiang Di, Wang Ronggui, et al. Multi-label classification based on attention mechanism and semantic dependencies[J]. Opto-Electronic Engineering, 2019, 46(9): 180468. doi: 10.12086/oee.2019.180468
Format
Content
 DownLoad:
DownLoad:

-
Figure 1.
An illustration of the framework for multi-label classification
-
Figure 2.
SE(Squeeze-and-excitation) block
-
Figure 3.
Experimental results of MirFLickr25k datasets (24 classes)


