
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Chen Peng, Ren Jinjin, Wang Haixia, et al. Equal-scale structure from motion method based on deep learning[J]. Opto-Electronic Engineering, 2019, 46(12): 190006. doi: 10.12086/oee.2019.190006

|
Equal-scale structure from motion method based on deep learning
-
Abstract
Two problems exist in traditional multi-view geometry method to obtain the three-dimensional structure of the scene. First, the mismatching of the feature points caused by the blurred image and low texture, which reduces the accuracy of reconstruction; second, as the information obtained by monocular camera is lack of scale, the reconstruction results can only determine the unknown scale factor, and cannot get accurate scene structure. This paper proposes a method of equal-scale motion restoration structure based on deep learning. First, the convolutional neural network is used to obtain the depth information of the image; then, to restore the scale information of the monocular camera, an inertial measurement unit (IMU) is introduced, and the acceleration and angular velocity acquired by the IMU and the camera position acquired by the ORB-SLAM2 are demonstrated. The pose is coordinated in both time domain and frequency domain, and the scale information from the monocular camera is acquired in the frequency domain; finally, the depth information of the image and the camera pose with the scale factor are merged to reconstruct the three-dimensional structure of the scene. Experiments show that the monocular image depth map obtained by the Depth CNN network solves the problem that the output image of the multi-level convolution pooling operation has low resolution and lacks important feature information, and the absolute value error reaches 0.192, and the accuracy rate is up to 0.959. The multi-sensor fusion method can achieve a scale error of 0.24 m in the frequency domain, which is more accurate than that of the VIORB method in the frequency domain. The error between the reconstructed 3D model and the real size is about 0.2 m, which verifies the effectiveness of the proposed method.-
Keywords:
- 3D reconstruction /
- deep learning /
- monocular camera /
- scale factor /
- IMU
-

-
References
[1] 刘钢, 彭群生, 鲍虎军.基于多幅图像的场景交互建模系统[J].计算机辅助设计与图形学学报, 2004, 16(10): 1419-1424, 1429. doi: 10.3321/j.issn:1003-9775.2004.10.017 Liu G, Peng Q S, Bao H J. An interactive modeling system from multiple images[J]. Journal of Computer-Aided Design & Computer Graphics, 2004, 16(10): 1419-1424, 1429. doi: 10.3321/j.issn:1003-9775.2004.10.017 [2] 曹天扬, 蔡浩原, 方东明, 等.基于视觉内容匹配的机器人自主定位系统[J].光电工程, 2017, 44(5): 523-533. doi: 10.3969/j.issn.1003-501X.2017.05.008 Cao T Y, Cai H Y, Fang D M, et al. Robot vision localization system based on image content matching[J]. Opto-Electronic Engineering, 2017, 44(5): 523-533. doi: 10.3969/j.issn.1003-501X.2017.05.008 [3] Tomasi C, Kanade T. Shape and motion from image streams under orthography: a factorization method[J]. International Journal of Computer Vision, 1992, 9(2): 137-154. [4] Pollefeys M, Koch R, van Gool L. Self-calibration and metric reconstruction inspite of varying and unknown intrinsic camera parameters[J]. International Journal of Computer Vision, 1999, 32(1): 7-25. [5] 戴嘉境.基于多幅图像的三维重建理论及算法研究[D].上海: 上海交通大学, 2012. Dai J J. Research on the theory and algorithms of 3D reconstruction from multiple images[D]. Shanghai: Shanghai Jiao Tong University, 2012. [6] 张涛.基于单目视觉的三维重建[D].西安: 西安电子科技大学, 2014. Zhang T. 3D reconstruction based on monocular vision[D]. Xi'an: Xidian University, 2014. [7] 许允喜, 陈方.基于多帧序列运动估计的实时立体视觉定位[J].光电工程, 2016, 43(2): 89-94. doi: 10.3969/j.issn.1003-501X.2016.02.015 Xu Y X, Chen F. Real-time stereo visual localization based on multi-frame sequence motion estimation[J]. Opto-Electronic Engineering, 2016, 43(2): 89-94. doi: 10.3969/j.issn.1003-501X.2016.02.015 [8] 黄文有, 徐向民, 吴凤岐, 等.核环境水下双目视觉立体定位技术研究[J].光电工程, 2016, 43(12): 28-33. doi: 10.3969/j.issn.1003-501X.2016.12.005 Huang W Y, Xu X M, Wu F Q, et al. Research of underwater binocular vision stereo positioning technology in nuclear condition[J]. Opto-Electronic Engineering, 2016, 43(12): 28-33. doi: 10.3969/j.issn.1003-501X.2016.12.005 [9] Yi K M, Trulls E, Lepetit V, et al. LIFT: learned invariant feature transform[C]//Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 467-483. [10] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 2016: 770-778. [11] Newell A, Yang K Y, Deng J. Stacked hourglass networks for human pose estimation[C]//Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 2016: 483-499. [12] Zhou T H, Brown M, Snavely N, et al. Unsupervised learning of depth and ego-motion from video[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, USA, 2017: 6612-6619. [13] Newcombe R A, Izadi S, Hilliges O, et al. Kinect Fusion: real-time dense surface mapping and tracking[C]//Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 2011: 127-136. [14] Usenko V, Engel J, Stückler J, et al. Direct visual-inertial odometry with stereo cameras[C]//Proceedings of 2016 IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 2016: 1885-1892. [15] Concha A, Loianno G, Kumar V, et al. Visual-inertial direct SLAM[C]//Proceedings of 2016 IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 2016: 1331-1338. [16] Ham C, Lucey S, Singh S. Hand waving away scale[C]//Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 2014: 279-293. [17] Mur-Artal R, Tardós J D. Visual-inertial monocular SLAM with map reuse[J]. IEEE Robotics and Automation Letters, 2017, 2(2): 796-803. doi: 10.1109/LRA.2017.2653359 [18] Mur-Artal R, Tardós J D. ORB-SLAM2: an open-source slam system for monocular, stereo, and RGB-D cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255-1262. doi: 10.1109/TRO.2017.2705103 [19] Ham C, Lucey S, Singh S. Absolute scale estimation of 3d monocular vision on smart devices[M]//Hua G, Hua X S. Mobile Cloud Visual Media Computing: From Interaction to Service. New York: Springer International Publishing, 2015: 329-344. [20] Mustaniemi J, Kannala J, S rkk S, et al. Inertial-based scale estimation for structure from motion on mobile devices[C]//Proceedings of 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 2017: 4394-4401. [21] Godard C, Mac Aodha O, Brostow G J. Unsupervised monocular depth estimation with left-right consistency[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 2017: 6602-6610. -
Overview

Overview: With the continuous development of technologies such as computer vision, virtual reality, and multimedia communication, it is necessary to realize the targets of real-time obstacle avoidance, robot autonomous navigation, and unmanned driving, so that the equipment can more accurately recognize and understand the surrounding environment. Obtaining a real-sized 3D model is a tendency in the future. The traditional three-dimensional structure restoration methods rely too much on geometric calculations in obtaining image information and camera attitude information from two-dimensional images, which is difficult to play a good role in the absence of little texture, complicated geometric conditions, and monotonous structure. With the development of computer vision, the use of deep learning network to learn pictures and extract hierarchical features has been successfully applied to depth estimation, camera pose estimation, and three-dimensional structure recovery. Meanwhile, acquiring 3D models of real scale of objects is a problem that has always been explored in the field of computer vision.
Two problems exist in the traditional multi-view geometry method to obtain the three-dimensional structure of the scene. First, the mismatching of the feature points caused by the blurred image and low texture, which reduces the accuracy of reconstruction; second, as the information obtained by monocular camera is lack of scale, the reconstruction results can only determine the unknown scale factor, and cannot get accurate scene structure. This paper proposes a method of equal-scale motion restoration structure based on deep learning. First, the convolutional neural network is used to obtain the depth information of the image; then, to restore the scale information of the monocular camera, an inertial measurement unit (IMU) is introduced, and the acceleration and angular velocity acquired by the IMU and the camera position acquired by the ORB-SLAM2 are demonstrated. The pose is coordinated in the both time domain and frequency domain, and the scale information from the monocular camera is acquired in the frequency domain; finally, the depth information of the image and the camera pose with the scale factor are merged to reconstruct the three-dimensional structure of the scene. Experiments show that the monocular image depth map obtained by the Depth CNN network solves the problem that the output image of the multi-level convolution pooling operation has low resolution and lacks important feature information, and the absolute value error reaches 0.192, and the accuracy rate is up to 0.959. The multi-sensor fusion method can achieve a scale error of 0.24 m in the frequency domain, which is more accurate than that of the VIORB method in the frequency domain. The error between the reconstructed 3D model and the real size is about 0.2 m, which verifies the effectiveness of the proposed method.
-
Access History

Figures(6)
Tables(3)
Article Metrics


Export File
Citation
Chen Peng, Ren Jinjin, Wang Haixia, et al. Equal-scale structure from motion method based on deep learning[J]. Opto-Electronic Engineering, 2019, 46(12): 190006. doi: 10.12086/oee.2019.190006
Format
Content
 DownLoad:
DownLoad:


-
Figure 1.
Equal scale structure from motion based on deep learning
-
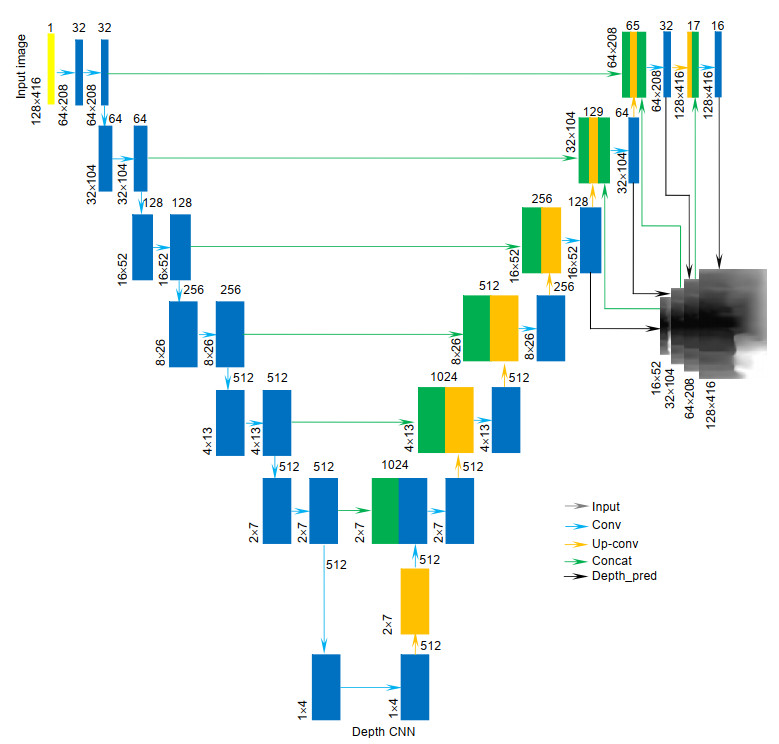
Figure 2.
Network architecture for depth
-
Figure 3.
The experiment platform
-
Figure 4.
Predictions on sculpture. (a) Origin image; (b) Depth CNN; (c) Ground truth; (d) Godard et al[21]
-
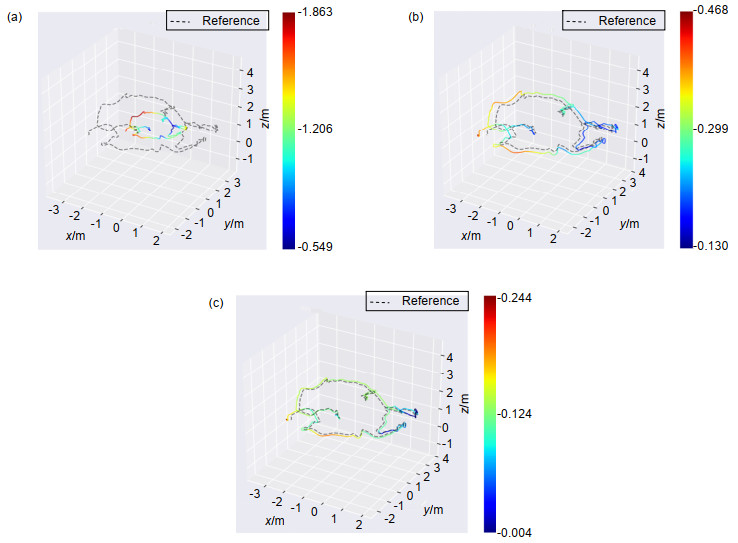
Figure 5.
Comparison of trajectory. (a) ORB-SLAM2; (b) VIORB; (c) Ours method
-
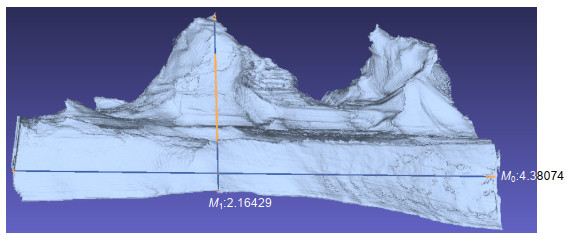
Figure 6.
Equal scale model of sculpture


