
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |

|
Efficient 3D dense residual network and its application in human action recognition
-
Abstract
In view of the problem that 3D-CNN can better extract the spatio-temporal features in video, but it requires a high amount of computation and memory, this paper designs an efficient 3D convolutional block to replace the 3×3×3 convolutional layer with a high amount of computation, and then proposes a 3D-efficient dense residual networks (3D-EDRNs) integrating 3D convolutional blocks for human action recognition. The efficient 3D convolutional block is composed of 1×3×3 convolutional layers for obtaining spatial features of video and 3×1×1 convolutional layers for obtaining temporal features of video. Efficient 3D convolutional blocks are combined in multiple locations of dense residual network, which not only takes advantage of the advantages of easy optimization of residual blocks and feature reuse of dense connected network, but also can shorten the training time and improve the efficiency and performance of spatial-temporal feature extraction of the network. In the classical data set UCF101, HMDB51 and the dynamic multi-view complicated 3D database of human activity (DMV action3D), it is verified that the 3D-EDRNs combined with 3D convolutional block can significantly reduce the complexity of the model, effectively improve the classification performance of the network, and have the advantages of less computational resource demand, small number of parameters and short training time. -

-
References
[1] He K M, Zhang X Y, Ren S Q, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification[C]//2015 IEEE International Conference on Computer Vision (ICCV), Santiago, 2015: 1026–1034. [2] Shojaeilangari S, Yau W Y, Li J, et al. Dynamic facial expression analysis based on extended spatio-temporal histogram of oriented gradients[J]. International Journal of Biometrics, 2014, 6(1): 33–52. [3] Scovanner P, Ali S, Shah M. A 3-dimensional sift descriptor and its application to action recognition[C]//Proceeding MM '07 Proceedings of the 15th ACM international conference on Multimedia, New York, 2007: 357–360. http://www.researchgate.net/publication/221573131_A_3-dimensional_sift_descriptor_and_its_application_to_action_recognition [4] Laptev I, Marszalek M, Schmid C, et al. Learning realistic human actions from movies[C]//2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, 2008: 1–8. [5] Willems G, Tuytelaars T, Van Gool L. An efficient dense and scale-invariant spatio-temporal interest point detector[C]//European Conference on Computer Vision, Berlin, 2008: 650–663. https://link.springer.com/chapter/10.1007%2F978-3-540-88688-4_48 [6] Wang H, Schmid C. Action recognition with improved trajectories[C]//2013 IEEE International Conference on Computer Vision, Sydney, 2014: 3551–3558. [7] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 2014: 568–576. [8] Yao L, Torabi A, Cho K, et al. Describing videos by exploiting temporal structure[C]//2015 IEEE International Conference on Computer Vision (ICCV), Santiago, 2015: 199–211. [9] Shao L, Zhen X T, Tao D C, et al. Spatio-temporal laplacian pyramid coding for action recognition[J]. IEEE Transactions on Cybernetics, 2014, 44(6): 817–827. [10] Hara K, Kataoka H, Satoh Y. Learning spatio-temporal features with 3D residual networks for action recognition[C]//2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, 2017: 3154–3160. http://www.researchgate.net/publication/319311962_Learning_Spatio-Temporal_Features_with_3D_Residual_Networks_for_Action_Recognition [11] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 2015: 448–456. [12] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, 2017: 2261–2269. [13] Song T Z, Song Y, Wang Y X, et al. Residual network with dense block[J]. Journal of Electronic Imaging, 2018, 27(5): 053036. [14] 王永雄, 李璇, 李梁华.动态多视角复杂3D人体行为数据库及行为识别[J].数据采集与处理, 2019, 34(1): 68–79. Wang Y X, Li X, Li L H. Dynamic and multi-view complicated 3D database of human activity and activity recognition[J]. Journal of Data Acquisition & Processing, 2019, 34(1): 68–79. [15] Ji S W, Xu W, Yang M, et al. 3D convolutional neural networks for human action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221–231. [16] Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3D convolutional networks[C]//2015 IEEE International Conference on Computer Vision (ICCV), Santiago, 2014: 4489–4497. http://www.researchgate.net/publication/300408292_Learning_Spatiotemporal_Features_with_3D_Convolutional_Networks [17] Qiu Z F, Yao T, Mei T. Learning spatio-temporal representation with pseudo-3D residual networks[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, 2017: 5534–5542. https://www.researchgate.net/publication/322059525_Learning_Spatio-Temporal_Representation_with_Pseudo-3D_Residual_Networks [18] He K M, Sun J. Convolutional neural networks at constrained time cost[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, 2015: 5353–5360. http://www.researchgate.net/publication/308821532_Convolutional_neural_networks_at_constrained_time_cost [19] Soomro K, Zamir A R, Shah M. UCF101: A dataset of 101 human actions classes from videos in the wild[Z]. arXiv: 1212.0402, 2012. [20] Tran D, Torresani L. EXMOVES: mid-level features for efficient action recognition and video analysis[J]. International Journal of Computer Vision, 2016, 119(3): 239–253. [21] 王正来, 黄敏, 朱启兵, 等.基于深度卷积神经网络的运动目标光流检测方法[J].光电工程, 2018, 45(8): 38–47. doi: 10.12086/oee.2018.180027 Wang Z L, Huang M, Zhu Q B, et al. The optical flow detection method of moving target using deep convolution neural network[J]. Opto-Electronic Engineering, 2018, 45(8): 38–47. doi: 10.12086/oee.2018.180027 [22] Wang X H, Gao L L, Wang P, et al. Two-stream 3-D convNet fusion for action recognition in videos with arbitrary size and length[J]. IEEE Transactions on Multimedia, 2018, 20(3): 634–644. [23] Varol G, Laptev I, Schmid C. Long-term temporal convolutions for action recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(6): 1510–1517. -
Overview

Overview: In view of the problem that 3D-CNN can better extract the spatio-temporal features in video, but it requires a high amount of computation and memory, this paper designs an efficient 3D convolutional block to replace the 3×3×3 convolutional layer with a high amount of computation, and then proposes a 3D-efficient dense residual networks (3D-EDRNs) integrating 3D convolutional blocks for human action recognition. The efficient 3D convolutional block is composed of 1×3×3 convolutional layers for obtaining spatial features of video and 3×1×1 convolutional layers for obtaining temporal features of video. The spatial dimension convolution results are directly used as the input of time dimension convolution, which is helpful to retain the original information with abundant spatio-temporal characteristics. According to the residual network, the information flow can be transmitted from the shallow layer to the deeper layer. The dense network can apply the extended repetition features to the entire network. 3D-EDRNs is designed as a combination of a small dense connection network and a residual structure, which is used to extract the spatial-temporal features of video. The new dense residual structure extends the original dense residual structure from 2D to 3D, and integrates E3DB, which can accelerate the network training and improve the performance of the residual network. Input of the add layer is processed through the structural design of the DRB, which are all feature graphs of inactivated functions, thus, 3D-EDRNs can effectively obtain the information flow between convolutional layers, which is helpful for the network to extract the spatial-temporal features. The concatenate layer can fully integrate the shallow and high level features obtained by the network. 3D-EDRNs extracts the variable and complex spatio-temporal features of video, and the information flow between convolutional layers can also be transmitted to each layer smoothly, thus improving the utilization rate of network parameters and avoiding the problem of parameter expansion of common neural networks. Efficient 3D convolutional blocks are combined in multiple locations of dense residual network, which not only takes advantage of easy optimization of residual blocks and feature reuse of dense connected network, but also can shorten the training time and improve the efficiency and performance of spatial-temporal feature extraction of the network. In the classical data set UCF101, HMDB51 and the dynamic multi-view complicated 3D database of human activity (DMV action3D), it is verified that the 3D-EDRNs combined with 3D convolutional block can significantly reduce the complexity of the model, effectively improve the classification performance of the network, and have the advantages of less computational resource demand, small number of parameters and short training time.
-
Access History
Figures(11)
Tables(4)
Article Metrics


Export File
Citation
Format
Content
 DownLoad:
DownLoad:

-
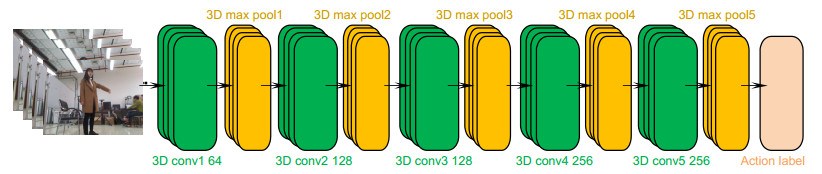
Figure 1.
C3D network architecture
-
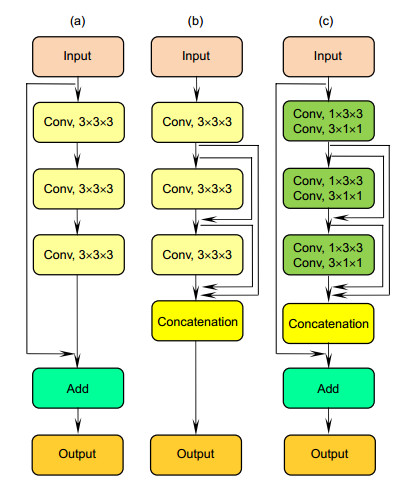
Figure 2.
Residual network and dense connection. (a) Residual block; (b) Dense block; (c) Dense connection residual block
-
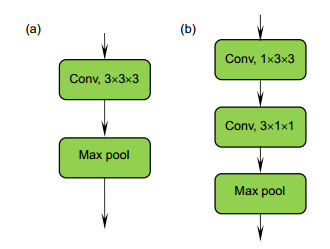
Figure 3.
Standard 3×3×3 convolution (a) and E3DB (b)
-
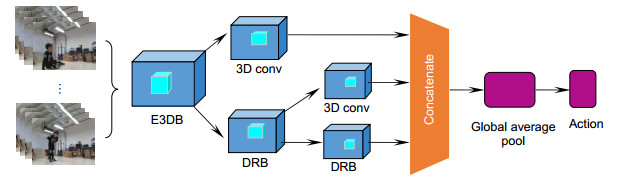
Figure 4.
3D-EDRNs structure diagram
-
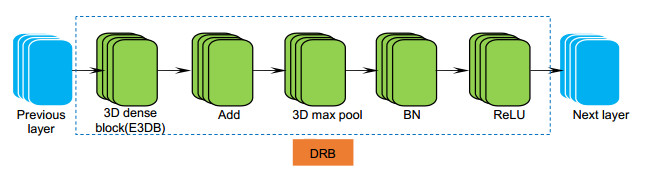
Figure 5.
DRB structure diagram
-
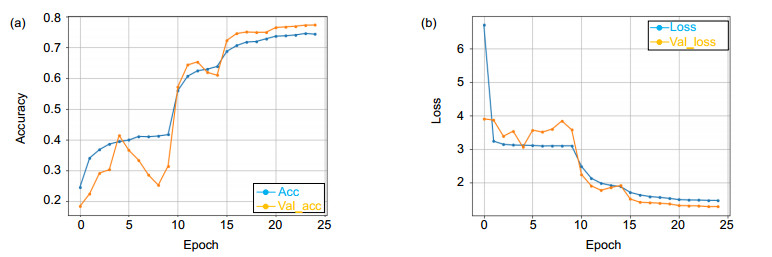
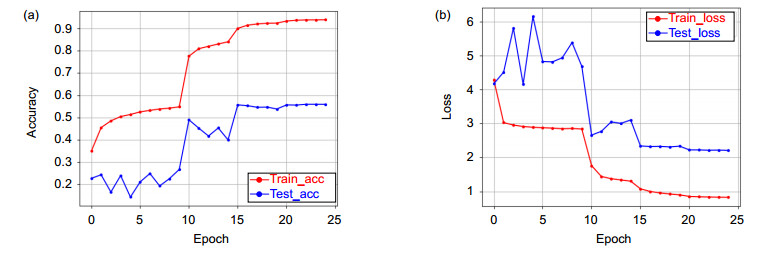
Figure 6.
3D-EDRNs iteration accuracy (a) and loss value (b) variation diagram in HMDB51(lower features are integrated into E3DB)
-
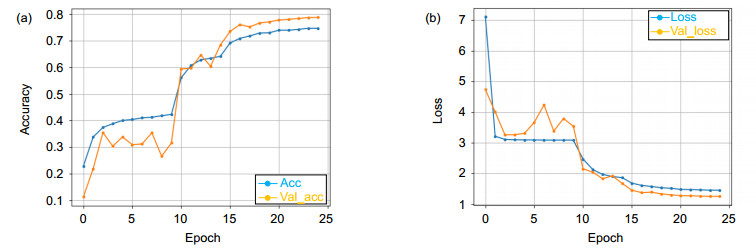
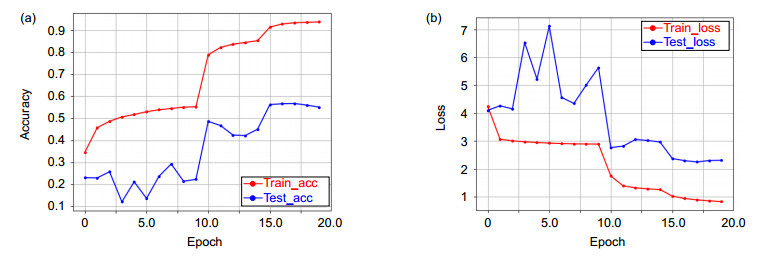
Figure 7.
3D-EDRNs iteration accuracy (a) and loss value (b) variation diagram in HMDB51 (lower features and dense blocks are integrated into E3DB)
-
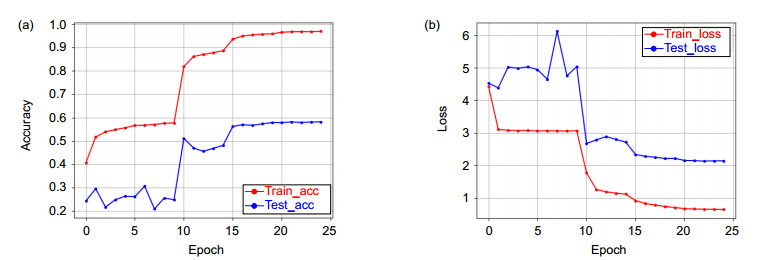
Figure 8.
3D-EDRNs iteration accuracy (a) and loss value (b) variation diagram in HMDB51 (upper features, lower features and dense blocks are integrated into E3DB)
-
Figure 9.
Variation diagram of 3D-EDRNs iteration accuracy (a) and loss value (b)(upper features, lower features and dense blocks are integrated into E3DB)
-
Figure 10.
Variation diagram of 3D-EDRNs iteration accuracy (a) and loss value (b) (lower features and dense blocks are integrated into E3DB)
-
Figure 11.
Variation diagram of 3D-EDRNs iteration accuracy (a) and loss value (b) (lower features are integrated into E3DB)


