
 E-mail Alert
E-mail Alert RSS
RSS
-
摘要:
路面裂缝检测是道路运营和维护的一项重要工作,由于裂缝没有固定形状而且纹理特征受光照影响大,基于图像的精确裂缝检测是一项巨大的挑战。本文针对裂缝图像的特点,提出了一种U型结构的卷积神经网络UCrackNet。首先在跳跃连接中加入Dropout层来提高网络的泛化能力;其次,针对上采样中容易产生边缘轮廓失真的问题,采用池化索引对图像边界特征进行高保真恢复;最后,为了更好地提取局部细节和全局上下文信息,采用不同扩张系数的空洞卷积密集连接来实现感受野的均衡,同时嵌入多层输出融合来进一步提升模型的检测精度。在公开的道路裂缝数据集CrackTree206和AIMCrack上测试表明,该算法能有效地检测出路面裂缝,并且具有一定的鲁棒性。
 Abstract:
Abstract:Crack detection is one of the most important works in the system of pavement management. Cracks do not have a certain shape and the appearance of cracks usually changes drastically in different lighting conditions, making it hard to be detected by the algorithm with imagery analytics. To address these issues, we propose an effective U-shaped fully convolutional neural network called UCrackNet. First, a dropout layer is added into the skip connection to achieve better generalization. Second, pooling indices is used to reduce the shift and distortion during the up-sampling process. Third, four atrous convolutions with different dilation rates are densely connected in the bridge block, so that the receptive field of the network could cover each pixel of the whole image. In addition, multi-level fusion is introduced in the output stage to achieve better performance. Evaluations on the two public CrackTree206 and AIMCrack datasets demonstrate that the proposed method achieves high accuracy results and good generalization ability.
-
Key words:
- crack detection /
- convolutional neural network /
- UCrackNet /
- receptive field
-

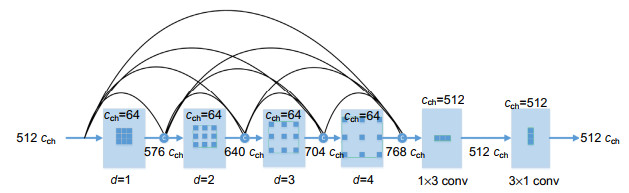
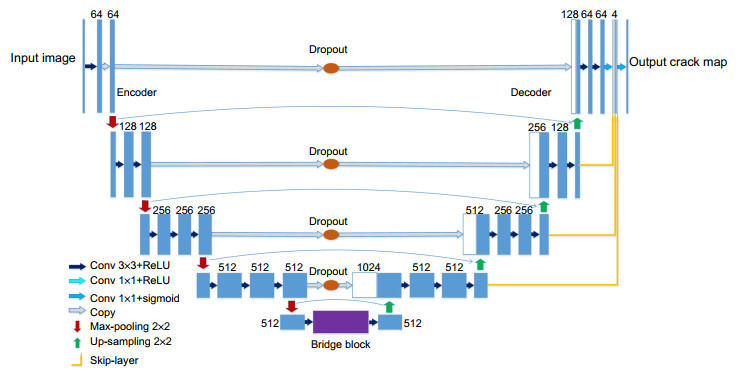
Overview: Cracks are one of the most common categories of pavement distress. Early locating and repairing the cracks can not only reduce the cost of pavement maintenance but also decrease the probability of road accidents happening. Precise measurement of the crack is an essential step toward identifying the road condition and determining rehabilitation strategies. Nevertheless, cracks do not have a certain shape and the appearance of cracks usually changes drastically in different lighting conditions, making it hard to be detected by the algorithm with imagery analytics. Therefore, fully automated and comprehensive crack detection is still challenging. In this paper, we focus on pixel-level crack detection in 2D vision and propose an effective U-shaped fully convolutional neural network called UCrackNet, which is the enhanced version of U-Net. It consists of three main components: an encoder, a bridge block, and a decoder. The backbone of the encoder is the pre-trained VGG-16 that extracts spatial features from the pavement image. The last convolutional layer at each scale in the encoder has a skip connection to connect the corresponding layer in the decoder to preserve and reuse feature maps at different pooling stages. To minimize the possibility of overfitting and achieve better generalization ability, we add a dropout layer into each skip connection. The bridge block is a bridge path between the encoder and the decoder. Motivated by DenseASPP, four densely connected atrous convolutional layers with different dilation rates are employed in the bridge block, so that it generates features with a larger receptive field to effectively capture multi-scale information. The decoder has four convolutional blocks, and in each block, up-sampling with indices is used to reduce the shift and distortion during the up-sampling operation. Furthermore, multi-level fusion is introduced in the output stage to utilize multiscale and multilevel information of objects. The idea of multi-level fusion is inspired by the success of the HED network architecture, which showed that it is capable of fully exploiting the rich feature hierarchies from convolutional neural network (CNNs). Specifically, the feature maps of each stage are first up-sampled to the size of the output image, then a 1×1 convolutional is used to fuse these maps to get the final prediction map. Qualitative evaluations on the two public CrackTree206 and AIMCrack datasets demonstrate that the proposed method achieves superior performance compared with CrackForest, LinkNet, ResUNet, U-Net, and DeepCrack. The qualitative results show that our method produces high-quality crack maps, which are closer to the ground-truth and have lower noise compared with the other methods.
-

-
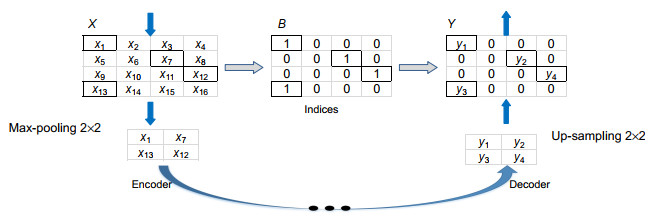
图 2 池化索引操作示意图。左侧是2× 2的最大池化操作,右侧是带位置索引的2× 2上采样操作
Figure 2. An illustration of pooling indices. The left and right sides show the operation of max-pooling and up-sampling, respectively
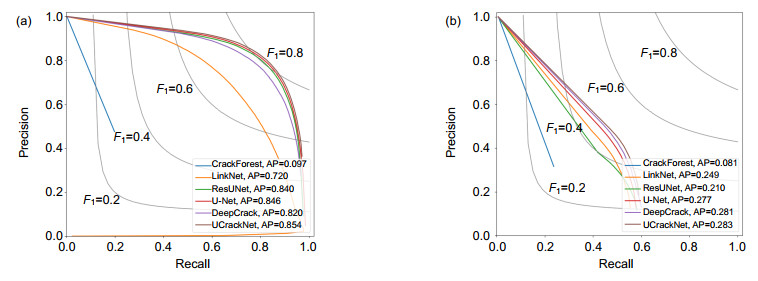
图 5 不同算法在两个数据集中的精度-召回率(P-R)曲线图。(a) CrackTree206;(b) AIMCrack
Figure 5. The precision-recall (PR) curves of various methods on the two datasets. (a) CrackTree206; (b) AIMCrack
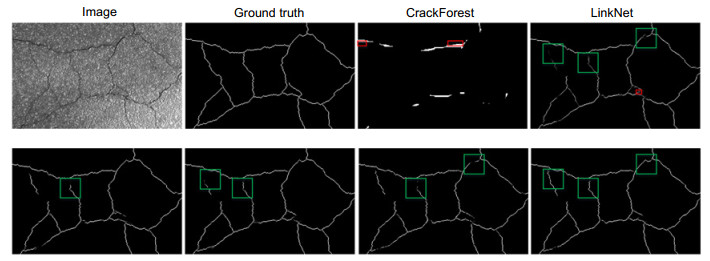
图 6 CrackTree206数据集上的检测结果对比
Figure 6. The predicted results by different methods on the CrackTree206 dataset
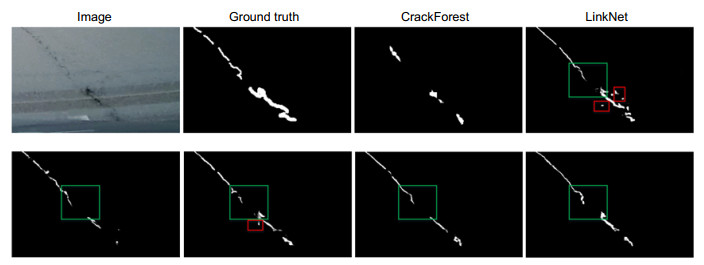
图 7 AIMCrack数据集上的检测结果对比
Figure 7. The predicted results by different methods on the AIMCrack dataset
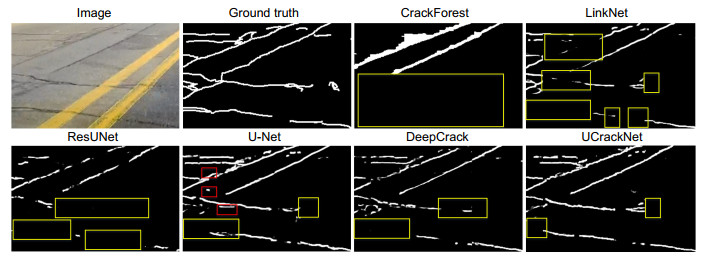
图 8 复杂场景下的检测结果对比
Figure 8. The predicted results by different methods on the challenging scenario
表 1 各层的感受野
Table 1. The receptive field of different layers
Layer Parameter RF current RF stacked 1 d1=1, K1=3, S1=1 3 3 2 d2=2, K2=3, S2=1 5 7 3 d3=3, K3=3, S3=1 7 13 4 d4=4, K4=3, S4=1 9 21  下载: 导出CSV
下载: 导出CSV
表 2 两个裂缝数据集的训练样本对比
Table 2. Comparison of the two different training sets
Dataset Image resolution Patch resolution Patches CrackTree206 800×600 160×160 7938 AIMCrack 1920×384 192×192 18639
下载: 导出CSV
表 3 UCrackNet消融实验的结果
Table 3. The result of ablation study for UCrackNet
Baseline Dropout Pooling indices Larger receptive field Multi-level fusion IoU R P F1 √ 0.295 0.392 0.484 0.433 √ √ 0.299 0.423 0.466 0.443 √ √ √ 0.304 0.396 0.505 0.444 √ √ √ √ 0.315 0.405 0.512 0.452 √ √ √ √ √ 0.327 0.408 0.527 0.460
下载: 导出CSV
表 4 不同算法在数据集CrackTree206和AIMCrack上的结果对比
Table 4. Comparison of performance of various methods on the CrackTree206 and AIMCrack datasets
Method CrackTree206 AIMCrack IoU F1 Time/ms IoU F1 Time/ms CrackForest 0.160 0.281 1545 0.1–40 0.271 2493 LinkNet 0.521 0.684 155 0.285 0.421 156 ResUNet 0.668 0.797 181 0.254 0.377 221 U-Net 0.676 0.804 213 0.309 0.446 242 DeepCrack 0.646 0.783 505 0.312 0.450 510 UCrackNet 0.688 0.812 421 0.327 0.460 453
下载: 导出CSV
-
[1] [2] Schnebele E, Tanyu B F, Cervone G, et al. Review of remote sensing methodologies for pavement management and assessment[J]. European Transport Research Review, 2015, 7(2): 7. doi: 10.1007/s12544-015-0156-6
[3] 张德津, 李清泉.公路路面快速检测技术发展综述[J].测绘地理信息, 2015, 40(1): 1-8. doi: 10.14188/j.2095-6045.2015.01.001
Zhang D J, Li Q Q. A review of pavement high speed detection technology[J]. Journal of Geomatics, 2015, 40(1): 1-8. doi: 10.14188/j.2095-6045.2015.01.001
[4] Shi Y, Cui L M, Qi Z Q, et al. Automatic road crack detection using random structured forests[J]. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(12): 3434-3445. doi: 10.1109/TITS.2016.2552248
[5] 徐威, 唐振民, 吕建勇.基于图像显著性的路面裂缝检测[J].中国图象图形学报, 2013, 18(1): 69-77. doi: 10.11834/jig.20130109
Xu W, Tang Z M, Lv J Y. Pavement crack detection based on image saliency[J]. Journal of Image and Graphics, 2013, 18(1): 69-77. doi: 10.11834/jig.20130109
[6] Zhang L, Yang F, Zhang Y D, et al. Road crack detection using deep convolutional neural network[C]//International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 2016: 3708-3712.
[7] Cha Y J, Choi W, Büyüköztürk O. Deep learning-based crack damage detection using convolutional neural networks[J]. Computer-Aided Civil and Infrastructure Engineering, 2017, 32(5): 361-378. doi: 10.1111/mice.12263
[8] Maeda H, Sekimoto Y, Seto T, et al. Road damage detection and classification using deep neural networks with smartphone images[J]. Computer-Aided Civil and Infrastructure Engineering, 2018, 33(12): 1127-1141. doi: 10.1111/mice.12387
[9] Carr T A, Jenkins M D, Iglesias M I, et al. Road crack detection using a single stage detector based deep neural network[C]//2018 IEEE Workshop on Environmental, Energy and Structural Monitoring Systems, Salerno, Italy, 2018.
[10] Bang S, Park S, Kim H, et al. Encoder-decoder network for pixel-level road crack detection in black-box images[J]. Computer-Aided Civil and Infrastructure Engineering, 2019, 34(8): 713-727. doi: 10.1111/mice.12440
[11] Yang X C, Li H, Yu Y T, et al. Automatic pixel-level crack detection and measurement using fully convolutional network[J]. Computer-Aided Civil and Infrastructure Engineering, 2018, 33(12): 1090-1109. doi: 10.1111/mice.12412
[12] Chen L C, Zhu Y K, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//European Conference on Computer Vision, Glasgow, United Kingdom, 2018: 833-851.
[13] Yang F, Zhang L, Yu S J, et al. Feature pyramid and hierarchical boosting network for pavement crack detection[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(4): 1525-1535. doi: 10.1109/TITS.2019.2910595
[14] Zou Q, Zhang Z, Li Q Q, et al. DeepCrack: learning hierarchical convolutional features for crack detection[J]. IEEE Transactions on Image Processing, 2019, 28(3): 1498-1512. doi: 10.1109/TIP.2018.2878966
[15] Mei Q P, Gül M, Azim M R, et al. Densely connected deep neural network considering connectivity of pixels for automatic crack detection[J]. Automation in Construction, 2020, 110: 103018. doi: 10.1016/j.autcon.2019.103018
[16] Fei Y, Wang K C P, Zhang A, et al. Pixel-level cracking detection on 3D asphalt pavement images through deep-learning-based CrackNet-V[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21(1): 273-284. doi: 10.1109/TITS.2019.2891167
[17] Zhang A, Wang K C P, Li B X, et al. Automated pixel-level pavement crack detection on 3D asphalt surfaces using a deep-learning network[J]. Computer-Aided Civil and Infrastructure Engineering, 2017, 32(10): 805-819. doi: 10.1111/mice.12297
[18] Ronneberger O, Fischer P, Brox T, et al. U-Net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 2015: 234-241.
[19] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]//International Conference on Learning Representations, 2015.
[20] Badrinarayanan V, Kendall A, Cipolla R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495. doi: 10.1109/TPAMI.2016.2644615
[21] Yu F, Koltun V. Multi-scale context aggregation by dilated convolutions[C]//International Conference on Learning Representations, 2016.
[22] Chen L C, Papandreou G, Kokkinos I, et al. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. doi: 10.1109/TPAMI.2017.2699184
[23] Wang P Q, Chen P F, Yuan Y, et al. Understanding convolution for semantic segmentation[C]//2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 2018: 1451-1460.
[24] Yang M K, Yu K, Zhang C, et al. DenseASPP for semantic segmentation in street scenes[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 2018: 3684-3692.
[25] Luo W J, Li Y J, Urtasun R, et al. Understanding the effective receptive field in deep convolutional neural networks[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems, 2016: 4905-4913.
[26] Xie S, Tu Z. Holistically-Nested Edge Detection[J]. International Journal of Computer Vision, 2015, 125(1-3): 3-18. doi: 10.1007/s11263-017-1004-z
[27] Zou Q, Cao Y, Li Q Q, et al. CrackTree: Automatic crack detection from pavement images[J]. Pattern Recognition Letters, 2012, 33(3): 227-238. doi: 10.1016/j.patrec.2011.11.004
[28] Kingma D P, Ba L J. Adam: A method for stochastic optimization[C]//International Conference on Learning Representations, Ithaca, NY, 2015.
[29] Chaurasia A, Culurciello E. LinkNet: Exploiting encoder representations for efficient semantic segmentation[C]//2007 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 2017: 1-4.
[30] Zhang Z X, Liu Q J, Wang Y H. Road extraction by deep residual U-Net[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15(5): 749-753. doi: 10.1109/LGRS.2018.2802944
[31] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016: 770-778.
-
 点击扫一扫
点击扫一扫
图(8)
表(4)
计量
- 文章访问数: 6138
- PDF下载数: 1505
- 施引文献: 0


