
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Sun R, Shan X Q, Sun Q J, et al. NIR-VIS face image translation method with dual contrastive learning framework[J]. Opto-Electron Eng, 2022, 49(4): 210317. doi: 10.12086/oee.2022.210317

|
NIR-VIS face image translation method with dual contrastive learning framework
-
Abstract
With the wide application of visible-infrared dual-mode cameras in video surveillance, cross-modal face recognition has become a research hotspot in the field of computer vision. The translation of NIR domain face images into VIS domain face images is a key problem in cross-modal face recognition, which has important research value in the fields of criminal investigation and security. Aiming at the problems that facial contours are easily distorted and skin color restoration is unrealistic during the coloring process of NIR face images, this paper proposes a NIR-VIS face images translation method under a dual contrastive learning framework. This method constructs a generator network based on the StyleGAN2 structure and embeds it into the dual contrastive learning framework to exploit the fine-grained characteristics of face images using bidirectional contrastive learning. Meanwhile, a facial edge enhancement loss is designed to further enhance the facial details in the generated face images and improve the visual effects of the face images using the facial edge information extracted from the source domain images. Finally, experiments on the NIR-VIS Sx1 and NIR-VIS Sx2 datasets show that, compared with the recent mainstream methods, the VIS face images generated by this method are closer to the real images and possesses more facial edge details and skin color information of the face images. -

-
References
[1] Dutta A K. Imaging beyond human vision[C]//2014 8th International Conference on Electrical and Computer Engineering (ICECE), 2014: 224–229. [2] Cao Z C, Schmid N A, Bourlai T. Composite multilobe descriptors for cross-spectral recognition of full and partial face[J]. Opt Eng, 2016, 55(8): 083107. doi: 10.1117/1.OE.55.8.083107 [3] Sun Y, Wang X G, Tang X O. Deep learning face representation from predicting 10, 000 classes[C]//IEEE Conference on Computer Vision & Pattern Recognition, 2014: 1891–1898. [4] He R, Wu X, Sun Z N, et al. Wasserstein CNN: learning invariant features for NIR-VIS face recognition[J]. IEEE Trans Pattern Anal Mach Intell, 2019, 41(7): 1761−1773. doi: 10.1109/TPAMI.2018.2842770 [5] Hu S W, Short N, Riggan B S, et al. Heterogeneous face recognition: recent advances in infrared-to-visible matching[C]//2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), 2017: 883–890. [6] Mori A, Wada T. Part based regression with dimensionality reduction for colorizing monochrome face images[C]//2013 2nd IAPR Asian Conference on Pattern Recognition, 2013: 506–510. [7] Cheng Z Z, Yang Q X, Sheng B. Deep colorization[C]//Proceedings of the IEEE International Conference on Computer Vision, 2015: 415–423. [8] Limmer M, Lensch H P A. Infrared colorization using deep convolutional neural networks[C]//2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), 2016: 61–68. [9] Larsson G, Maire M, Shakhnarovich G. Learning representations for automatic colorization[C]//14th European Conference on Computer Vision, 2016: 577–593. [10] Limmer M, Lensch H P A. Improved IR-colorization using adversarial training and estuary networks[C]//British Machine Vision Conference, 2017. [11] Suárez P L, Sappa A D, Vintimilla B X, et al. Near InfraRed imagery colorization[C]//Proceedings of 2018 25th IEEE International Conference on Image Processing (ICIP), 2018: 2237–2241. [12] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems, 2014, 2: 2672–2680. [13] Liu M Y, Breuel T, Kautz J. Unsupervised image-to-image translation networks[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 700–708. [14] Huang X, Liu M Y, Belongie S, et al. Multimodal unsupervised image-to-image translation[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 179–196. [15] Isola P, Zhu J Y, Zhou T H, et al. Image-to-image translation with conditional adversarial networks[C]//IEEE Conference on Computer Vision & Pattern Recognition, 2017: 5967–5976. [16] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015: 234–241. [17] Wang T C, Liu M Y, Zhu J Y, et al. High-resolution image synthesis and semantic manipulation with conditional GANs[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018: 8798–8807. [18] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017: 2242–2251. [19] Wang H J, Zhang H J, Yu L, et al. Facial feature embedded Cyclegan for Vis-Nir translation[C]//ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020: 1903–1907. [20] Dou H, Chen C, Hu X Y, et al. Asymmetric cyclegan for unpaired NIR-to-RGB face image translation[C]//ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019: 1757–1761. [21] Babu K K, Dubey S R. CSGAN: cyclic-synthesized generative adversarial networks for image-to-image transformation[J]. Expert Syst Appl, 2021, 169: 114431. doi: 10.1016/j.eswa.2020.114431 [22] Babu K K, Dubey S R. CDGAN: cyclic discriminative generative adversarial networks for image-to-image transformation[J]. J Vis Commun Image Represen, 2022, 82: 103382. doi: 10.1016/j.jvcir.2021.103382 [23] Park T, Efros A A, Zhang R, et al. Contrastive learning for unpaired image-to-image translation[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 319–345. [24] Han J L, Shoeiby M, Petersson L, et al. Dual contrastive learning for unsupervised image-to-image translation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2021: 746–755. [25] Karras T, Laine S, Aittala M, et al. Analyzing and improving the image quality of StyleGAN[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020: 8107–8116. [26] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 770–778. [27] Gao W S, Zhang X G, Yang L, et al. An improved Sobel edge detection[C]//Proceedings of the 3rd IEEE International Conference on Computer Science & Information Technology, 2010: 67–71. [28] Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 4396–4405. [29] Li S Z, Yi D, Lei Z, et al. The CASIA NIR-VIS 2.0 face database[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2013: 348–353. [30] Sheikh H R, Sabir M F, Bovik A C. A statistical evaluation of recent full reference image quality assessment algorithms[J]. IEEE Trans Image Process, 2006, 15(11): 3440−3451. doi: 10.1109/TIP.2006.881959 [31] Ma J Y, Yu W, Liang P W, et al. FusionGAN: a generative adversarial network for infrared and visible image fusion[J]. Inf Fusion, 2019, 48: 11−26. doi: 10.1016/j.inffus.2018.09.004 [32] Heusel M, Ramsauer H, Unterthiner T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 6629–6640. -
Overview
Near-infrared image sensors are widely used because they can overcome the effects of natural light and work in various lighting conditions. In the field of criminal security, NIR face images are usually not directly used for face retrieval and recognition because the single-channel images acquired by NIR sensors miss the natural colors of the original images. Therefore, converting NIR face images into VIS face images and restoring the color information of face images can help further improve the subjective visual effect and cross-modal recognition performance of face images, and provide technical support for building a 24/7 video surveillance system. However, NIR face images are different from other NIR images. If the details of face contours and facial skin tones are distorted in the coloring process, the visual effect and image quality of the generated face images will be greatly affected. Therefore, it is necessary to design algorithms to enhance the retention of detailed information in the coloring process of NIR face images. We propose a NIR-VIS face image translation method under a dual contrastive learning framework. The method is based on the dual contrastive learning network and uses contrastive learning to enhance the quality of the images generated from the image localization. Meanwhile, since the StyleGAN2 network can extract deeper features of face images compared with ResNets, we construct a generator network based on the StyleGAN2 structure and embed it into the dual contrastive learning network to replace the original ResNets generator to further improve the quality of the generated face images. In addition, for the characteristics of blurred external contours and missing edges of human figures in NIR domain images, a facial edge enhancement loss is designed in this paper to further enhance the facial details of the generated face images by using the facial edge information extracted from the source domain images. Experiments show that the generation results on two public datasets based on our method are significantly better than those of recent mainstream methods. The VIS face images generated by our method are closer to the real images and possesses more facial edge details and skin tone information of face images.
-
Access History
Figures(9)
Tables(5)
Article Metrics


Export File
Citation
Sun R, Shan X Q, Sun Q J, et al. NIR-VIS face image translation method with dual contrastive learning framework[J]. Opto-Electron Eng, 2022, 49(4): 210317. doi: 10.12086/oee.2022.210317
Format
Content
 DownLoad:
DownLoad:






-
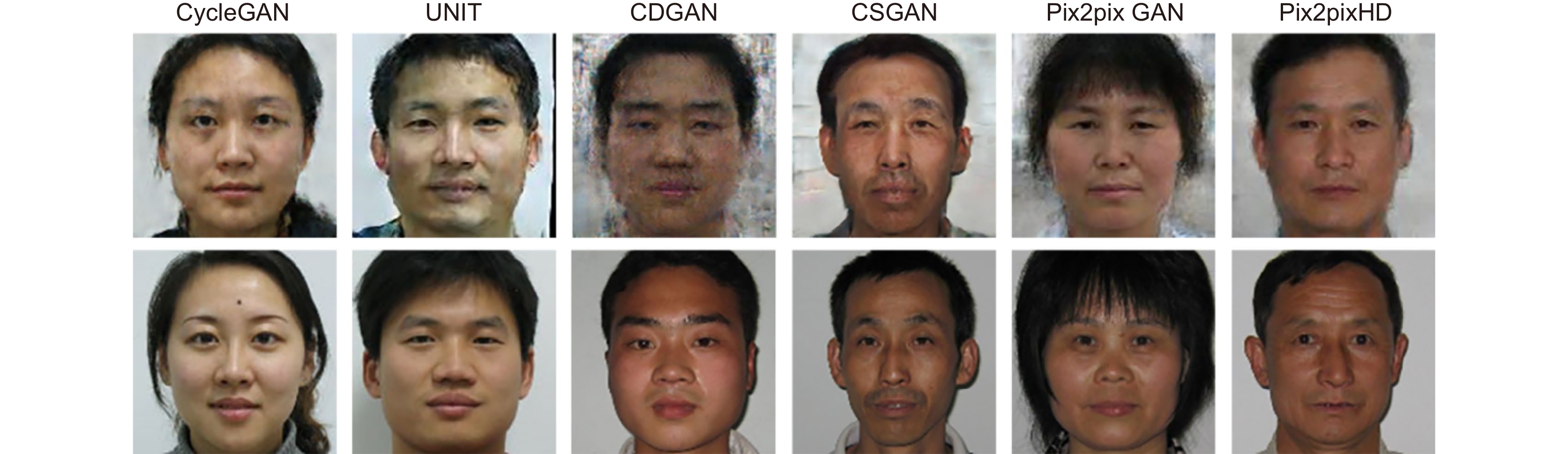
Figure 1.
Comparison of the VIS image (the first row) generated by some algorithms from NIR domain with the real visible image (the last row)
-
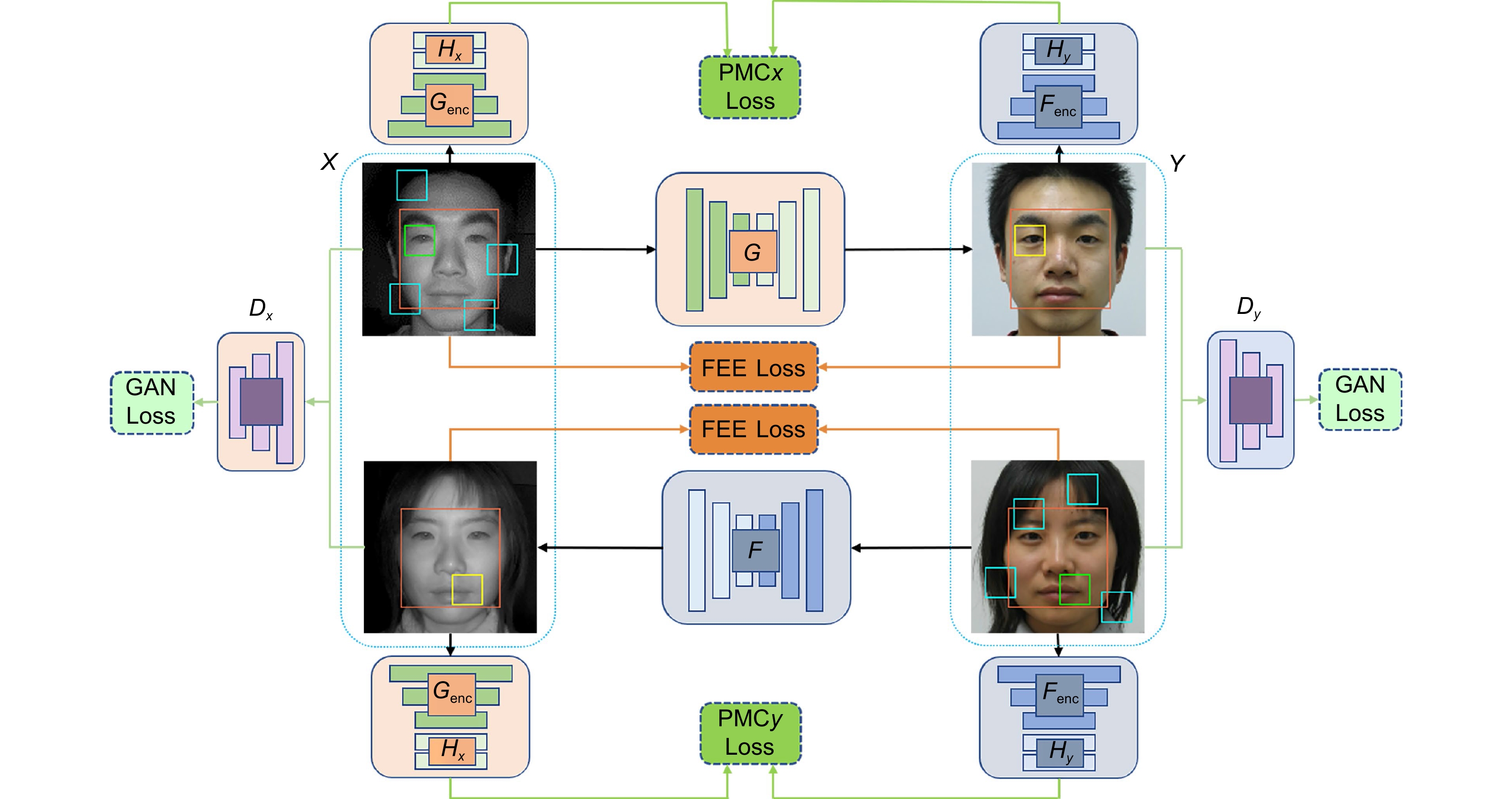
Figure 2.
The structure diagram of the proposed method.
-
Figure 3.
The structure diagram of generator in the proposed method
-
Figure 4.
Crop out facial regions and extract edges from face images in NIR and VIS conditions respectively
-
Figure 5.
The comparison experimental results on two datasets.
-
Figure 6.
Results of the ablation experiments on two datasets.
-
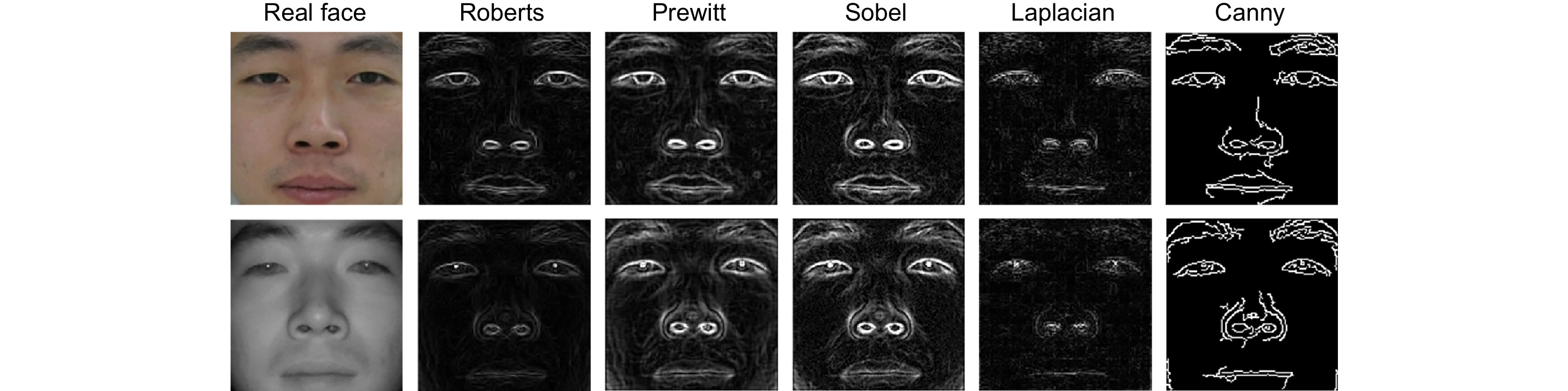
Figure 7.
Comparison of edge images obtained by using each edge extraction method separately.
-
Figure 8.
The effect of different values of
${\lambda _{{\rm{FEE}}}}$ - Figure .


