
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Ji Y N, Li H F, Liu X. Image segmentation learning method for large field single lens computational imaging system[J]. Opto-Electron Eng, 2022, 49(5): 210371. doi: 10.12086/oee.2022.210371

|
Image segmentation learning method for large field single lens computational imaging system
-
Abstract
In order to improve the final image quality of a large field single-lens computational imaging system, and to make its output more suitable for human eyes to see, a feasible image training method is proposed in this paper. First, a image was divided into two parts, including the center and edge areas, according to the field of view. In order to avoid leaving segmentation traces after splicing, we adopted a segmentation method that can leave a Gaussian boundary. Then the two parts were put into two datasets respectively. After that, the two datasets were respectively fed into the neural network for training. After training, the test image was divided into the center and edge areas using the same method, and were fed into their own neural networks. Finally, the results of the two networks would be joined together into a complete image to get the final result. After subjective perception and objective index evaluation, the image obtained by using the new idea in this paper has a significant improvement in quality and a better visual perception compared with the image obtained by direct training. Therefore, the improvement and optimization of the large field of view single-lens computational imaging system is successfully realized, and the output images of the system become more suitable for human eyes.-
Keywords:
- computational imaging /
- image segmentation /
- image restoration
-

-
References
[1] Mait J N, Euliss G W, Athale R A. Computational imaging[J]. Adv Opt Photonics, 2018, 10(2): 409−483. doi: 10.1364/AOP.10.000409 [2] 刘严严, 杜玉萍. 计算成像的研究现状与发展趋势[J]. 光电技术应用, 2019, 34(5): 21−24. doi: 10.3969/j.issn.1673-1255.2019.05.004 Liu Y Y, Du Y P. Research status and development trend of computational imaging[J]. Electro-Opt Technol Appl, 2019, 34(5): 21−24. doi: 10.3969/j.issn.1673-1255.2019.05.004 [3] Sitzmann V, Diamond S, Peng Y F, et al. End-to-end optimization of optics and image processing for achromatic extended depth of field and super-resolution imaging[J]. ACM Trans Graph, 2018, 37(4): 114. [4] Haim H, Elmalem S, Giryes R, et al. Depth estimation from a single image using deep learned phase coded mask[J]. IEEE Trans Comput Imaging, 2018, 4(3): 298−310. doi: 10.1109/TCI.2018.2849326 [5] Chang J, Wetzstein G. Deep optics for monocular depth estimation and 3D object detection[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 10192–10201. [6] Wu Y C, Boominathan V, Chen H, et al. PhaseCam3D — learning phase masks for passive single view depth estimation[C]//Proceedings of 2019 IEEE International Conference on Computational Photography, 2019: 1–2. [7] Chang J L, Sitzmann V, Dun X, et al. Hybrid optical-electronic convolutional neural networks with optimized diffractive optics for image classification[J]. Sci Rep, 2018, 8(1): 12324. doi: 10.1038/s41598-018-30619-y [8] 邱锡鹏. 神经网络与深度学习[M]. 北京: 机械工业出版社, 2020. Qiu X P. Neural Networks and Deep Learning[M]. Beijing: China Machine Press, 2020. [9] Goodfellow I J, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems, 2014: 2672–2680. [10] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015: 234–241. [11] Zhang J W, Pan J S, Lai W S, et al. Learning fully convolutional networks for iterative non-blind deconvolution[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6969–6977. [12] Sinha A, Lee J, Li S, et al. Lensless computational imaging through deep learning[J]. Optica, 2017, 4(9): 1117−1125. doi: 10.1364/OPTICA.4.001117 [13] Kupyn O, Budzan V, Mykhailych M, et al. DeblurGAN: blind motion deblurring using conditional adversarial networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8183–8192. [14] Huang Y T, Peng Y T, Liao W H. Enhancing object detection in the dark using U-Net based restoration module[C]//Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance, 2019: 1-9. [15] Jung H M, Kim B H, Min Y K. Residual forward-subtracted U-shaped network for dynamic and static image restoration[J]. IEEE Access, 2020, 8: 145401−145412. doi: 10.1109/ACCESS.2020.3011580 [16] Jin X, Hu Y, Zhang C Y. Image restoration method based on GAN and multi-scale feature fusion[C]//Proceedings of 2020 Chinese Control and Decision Conference, 2020: 2305–2310. [17] Li Y P, Nie X L, Diao W H, et al. Lifelong CycleGAN for continual multi-task image restoration[J]. Pattern Recogn Lett, 2022, 153: 183−189. doi: 10.1016/j.patrec.2021.12.010 [18] Peng Y F, Sun Q L, Dun X, et al. Learned large field-of-view imaging with thin-plate optics[J]. ACM Trans Graph, 2019, 38(6): 219. [19] 邹运. 模糊图像清晰化的技术研究[D]. 大庆: 东北石油大学, 2014: 1–70. Zou Y. Technology research of blurred image clarity[D]. Daqing: Northeast Petroleum University, 2014: 1–70. [20] Zhou W, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE Trans Image Process, 2004, 13(4): 600−612. doi: 10.1109/TIP.2003.819861 -
Overview
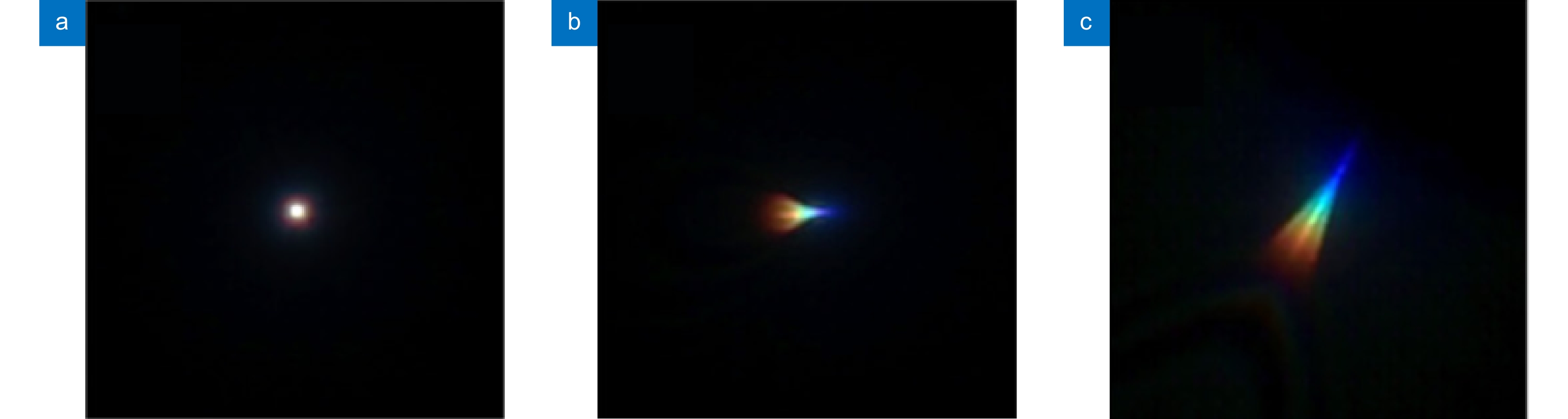
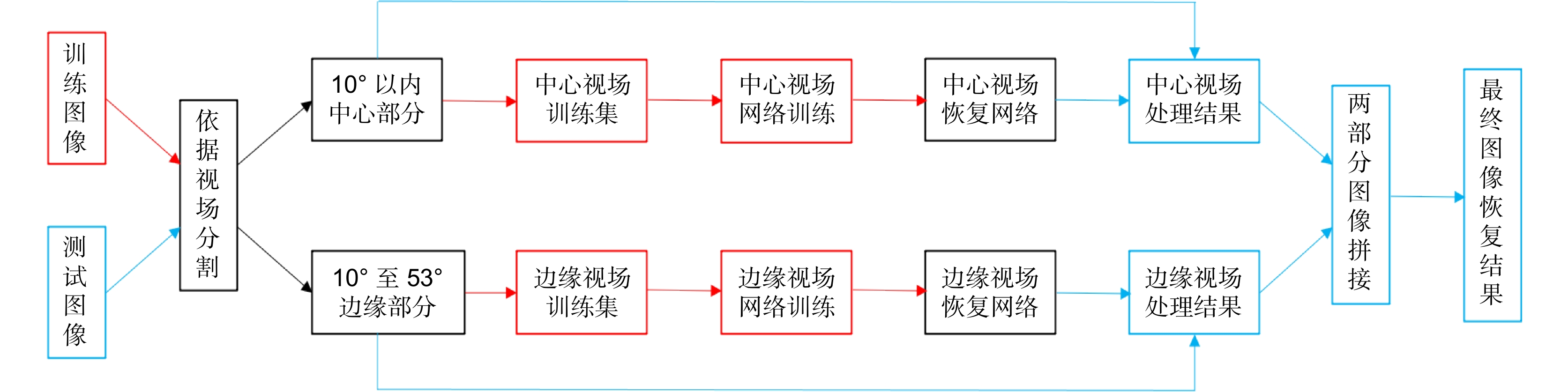
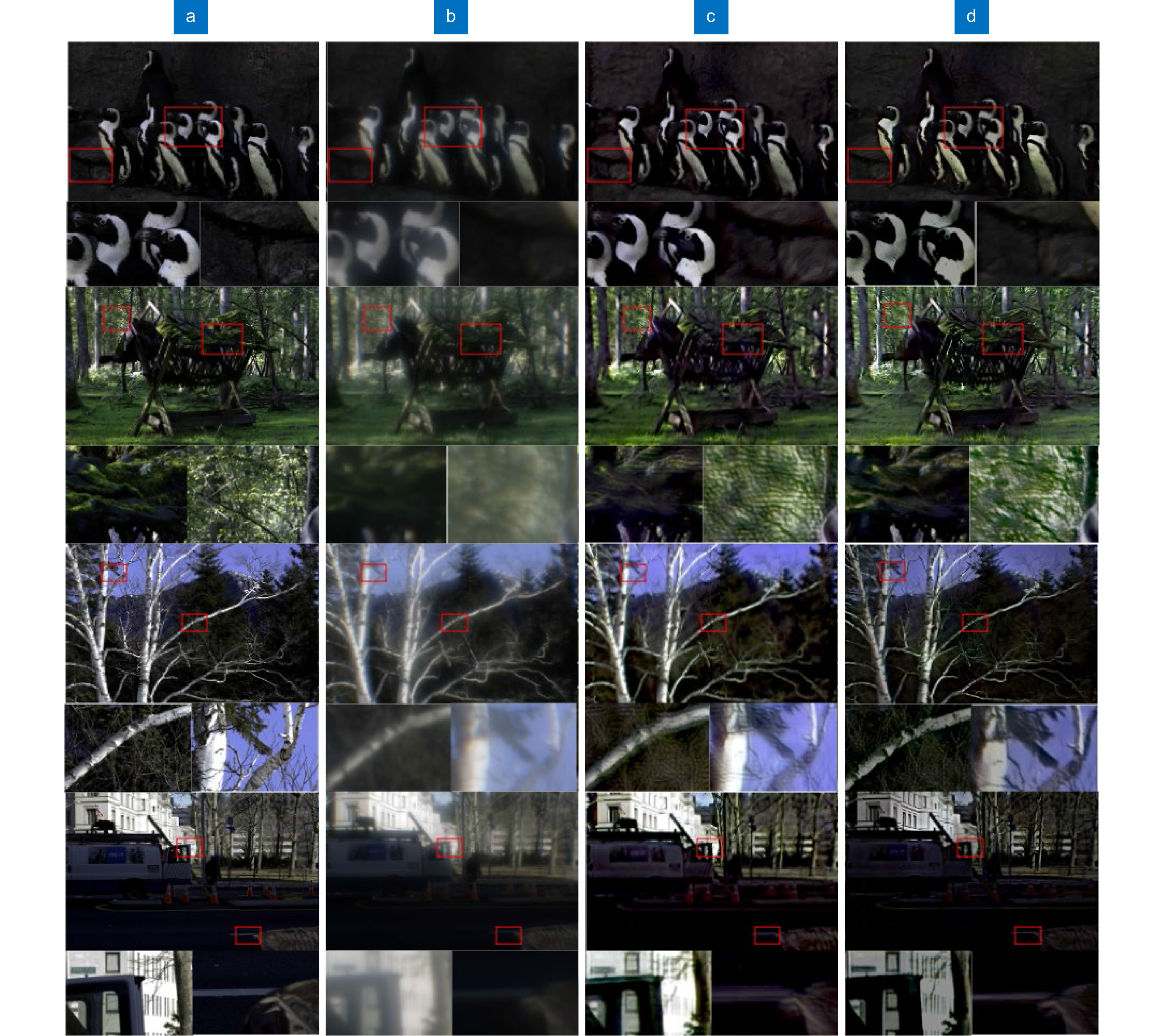
This paper presents an improved and optimized scheme for a large field of view single lens computational imaging system. In 2018, Peng Y F et al. proposed a single-lens computational imaging system with large field of view. This system solved the problem that the field of view of a single-lens computational imaging system could only be limited to 10 degrees. However, we noticed that after adopting the mixed PSF method of Peng Y F et al., the PSF learned by the network was not actually the accurate PSF of the image. This PSF error would have a bad effect on the final network output, resulting in the degradation of the quality of the restored network image. In order to solve the above-mentioned problem and make the imaging results of wide-field single-lens computational imaging system have better quality for human eyes to see, we proposed a processing method for wide-field PSF and its corresponding image training idea. Firstly, we divided the image into two parts, including the center and edge areas, according to the field of view. The center part corresponds to the field of view within 10 degrees, and the edge part corresponds to the field of view between 10 degrees and 53 degrees. In order to avoid segmentation traces after splicing, we adopted a segmentation method that can leave a gaussian gradient boundary. Then, the segmented images were made into two training sets, which were put into different networks for training. Under this situation, the PSF after the network training would be closer to the real PSF in the picture, which would greatly reduce the influence of PSF error, so that the quality of network training results would be better. After the training, the image to be restored was divided into two parts by the same method, and then the two parts of the image were restored in the corresponding neural network respectively. Finally, the output results of the two networks were spliced into a complete image to obtain the final result. For the same group of different pictures, we used the idea proposed by Peng Y F et al. and our new idea to restore and compared the results of the two methods. From the subjective perception of human eyes, the pictures obtained by using our new idea are more natural, clearer, and better than those obtained by using the methods of Peng Y F and others. In terms of objective evaluation indicators, our method is comparable to the method of Peng Y F et al. in terms of PSNR value. In terms of SSIM value, our method is much better than that of the Peng Y F et al. Therefore, in general, our idea does improve and optimize the large field of view single lens computational imaging system, and makes its imaging results higher quality and more suitable for human eyes.
-
Access History
Figures(9)
Tables(2)
Article Metrics


Export File
Citation
Ji Y N, Li H F, Liu X. Image segmentation learning method for large field single lens computational imaging system[J]. Opto-Electron Eng, 2022, 49(5): 210371. doi: 10.12086/oee.2022.210371
Format
Content
 DownLoad:
DownLoad:






-
Figure 1.
Amplification of PSF with different fields of view[18].
-
Figure 2.
The concrete implementation process of the new idea
-
Figure 3.
Overall hardware system (sensors in the red box)
-
Figure 4.
Image shooting and registration process
-
Figure 5.
Sample of center partial dataset (shot image on the left, original image on the right)
-
Figure 6.
Sample of edge partial dataset (shot image on the left, original image on the right). The reasons for leaving holes in the middle are detailed in the following article
-
Figure 7.
Sample of test set after restoration, with two details highlighted in red boxes are listed below each image.
-
Figure 8.
Sample of real pictures after restoration, with a detail selected in a red box is listed above or below each image.
- Figure .


