
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Wang R G, Lei H, Yang J, et al. Self-similarity enhancement network for image super-resolution[J]. Opto-Electron Eng, 2022, 49(5): 210382. doi: 10.12086/oee.2022.210382

|
Self-similarity enhancement network for image super-resolution
-
Abstract
Deep convolutional neural networks (DCNN) recently demonstrated high-quality restoration in the single image super-resolution (SISR). However, most of the existing image super-resolution methods only consider making full use of the inherent static characteristics of the training sets, ignoring the internal self-similarity of low-resolution images. In this paper, a self-similarity enhancement network (SSEN) is proposed to address above-mentioned problems. Specifically, we embedded the deformable convolution into the pyramid structure and combined it with the cross-level co-attention to design a module that can fully mine multi-level self-similarity, namely the cross-level feature enhancement module. In addition, we introduce a pooling attention mechanism into the stacked residual dense blocks, which uses a strip pooling to expand the receptive field of the convolutional neural network and establish remote dependencies within the deep features, so that the patches with high similarity in deep features can complement each other. Extensive experiments on five benchmark datasets have shown that the SSEN has a significant improvement in reconstruction effect compared with the existing methods.-
Keywords:
- super-resolution /
- self-similarity /
- feature enhancement /
- deformable convolution /
- attention /
- strip pooling
-

-
References
[1] Zhang L, Wu X L. An edge-guided image interpolation algorithm via directional filtering and data fusion[J]. IEEE Trans Image Process, 2006, 15(8): 2226−2238. doi: 10.1109/TIP.2006.877407 [2] Li X Y, He H J, Wang R X, et al. Single image superresolution via directional group sparsity and directional features[J]. IEEE Trans Image Process, 2015, 24(9): 2874−2888. doi: 10.1109/TIP.2015.2432713 [3] Zhang K B, Gao X B, Tao D C, et al. Single image super-resolution with non-local means and steering kernel regression[J]. IEEE Trans Image Process, 2012, 21(11): 4544−4556. doi: 10.1109/TIP.2012.2208977 [4] 徐亮, 符冉迪, 金炜, 等. 基于多尺度特征损失函数的图像超分辨率重建[J]. 光电工程, 2019, 46(11): 180419. Xu L, Fu R D, Jin W, et al. Image super-resolution reconstruction based on multi-scale feature loss function[J]. Opto-Electron Eng, 2019, 46(11): 180419. [5] Huang J B, Singh A, Ahuja N. Single image super-resolution from transformed self-exemplars[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 5197–5206. [6] 沈明玉, 俞鹏飞, 汪荣贵, 等. 多路径递归网络结构的单帧图像超分辨率重建[J]. 光电工程, 2019, 46(11): 180489. Shen M Y, Yu P F, Wang R G, et al. Image super-resolution via multi-path recursive convolutional network[J]. Opto-Electron Eng, 2019, 46(11): 180489. [7] Dong C, Loy C C, He K M, et al. Learning a deep convolutional network for image super-resolution[C]//Proceedings of the 13th European Conference on Computer Vision, 2014: 184–199. [8] Kim J, Lee J K, Lee K M. Accurate image super-resolution using very deep convolutional networks[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 1646–1654. [9] Hui Z, Gao X B, Yang Y C, et al. Lightweight image super-resolution with information multi-distillation network[C]//Proceedings of the 27th ACM International Conference on Multimedia, 2019: 2024–2032. [10] Liu S T, Huang D, Wang Y H. Receptive field block net for accurate and fast object detection[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 404–419. [11] Dai T, Cai J R, Zhang Y B, et al. Second-order attention network for single image super-resolution[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 11057–11066. [12] Mei Y Q, Fan Y C, Zhou Y Q, et al. Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 5689–5698. [13] Jaderberg M, Simonyan K, Zisserman A, et al. Spatial transformer networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 2017–2025. [14] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. [15] Zhang Y L, Li K P, Li K, et al. Image super-resolution using very deep residual channel attention networks[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 294–310. [16] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 3–19. [17] Sun K, Zhao Y, Jiang B R, et al. High-resolution representations for labeling pixels and regions[Z]. arXiv: 1904.04514, 2019. https://arxiv.org/abs/1904.04514. [18] Newell A, Yang K Y, Deng J. Stacked hourglass networks for human pose estimation[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 483–499. [19] Ke T W, Maire M, Yu S X. Multigrid neural architectures[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 4067–4075. [20] Chen Y P, Fan H Q, Xu B, et al. Drop an octave: reducing spatial redundancy in convolutional neural networks with octave convolution[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 3434–3443. [21] Han W, Chang S Y, Liu D, et al. Image super-resolution via dual-state recurrent networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 1654–1663. [22] Li J C, Fang F M, Mei K F, et al. Multi-scale residual network for image super-resolution[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), 2018: 527–542. [23] Yang Y, Zhang D Y, Huang S Y, et al. Multilevel and multiscale network for single-image super-resolution[J]. IEEE Signal Process Lett, 2019, 26(12): 1877−1881. doi: 10.1109/LSP.2019.2952047 [24] Feng R C, Guan W P, Qiao Y, et al. Exploring multi-scale feature propagation and communication for image super resolution[Z]. arXiv: 2008.00239, 2020. https://arxiv.org/abs/2008.00239v2. [25] Dai JF, Qi H Z, Xiong Y W, et al. Deformable convolutional networks[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 764–773. [26] Zhu X Z, Hu H, Lin S, et al. Deformable ConvNets V2: more deformable, better results[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 9300–9308. [27] Wang X T, Yu K, Wu S X, et al. ESRGAN: enhanced super-resolution generative adversarial networks[C]//Proceedings of 2018 European Conference on Computer Vision, 2018: 63–79. [28] Hou Q B, Zhang L, Cheng M M, et al. Strip pooling: rethinking spatial pooling for scene parsing[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 4002–4011. [29] Agustsson E, Timofte R. NTIRE 2017 challenge on single image super-resolution: dataset and study[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017: 1122–1131. [30] Bevilacqua M, Roumy A, Guillemot C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding[C]//Proceedings of the British Machine Vision Conference, 2012. [31] Zeyde R, Elad M, Protter M. On single image scale-up using sparse-representations[C]//Proceedings of the 7th International Conference on Curves and Surfaces, 2010: 711–730. [32] Martin D, Fowlkes C, Tal D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Proceedings Eighth IEEE International Conference on Computer Vision, 2001: 416–423. [33] Matsui Y, Ito K, Aramaki Y, et al. Sketch-based manga retrieval using manga109 dataset[J]. Multimed Tools Appl, 2017, 76(20): 21811−21838. doi: 10.1007/s11042-016-4020-z [34] Lai W S, Huang J B, Ahuja N, et al. Deep laplacian pyramid networks for fast and accurate super-resolution[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5835–5843. [35] Liu Y Q, Zhang X F, Wang S S, et al. Progressive multi-scale residual network for single image super-resolution[Z]. arXiv: 2007.09552, 2020. https://arxiv.org/abs/2007.09552v3. [36] Zhang Y L, Tian Y P, Kong Y, et al. Residual dense network for image super-resolution[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 2472–2481. [37] He X Y, Mo Z T, Wang P S, et al. ODE-inspired network design for single image super-resolution[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 1732–1741. [38] Haris M, Shakhnarovich G, Ukita N. Deep back-projection networks for super-resolution[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 1664–1673. [39] Lim B, Son S, Kim H, et al. Enhanced deep residual networks for single image super-resolution[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017: 1132–1140. -
Overview
Single image super-resolution can not only be directly used in practical applications, but also benefits other tasks of computer vision, such as object detection and semantic segmentation. Single image super-resolution, with the goal of reconstructing an accurate high-resolution (HR) image from its observed low-resolution (LR) image counterpart, is a representative branch of image reconstruction tasks in the field of computer vision. Dong et al. firstly introduced a three-layer convolutional neural network to learn the mapping function between the bicubic-interpolated and HR image pairs, demonstrating the substantial performance improvements compared to those of conventional algorithms. Therefore, a series of single image super-resolution algorithms based on deep learning have been proposed. Although a great progress has been made in image super-resolution methods, existing convolutional neural network-based super-resolution models still have some limitations. First, most CNN-based super-resolution methods focus on designing deeper or wider networks to learn more advanced features of discriminability, but fail to make full use of the internal self-similarity information of the low-resolution images. In response to this problem, SAN introduced non-local networks and CS-NL proposed cross-scale non-local. Although these methods can take the advantage of self-similarity, they still need to consume a huge amount of memory to calculate the large relational matrix of each spatial location. Second, most methods do not make reasonable use of multi-level self-similarity. Even if some methods consider the importance of multi-level self-similarity, they do not have a good method to fuse them, so as to achieve a good image reconstruction effect.
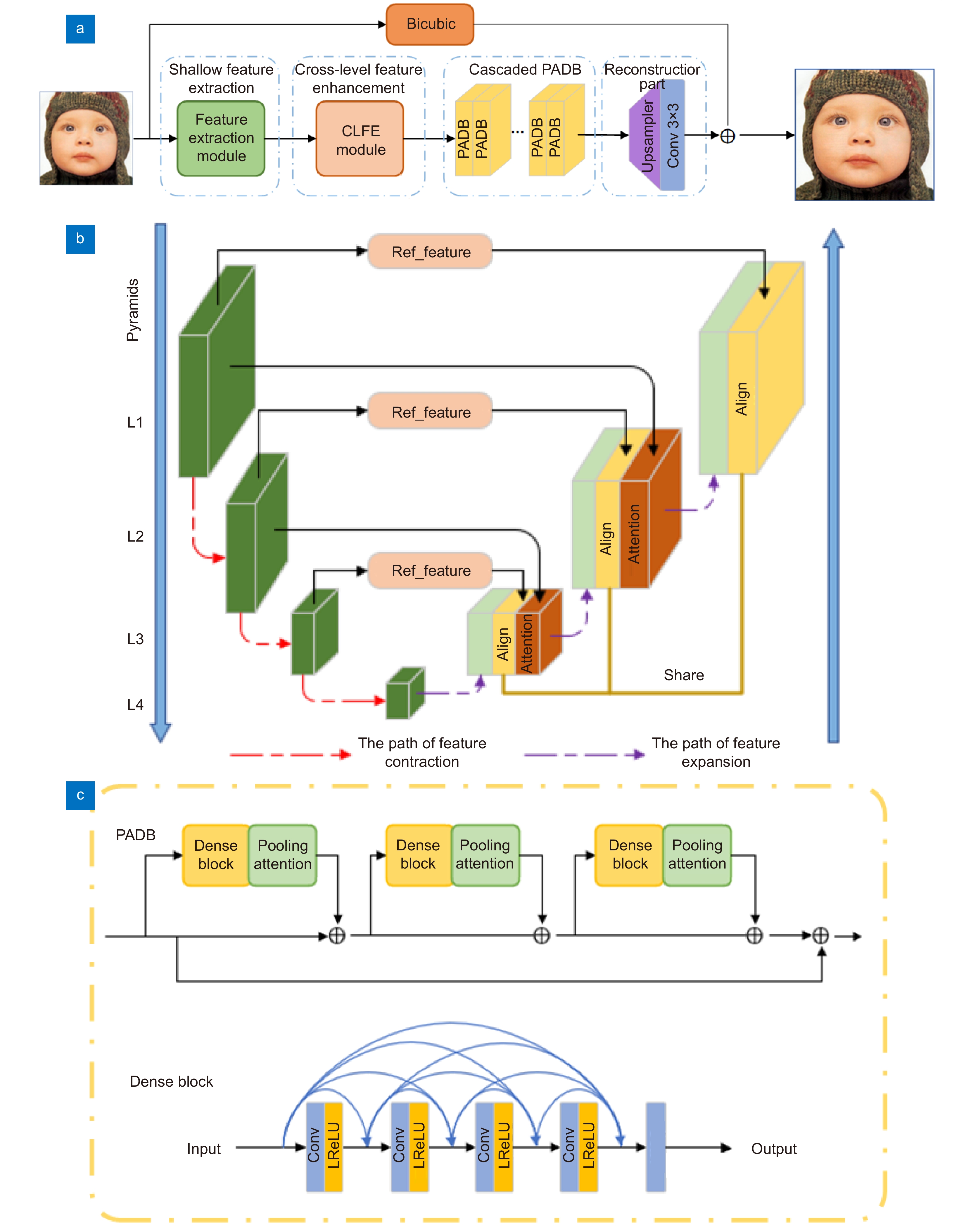
To solve these problems, we propose a self-similarity enhancement network (SSEN). We embedded deformable convolution into the pyramid structure to mine multi-level self-similarity in the low-resolution images, and then introduced the cross-level co-attention at each level of the pyramid to fuse them. Finally, the pooling attention mechanism was utilized to further explore the self-similarity in deep features. Compared with other models, our network mainly has the following differences. First, our network searches self-similarity using an offset estimator of deformable convolution. At the same time, we use the cross-level co-attention to enhance the ability of cross-level feature transmission in the feature pyramid structure. Second, most models capture global correlation by calculating pixel correlation through non-local networks. However, the pooled attention mechanism is used in our network to adaptively capture remote dependencies with low computational cost, which enhances the deep features of self-similarity, thus significantly improving the reconstruction effect. Extensive experiments on five benchmark datasets have shown that the SSEN has a significant improvement in reconstruction effect compared with the existing methods.
-
Access History
Figures(12)
Tables(3)
Article Metrics


Export File
Citation
Wang R G, Lei H, Yang J, et al. Self-similarity enhancement network for image super-resolution[J]. Opto-Electron Eng, 2022, 49(5): 210382. doi: 10.12086/oee.2022.210382
Format
Content
 DownLoad:
DownLoad:





-
Figure 1.
Basic architectures.
-
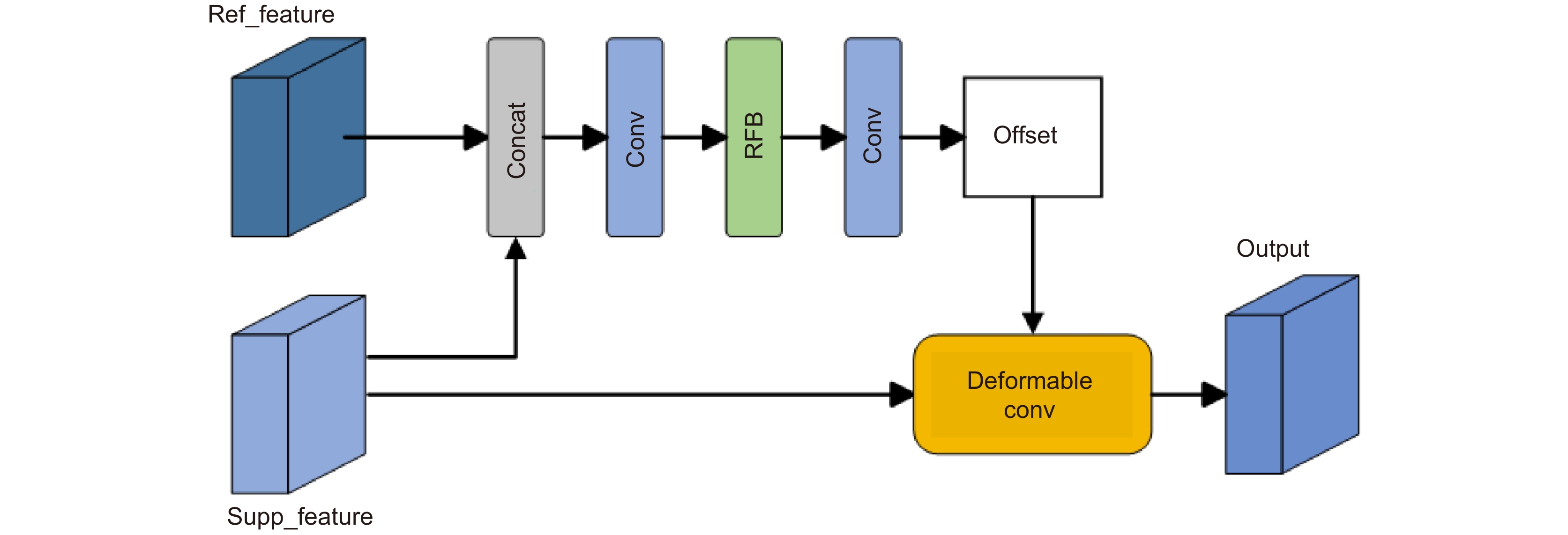
Figure 2.
The proposed feature enhancement module
-
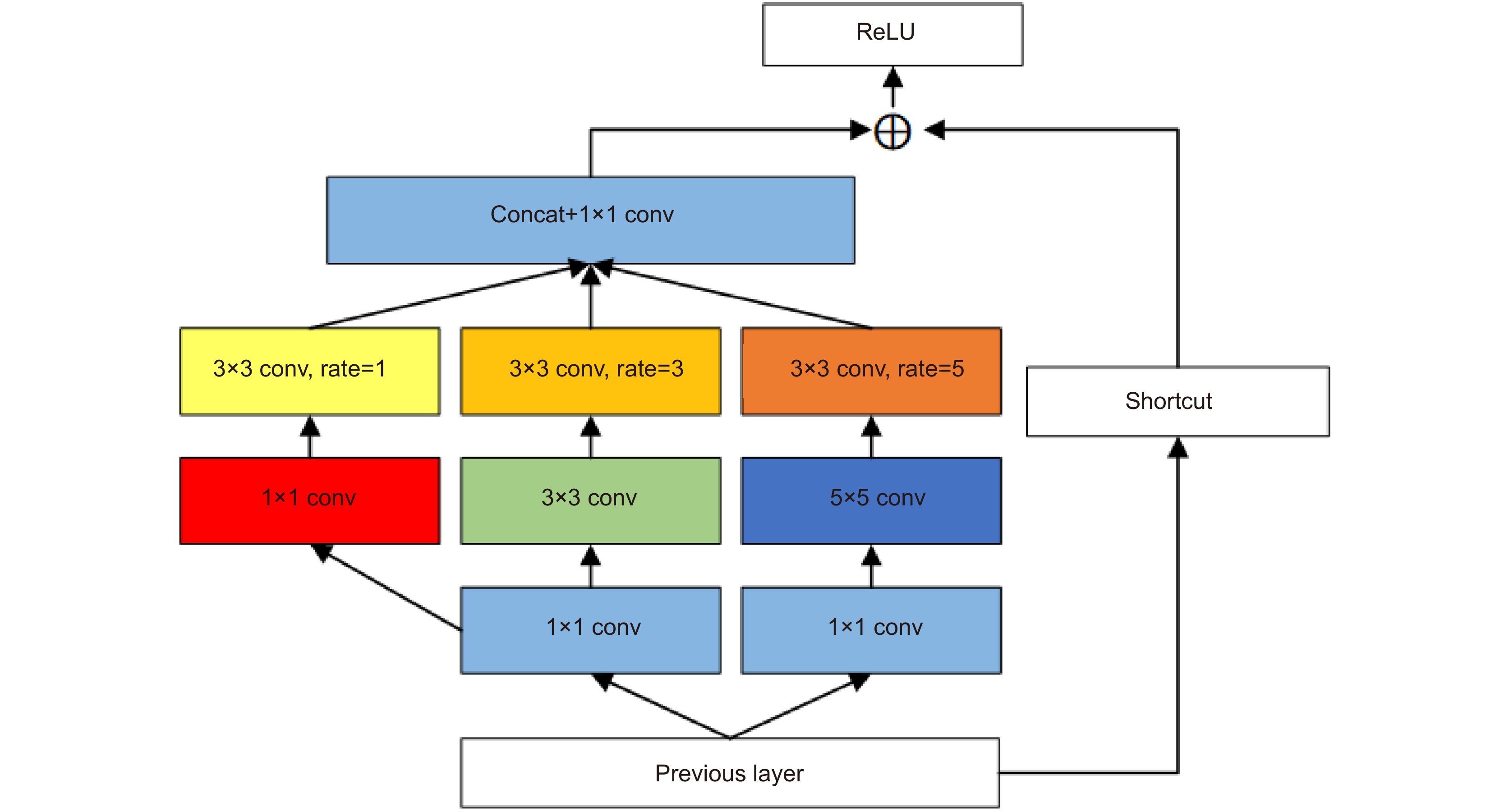
Figure 3.
Receptive field block
-
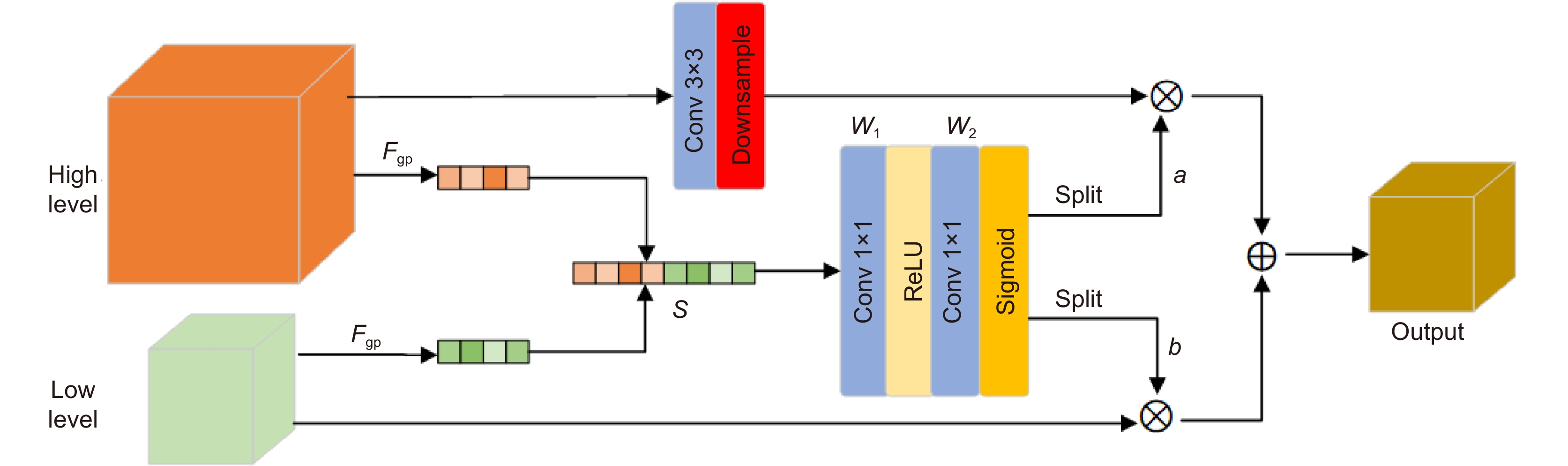
Figure 4.
The proposed Cross-Level Co-Attention architec-ture. "Fgp" denotes the global average pooling
-
Figure 5.
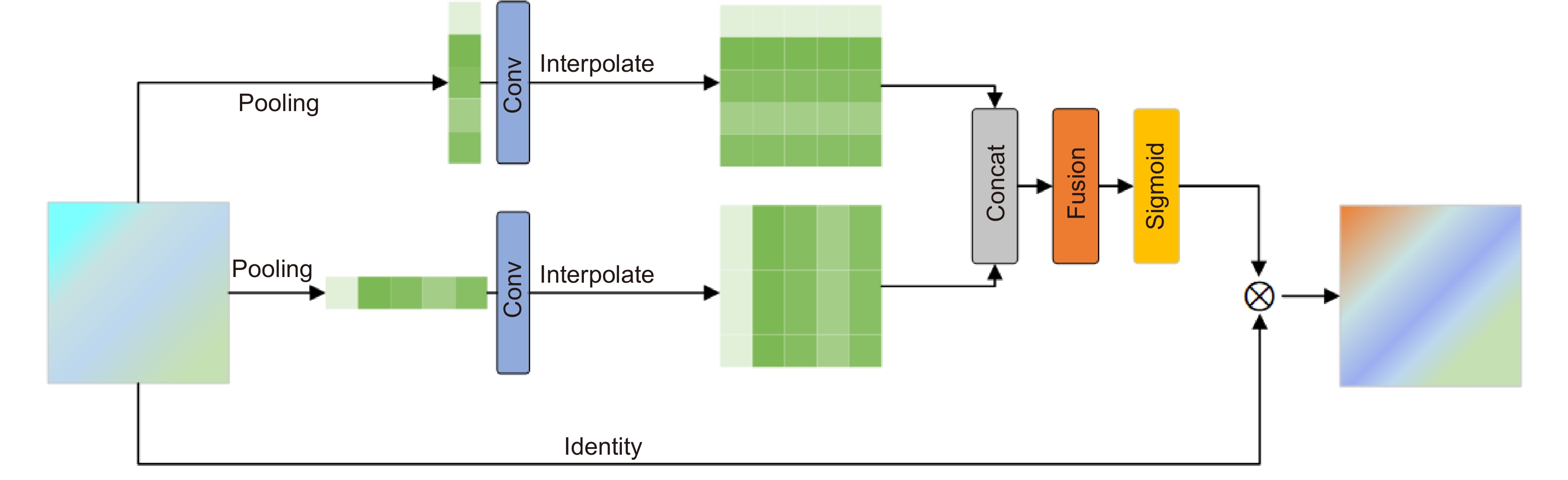
Schematic illustration of the pooling attention
-
Figure 6.
Super-resolution results of " Img048" in Urban100 dataset for 4× magnification
-
Figure 7.
Super-resolution results of " Img092" in Urban100 dataset for 4× magnification
-
Figure 8.
Super-resolution results of "
223061 " in BSD100 dataset for 4× magnification -
Figure 9.
Super-resolution results of "
253027 " in BSD100 dataset for 4× magnification -
Figure 10.
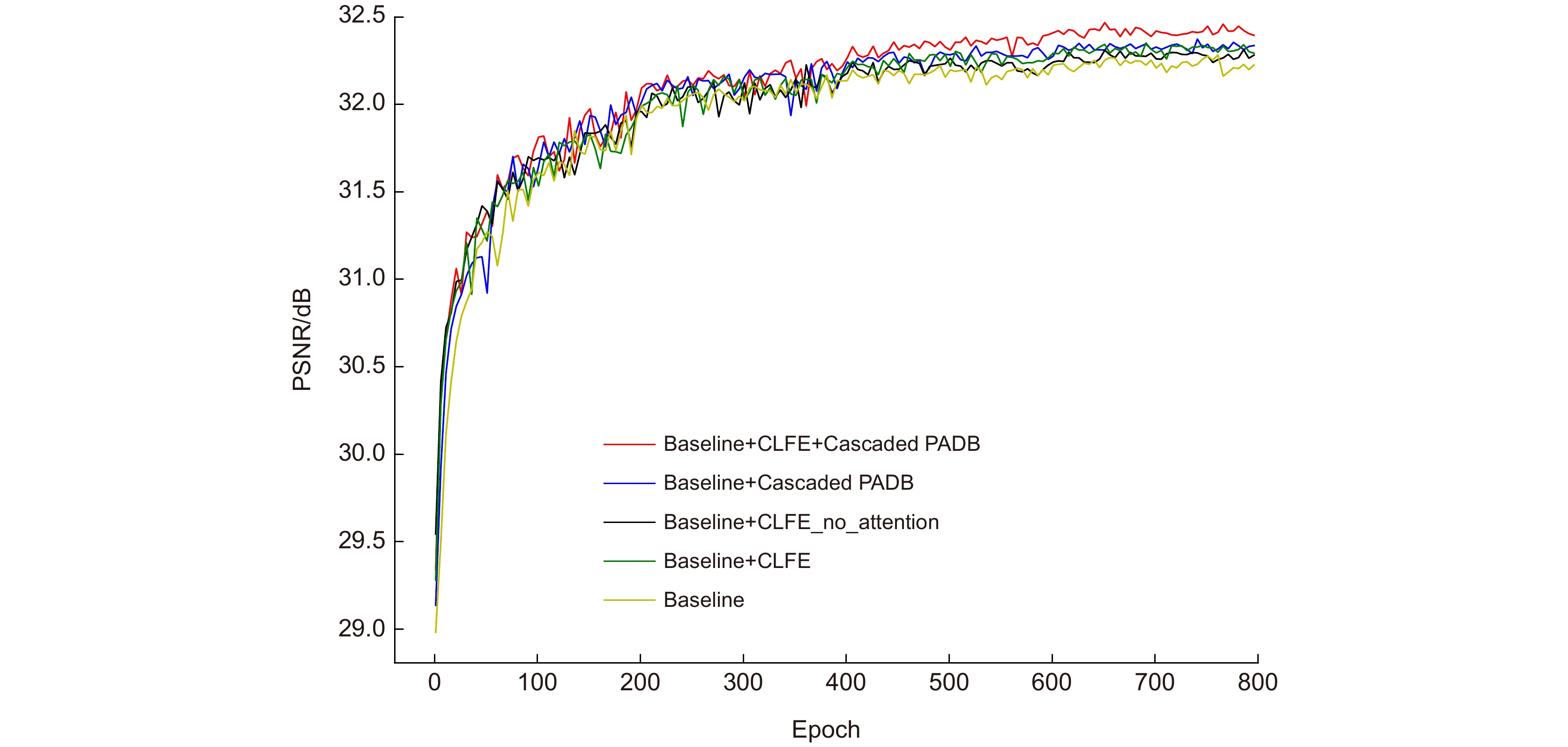
Convergence analysis on CLFE and PADB. The curves for each combination are based on the PSNR on Set5 with scaling factor 4× in 800 epochs.
-
Figure 11.
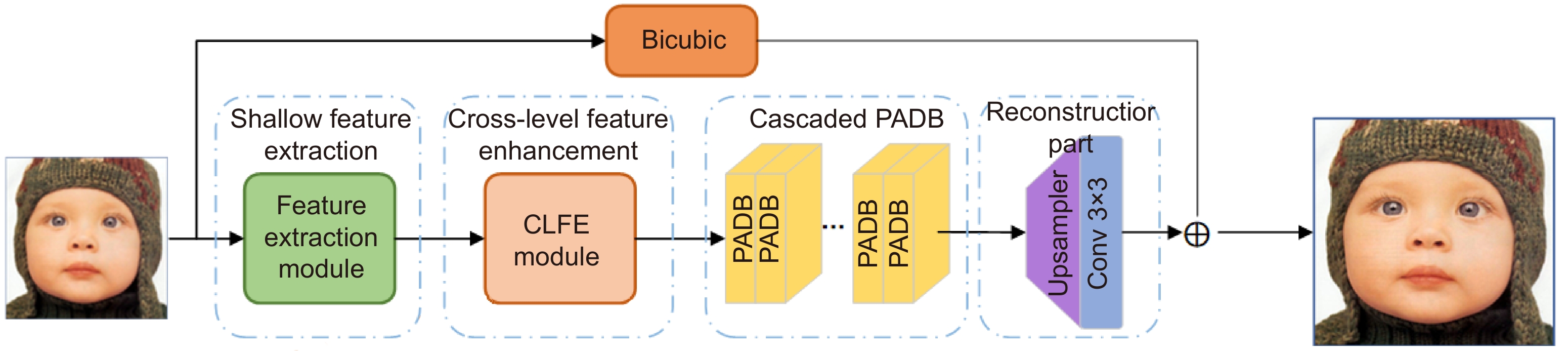
Results of each module in the network.
- Figure .


