
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Xue L X, Yin K J, Wang R G, et al. Interactive instance proposal network for HOI detection[J]. Opto-Electron Eng, 2022, 49(7): 210429. doi: 10.12086/oee.2022.210429

|
Interactive instance proposal network for HOI detection
-
Abstract
Human-object interaction detection is to locate and identify the interactive relationship between humans and objects in an image. The challenge is that the machine cannot know which object the person is interacting in. Most existing methods try to solve this problem by matching humans and objects exactly. Different from them, this paper proposes an interactive instance proposal network based on relational reasoning to adapt to the task. Our main idea is to recommend human-object pairs by using the potential interaction relationships in the visual relationship between humans and objects. In addition, a cross-modal information fusion module is designed to fuse different context information according to its influence on the detection result, so as to improve the detection accuracy. To evaluate the proposed method, we performed sufficient experiments on two large-scale datasets: HICO-DET and V-COCO. Results show that our method achieves 19.90% and 50.3% mAP on HICO-DET and V-COCO, which are 4.5% and 2.8% higher than our baseline, respectively.-
Keywords:
- Human-object interaction detection /
- action detection /
- attention /
- GNNs /
- image understanding
-

-
References
[1] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91–99. [2] Girshick R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision, 2015: 1440–1448. [3] Yang C Y, Xu Y H, Shi J P, et al. Temporal pyramid network for action recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 588–597. [4] Li M S, Chen S H, Chen X, et al. Actional-structural graph convolutional networks for skeleton-based action recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 3590–3598. [5] Kirillov A, He K M, Girshick R, et al. Panoptic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 9396–9405. [6] Sofiiuk K, Sofiyuk K, Barinova O, et al. AdaptIS: adaptive instance selection network[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 7354–7362. [7] Gao C, Xu J R, Zou Y L, et al. DRG: dual relation graph for human-object interaction detection[C]//16th European Conference on Computer Vision, 2020: 696–712. [8] Gao C, Zou Y L, Huang J B. iCAN: instance-centric attention network for human-object interaction detection[C]//British Machine Vision Conference 2018, 2018. [9] Chao Y W, Liu Y F, Liu X Y, et al. Learning to detect human-object interactions[C]//2018 IEEE Winter Conference on Applications of Computer Vision (WACV), 2018: 381–389. [10] Hou Z, Peng X J, Qiao Y, et al. Visual compositional learning for human-object interaction detection[C]//16th European Conference on Computer Vision, 2020: 584–600. [11] Zhou P H, Chi M M. Relation parsing neural network for human-object interaction detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 843–851. [12] Kim B, Lee J, Kang J, et al. HOTR: end-to-end human-object interaction detection with transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 74–83. [13] Zhang A X, Liao Y, Liu S, et al. Mining the benefits of two-stage and one-stage HOI detection[C]//Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems, 2021. [14] Zou C, Wang B H, Hu Y, et al. End-to-end human object interaction detection with HOI transformer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 11820–11829. [15] Chen M F, Liao Y, Liu S, et al. Reformulating HOI detection as adaptive set prediction[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 9000–9009. [16] Kamath A, Clark C, Gupta T, et al. Webly supervised concept expansion for general purpose vision models[Z]. arXiv: 2202.02317, 2022. https://arxiv.org/abs/2202.02317v1. [17] Li Z M, Zou C, Zhao Y, et al. Improving human-object interaction detection via phrase learning and label composition[Z]. arXiv: 2112.07383, 2021. https://doi.org/10.48550/arXiv.2112.07383. [18] Xue L X, Jiang D, Wang R G, et al. Learning semantic dependencies with channel correlation for multi-label classification[J]. Vis Comput, 2020, 36(7): 1325−1335. doi: 10.1007/s00371-019-01731-5 [19] Li Y L, Zhou S Y, Huang X J, et al. Transferable interactiveness knowledge for human-object interaction detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 3580–3589. [20] Yang J W, Lu J S, Lee S, et al. Graph R-CNN for scene graph generation[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), 2018: 690–706. [21] Chen T S, Yu W H, Chen R Q, et al. Knowledge-embedded routing network for scene graph generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 6156–6164. [22] Yang J, Sun X, Wang R G, et al. PTPGC: pedestrian trajectory prediction by graph attention network with ConvLSTM[J]. Robot Auton Syst, 2022, 148: 103931. doi: 10.1016/j.robot.2021.103931 [23] Liang W X, Jiang Y H, Liu Z X. GraghVQA: language-guided graph neural networks for graph-based visual question answering[Z]. arXiv: 2104.10283, 2021. https://arxiv.org/abs/2104.10283v2. [24] Qi S Y, Wang W G, Jia B X, et al. Learning human-object interactions by graph parsing neural networks[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), 2018: 407–423. [25] Xu B J, Wong Y K, Li J N, et al. Learning to detect human-object interactions with knowledge[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 2019–2028. [26] Zheng S P, Chen S Z, Jin Q. Skeleton-based interactive graph network for human object interaction detection[C]//2020 IEEE International Conference on Multimedia and Expo (ICME), 2020: 1–6. [27] Shen L Y, Yeung S, Hoffman J, et al. Scaling human-object interaction recognition through zero-shot learning[C]//2018 IEEE Winter Conference on Applications of Computer Vision (WACV), 2018: 1568–1576. [28] Wang S C, Yap K H, Yuan J S, et al. Discovering human interactions with novel objects via zero-shot learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 11649–11658. [29] Fang H S, Xie Y C, Shao D, et al. DecAug: augmenting HOI detection via decomposition[C]//Proceedings of the 35th AAAI Conference on Artificial Intelligence, 2021: 1300–1308. [30] Sarullo A, Mu T T. Zero-shot human-object interaction recognition via affordance graphs[Z]. arXiv: 2009.01039, 2020. https://doi.org/10.48550/arXiv.2009.01039. [31] Wan B, Zhou D S, Liu Y F, et al. Pose-aware multi-level feature network for human object interaction detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 9468–9477. [32] Peyre J, Sivic J, Laptev I, et al. Detecting unseen visual relations using analogies[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019: 1981–1990. [33] Liu Y, Chen Q C, Zisserman A. Amplifying key cues for human-object-interaction detection[C]//16th European Conference on Computer Vision, 2020: 248–265. [34] Zhang F Z, Campbell D, Gould S. Spatio-attentive graphs for human-object interaction detection[Z]. arXiv: 2012.06060, 2020. https://arxiv.org/abs/2012.06060v1. [35] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936–944. [36] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770–778. [37] Chen L, Zhang H W, Xiao J, et al. Zero-shot visual recognition using semantics-preserving adversarial embedding networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 1043–1052. [38] Pennington J, Socher R, Manning C D. GloVe: global vectors for word representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014: 1532–1543. [39] Gupta S, Malik J. Visual semantic role labeling[Z]. arXiv: 1505.04474, 2015. https://arxiv.org/abs/1505.04474v1. [40] Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: common objects in context[C]//13th European Conference on Computer Vision, 2014: 740–755. -
Overview
With the development of computer vision, people increasingly need to understand images, including recognizing the scenes and the human behaviors in images. The task of HOI detection is to locate humans and objects in images and infer their relationships. This requires not only locating a single object instance, but also identifying the interaction between the objects. However, machines cannot know which object humans are interacts in. Most of the existing methods solve this problem by completely pairing the people and objects. They use off-the-shelf object detectors to detect instances, but this does not meet the requirements of the HOI task. This paper proposes an object detector suitable for HOI detection based on relational reasoning, which makes use of the interactive relationship between humans and objects in the images to recommend human-object pairs, so as to reduce the occurrence of non-interactive human-object pairs as much as possible. Our method follows the two-stage detection like most works. Firstly, the interactive instance proposal network (IIPN) is used to recommend human-object pairs. The IIPN follows the pipeline of faster RCNN, but replaces the region proposal network (RPN) with the IIPN. The IIPN selects human-object pairs based on the interaction possibility between humans and objects using the visual information in the picture. It passes the message through the iterative reasoning of the graph neural networks (GNNS), only human-object pairs that include interactive relationships are selected as the IIPN’s outputs. Secondly, we design a cross-modal information fusion module (CIFM), which calculates the fusion attention according to the influence of different features on the detection results, and performs weighted fusion. This is because the existing methods simply add or splice several features such as human visual features, object visual features, and human-object spatial features in the reasoning part. The different influence degrees of various features in different actions are ignored. For example, the verbs like ride and hold in < human, ride bike> and < human, hold, bike > depend more on the spatial relationships, while eat and cut in <human, eat, pizza> and <human, cut, pizza> depend more on human's postures, that is, visual features. Meanwhile, this paper believes that semantic prior knowledge is also helpful to HOI detection. For example, if we have apples in an image, the probability of predicting the human's action as eating or holding is greater than others. Finally, complete experiments are performed on two popular large-scale HOI datasets, HICO-DET and V-COCO. The experimental results show the effectiveness of the proposed method.
-
Access History

Figures(8)
Tables(6)
Article Metrics


Export File
Citation
Xue L X, Yin K J, Wang R G, et al. Interactive instance proposal network for HOI detection[J]. Opto-Electron Eng, 2022, 49(7): 210429. doi: 10.12086/oee.2022.210429
Format
Content
 DownLoad:
DownLoad:




-
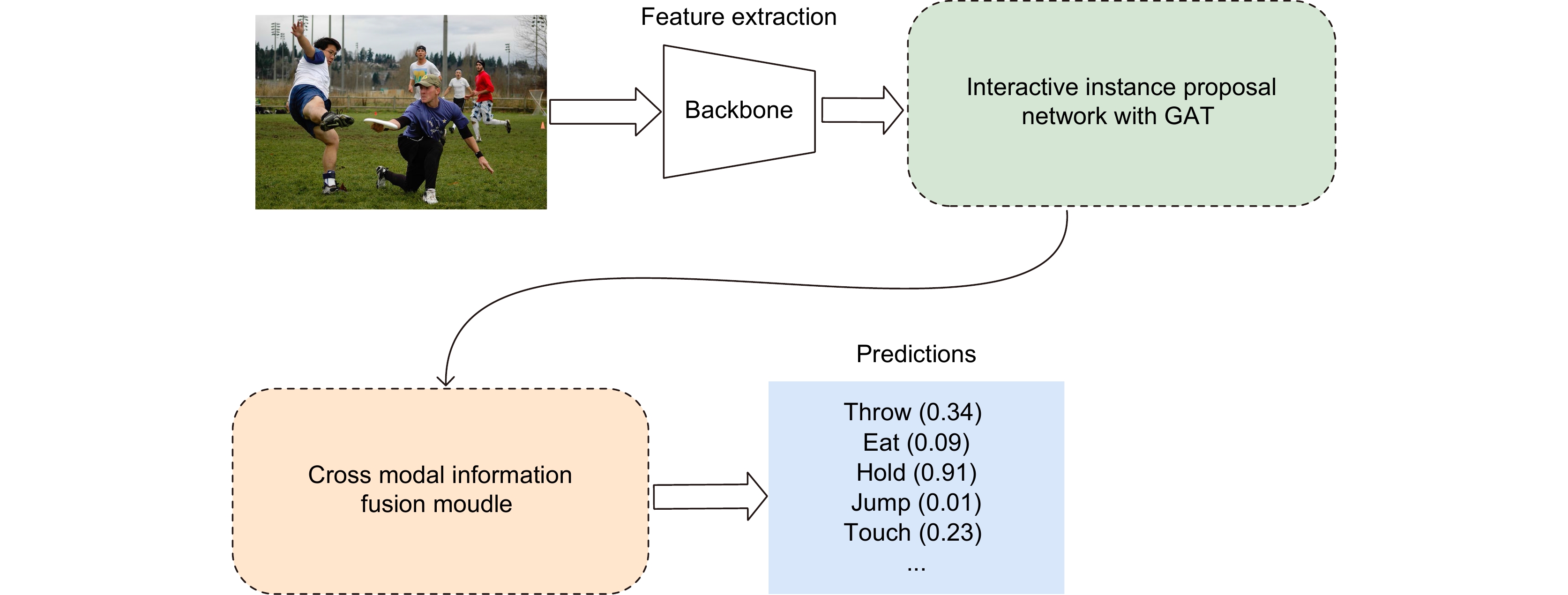
Figure 1.
Pipeline of human object interaction detection
-
Figure 2.
Overview of human object interaction detection based on interactive instance proposal network
-
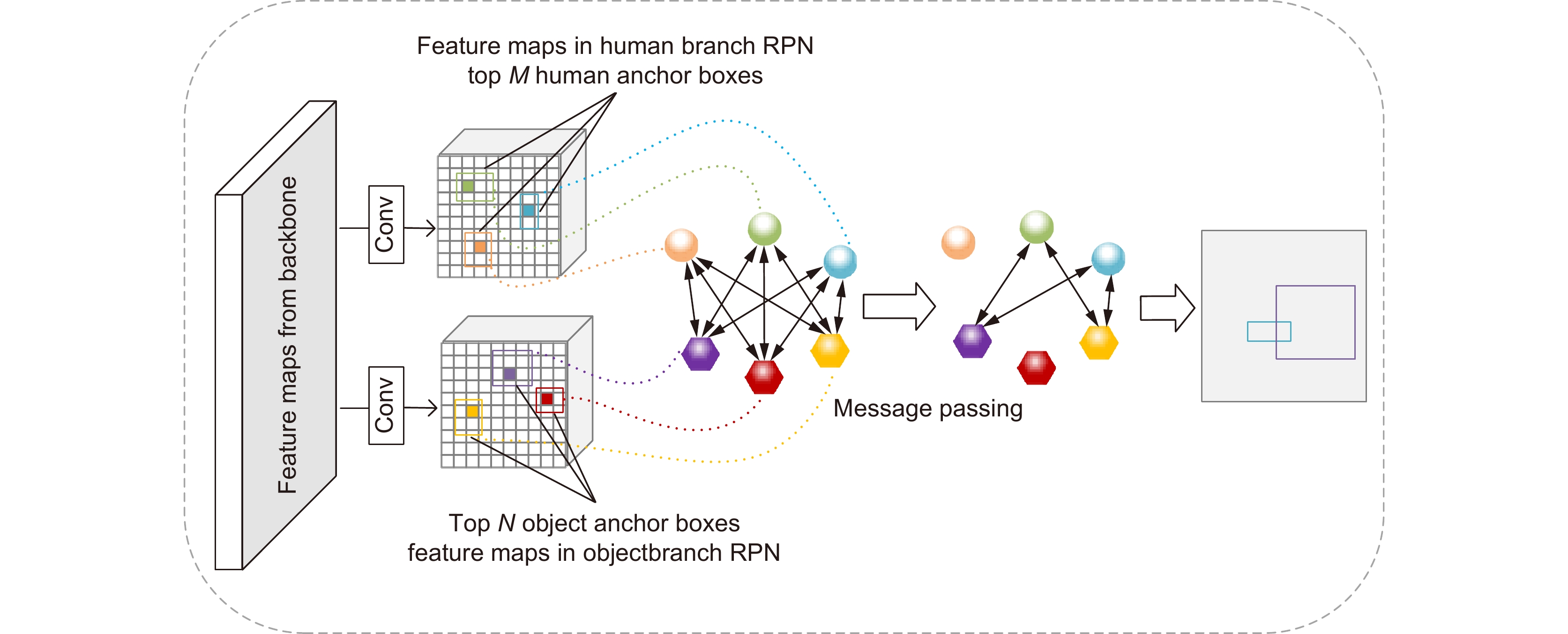
Figure 3.
Interactive instance proposal network
-
Figure 4.
Structure of cross-modal information fusion module
-
Figure 5.
Comparison of IIPN (bottom row) with Faster-RCNN (upper row)
-
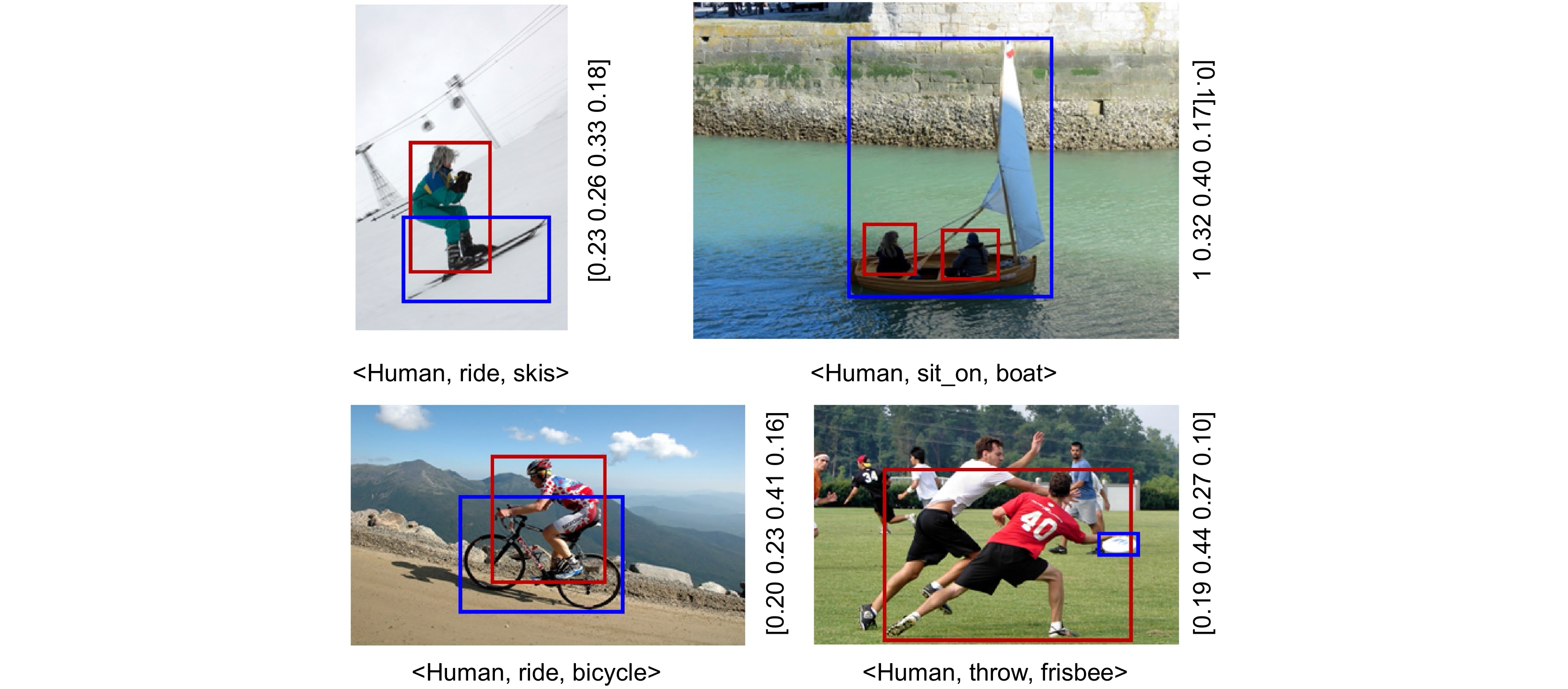
Figure 6.
Visualization of detection results on HICO-DET
-
Figure 7.
Visualization of fusion attention
- Figure .


