
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Luan Q L, Chang X Y, Wu Y, et al. PAW-YOLOv7: algorithm for detection of tiny floating objects in river channels[J]. Opto-Electron Eng, 2024, 51(4): 240025. doi: 10.12086/oee.2024.240025

|
PAW-YOLOv7: algorithm for detection of tiny floating objects in river channels
-
Abstract
Detection of floating debris in rivers is of great significance for ship autopilot and river cleaning, but the existing methods in targeting floating objects in the river with small target sizes and mutual occlusion, and less feature information lead to low detection accuracy. To address these problems, this paper proposes a small target object detection method called PAW-YOLOv7 based on YOLOv7. Firstly, in order to improve the feature expression ability of the small target network model, a small target object detection layer is constructed, and the self-attention and convolution hybrid module (ACmix) is integrated and applied to the newly constructed small target detection layer. Secondly, in order to reduce the interference of the complex background, the Omni-dimensional dynamic convolution (ODConv) is used instead of the convolution module in the neck, so as to give the network the ability to capture the global contextual information. Finally, the PConv (partial convolution) module is integrated into the backbone network to replace part of the standard convolution, while the WIoU (Wise-IoU) loss function is used to replace the CIoU. It achieves the reduction of network model computation, improves the network detection speed, and increases the focusing ability on the low-quality anchor frames, accelerating the convergence speed of the model. The experimental results show that the detection accuracy of the PAW-YOLOv7 algorithm on the FloW-Img dataset improved by the data extension technique in this paper reaches 89.7%, which is 9.8% higher than that of the original YOLOv7, the detection speed reaches 54 frames per second (FPS), and the detection accuracy on the self-built sparse floater dataset improves by 3.7% compared with that of YOLOv7. It is capable of detecting the tiny floating objects in the river channel quickly and accurately, and also has a better real-time detection performance. -

-
References
[1] Yan L, Yamaguchi M, Noro N, et al. A novel two-stage deep learning-based small-object detection using hyperspectral images[J]. Opt Rev, 2019, 26(6): 597−606. doi: 10.1007/s10043-019-00528-0 [2] 朱豪, 周顺勇, 刘学, 等. 基于深度学习的单阶段目标检测算法综述[J]. 工业控制计算机, 2023, 36(4): 101−103. Zhu H, Zhou S Y, Liu X, et al. Survey of single-stage object detection algorithms based on deep learning[J]. Ind Control Comput, 2023, 36(4): 101−103. [3] Girshick R. Fast R-CNN[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision, 2015: 1440–1448. https://doi.org/10.1109/ICCV.2015.169. [4] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Trans Patt Anal Mach Intellig, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031 [5] Liu W, Anguelov D, Erhan D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the 14th European Conference on Computer Vision, 2016: 21–37. https://doi.org/10.1007/978-3-319-46448-0_2. [6] Redmon J, Farhadi A. YOLOv3: An incremental improvement[Z]. arXiv: 1804.02767, 2018. https://doi.org/10.48550/arXiv.1804.02767. [7] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: optimal speed and accuracy of object detection[Z]. arXiv: 2004.10934, 2020. https://doi.org/10.48550/arXiv.2004.10934. [8] Zhu X K, Lyu S C, Wang X, et al. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops, 2021: 2778–2788. https://doi.org/10.1109/ICCVW54120.2021.00312. [9] 马梁, 苟于涛, 雷涛, 等. 基于多尺度特征融合的遥感图像小目标检测[J]. 光电工程, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363 Ma L, Gou Y T, Lei T, et al. Small object detection based on multi-scale feature fusion using remote sensing images[J]. Opto-Electron Eng, 2022, 49(4): 210363. doi: 10.12086/oee.2022.210363 [10] Zhang Y, Sun Y P, Wang Z, et al. YOLOv7-RAR for urban vehicle detection[J]. Sensors, 2023, 23(4): 1801. doi: 10.3390/s23041801 [11] 陈旭, 彭冬亮, 谷雨. 基于改进YOLOv5s的无人机图像实时目标检测[J]. 光电工程, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372 Chen X, Peng D L, Gu Y. Real-time object detection for UAV images based on improved YOLOv5s[J]. Opto-Electron Eng, 2022, 49(3): 210372. doi: 10.12086/oee.2022.210372 [12] 陆康亮, 薛俊, 陶重犇. 融合空间掩膜预测与点云投影的多目标跟踪[J]. 光电工程, 2022, 49(9): 220024. doi: 10.12086/oee.2022.220024 Lu K L, Xue J, Tao C B. Multi target tracking based on spatial mask prediction and point cloud projection[J]. Opto-Electron Eng, 2022, 49(9): 220024. doi: 10.12086/oee.2022.220024 [13] Xiao Z, Wan F, Lei G B, et al. FL-YOLOv7: a lightweight small object detection algorithm in forest fire detection[J]. Forests, 2023, 14(9): 1812. doi: 10.3390/f14091812 [14] Sun Y, Yi L, Li S, et al. PBA-YOLOv7: an object detection method based on an improved YOLOv7 network[J]. Appl Sci, 2023, 13(18): 10436. doi: 10.3390/app131810436 [15] Pan X R, Ge C J, Lu R, et al. On the integration of self-attention and convolution[C]//Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 805–815. https://doi.org/10.1109/CVPR52688.2022.00089. [16] Li C, Zhou A J, Yao A B. Omni-dimensional dynamic convolution[C]//The Tenth International Conference on Learning Representations, 2022. [17] Chen J R, Kao S H, He H, et al. Run, Don’t walk: chasing higher FLOPS for faster neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 12021–12031. https://doi.org/10.1109/CVPR52729.2023.01157. [18] Tong Z J, Chen Y H, Xu Z W, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism[Z]. arXiv: 2301.10051, 2023. https://doi.org/10.48550/arXiv.2301.10051. [19] Lee Y, Hwang J W, Lee S, et al. An energy and GPU-computation efficient backbone network for real-time object detection[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019: 752–760. https://doi.org/10.1109/CVPRW.2019.00103. [20] Wang C Y, Liao H Y M, Wu Y H, et al. CSPNet: A new backbone that can enhance learning capability of CNN[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2020: 1571–1580. https://doi.org/10.1109/CVPRW50498.2020.00203. [21] Chollet F. Xception: deep learning with depthwise separable convolutions[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 1800–1807. https://doi.org/10.1109/CVPR.2017.195. [22] Han K, Wang Y H, Tian Q, et al. GhostNet: more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020: 1577–1586. https://doi.org/10.1109/CVPR42600.2020.00165. [23] Yang B, Bender G, Le Q V, et al. CondConv: conditionally parameterized convolutions for efficient inference[C]//Proceedings of the 33rd International Conference on Neural Information Processing Systems, 2019: 117. [24] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745. [25] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//15th European Conference on Computer Vision, 2018: 3–19. https://doi.org/10.1007/978-3-030-01234-2_1. [26] Bello I, Zoph B, Le Q, et al. Attention augmented convolutional networks[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 3285–3294. https://doi.org/10.1109/ICCV.2019.00338. [27] Rezatofighi H, Tsoi N, Gwak J, et al. Generalized intersection over union: a metric and a loss for bounding box regression[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019: 658–666. https://doi.org/10.1109/CVPR.2019.00075. [28] Zheng Z H, Wang P, Liu W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]//Thirty-Seventh AAAI Conference on Artificial Intelligence, 2019. https://doi.org/10.1609/aaai.v34i07.6999. [29] Gevorgyan Z. SIoU loss: more powerful learning for bounding box regression[Z]. arXiv: 2205.12740, 2022. https://doi.org/10.48550/arXiv.2205.12740. [30] Cheng Y W, Zhu J N, Jiang M X, et al. FloW: a dataset and benchmark for floating waste detection in inland waters[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, 2021: 10933–10942. https://doi.org/10.1109/ICCV48922.2021.01077. [31] Zhang H Y, Cissé M, Dauphin Y N, et al. mixup: Beyond empirical risk minimization[C]//6th International Conference on Learning Representations, 2017. -
Overview
In recent years, with the continuous development of deep learning technology, target detection has achieved unprecedented results in the field of computer vision and has been applied to a large number of scenarios, such as intelligent driving, rescue activities, and motion data analysis. In many target detection tasks, river float detection is of great significance for automatic ship driving and river cleaning, at present, target detection has a better performance in medium and large target detection, but the accuracy and real-time performance in the face of detection of tiny floats in the river is poor and the model volume is large. Since the detection of tiny floating objects in the river channel mainly faces the problems of small target size, little feature information, uneven dispersion, and serious background interference of floating objects on the water surface, the existing methods have a good performance in target detection of small floating objects in the river channel. Existing methods for the detection of floating objects in the river channel will face these difficulties such as low detection accuracy, leakage and false detection, bad real-time, and other problems. In order to solve these problems, this paper proposes an improved river small target detection model PAW-YOLOv7 based on YOLOv7. Firstly, in order to improve the feature expression ability of the network model for small targets, a small target object detection layer is constructed, a 160×160-size output is added, and self-attention and convolutional mixing module (ACmix) is integrated and applied to the newly constructed small target detection layer to achieve the effect of enhancing the model's feature perception and location information of distant small targets. Secondly, to reduce the interference of complex backgrounds, the new ODCBS module is constructed by using Omni-dimensional dynamic convolution (ODConv) instead of the convolution module of the neck, and the attention value is analyzed and learned from the spatial dimension of the convolution kernel, the dimension of the input channel, and the dimension of the output channel, respectively, in each part of the convolutional layer to enable the network to effectively capture richer contextual information. Finally, the PConv (partial convolution) module is integrated into the backbone network to replace part of the standard convolution, while the WIoU (Wise-IoU) loss function is used to replace the CIoU, to realize a reduction in the computation of the network model, improve the network detection speed, and at the same time, increase the low-quality anchor frames' focusing ability, and accelerate the model convergence speed. The experimental results show that the detection accuracy of the PAW-YOLOv7 algorithm on the FloW-Img dataset improved by the data extension technique used in this paper reaches 89.7%, which is 9.8% higher than that of the original YOLOv7. The detection speed reaches 54 frames per second (FPS), and the detection accuracy on the self-constructed sparse floater dataset improves by 3.7% compared with that of YOLOv7. It can quickly and accurately detect tiny floating objects in the river channel and also has better real-time detection performance. Finally, compared with the mainstream detection methods, the method in this paper has the best comprehensive effect.
-
Access History
Figures(11)
Tables(3)
Article Metrics


Export File
Citation
Luan Q L, Chang X Y, Wu Y, et al. PAW-YOLOv7: algorithm for detection of tiny floating objects in river channels[J]. Opto-Electron Eng, 2024, 51(4): 240025. doi: 10.12086/oee.2024.240025
Format
Content
 DownLoad:
DownLoad:




-
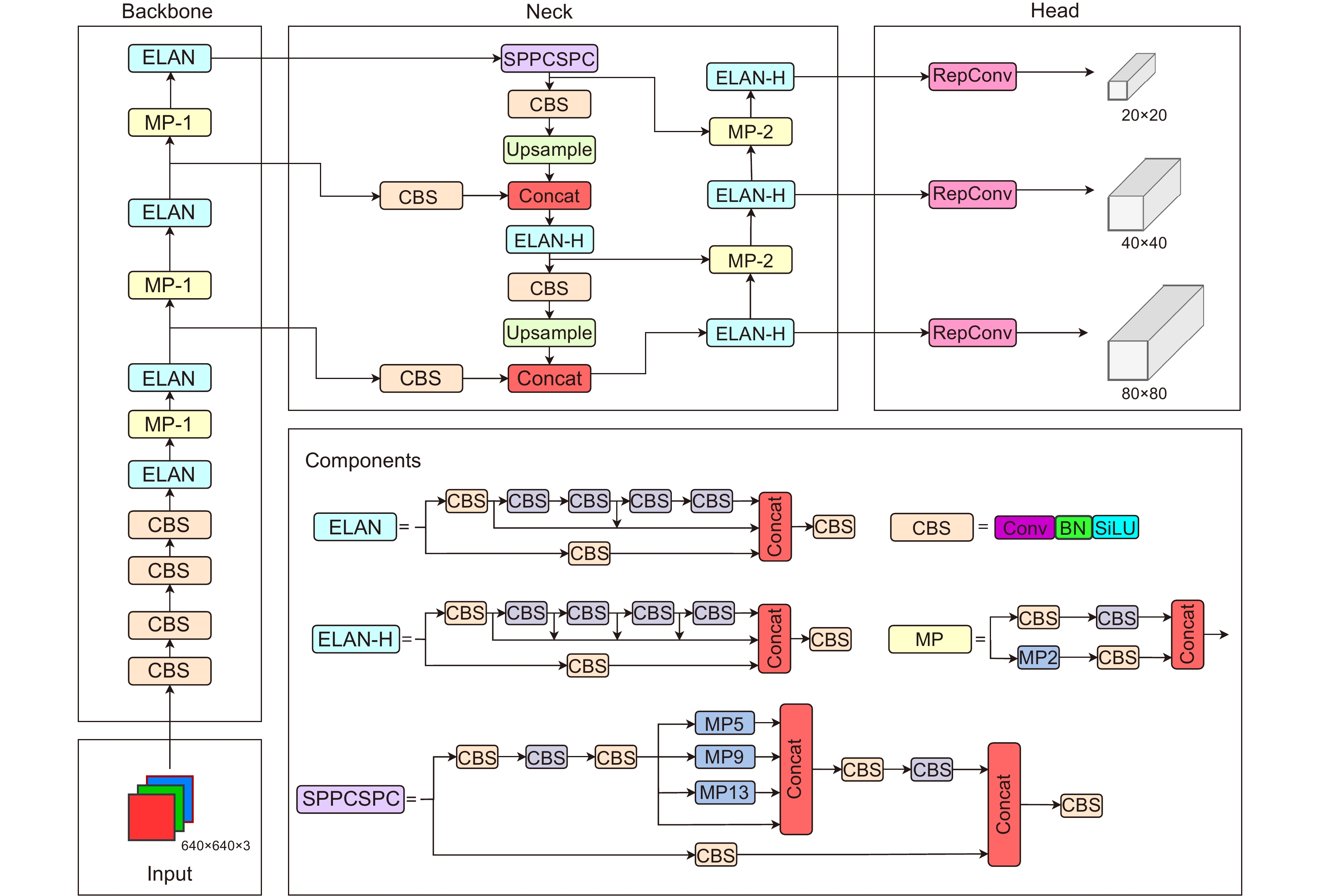
Figure 1.
YOLOv7 network structure
-
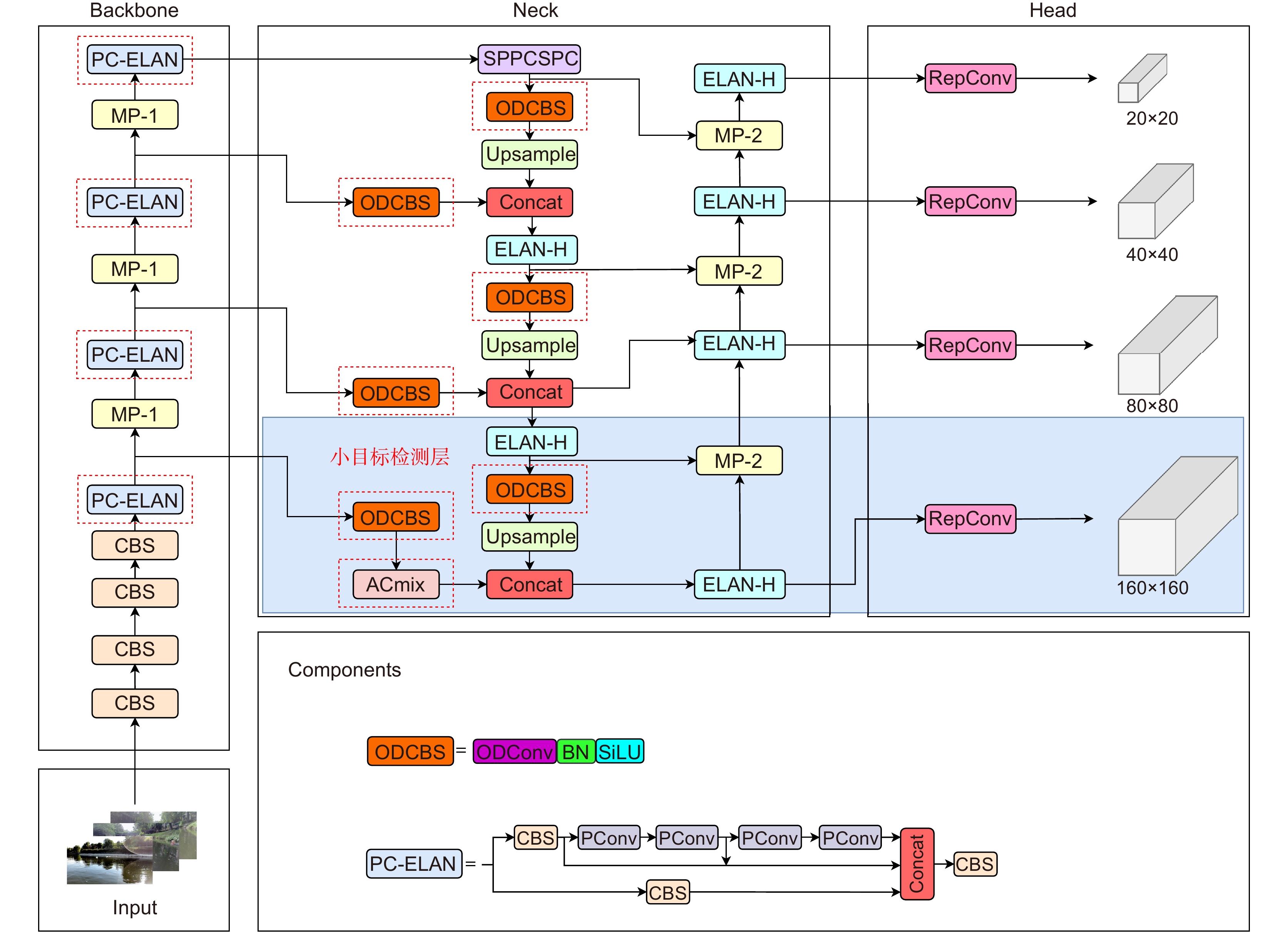
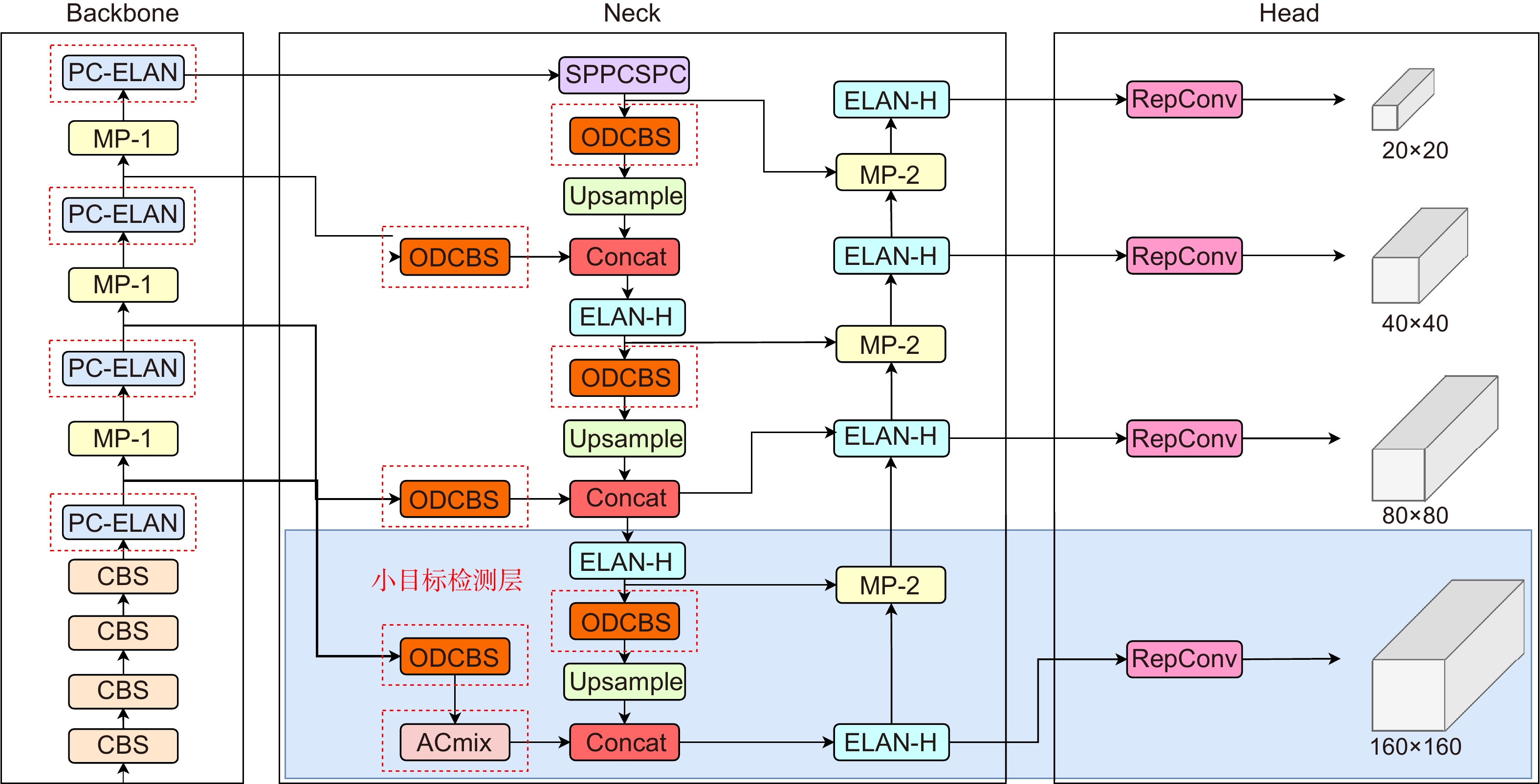
Figure 5.
PAW-YOLOv7 network structure diagram
-
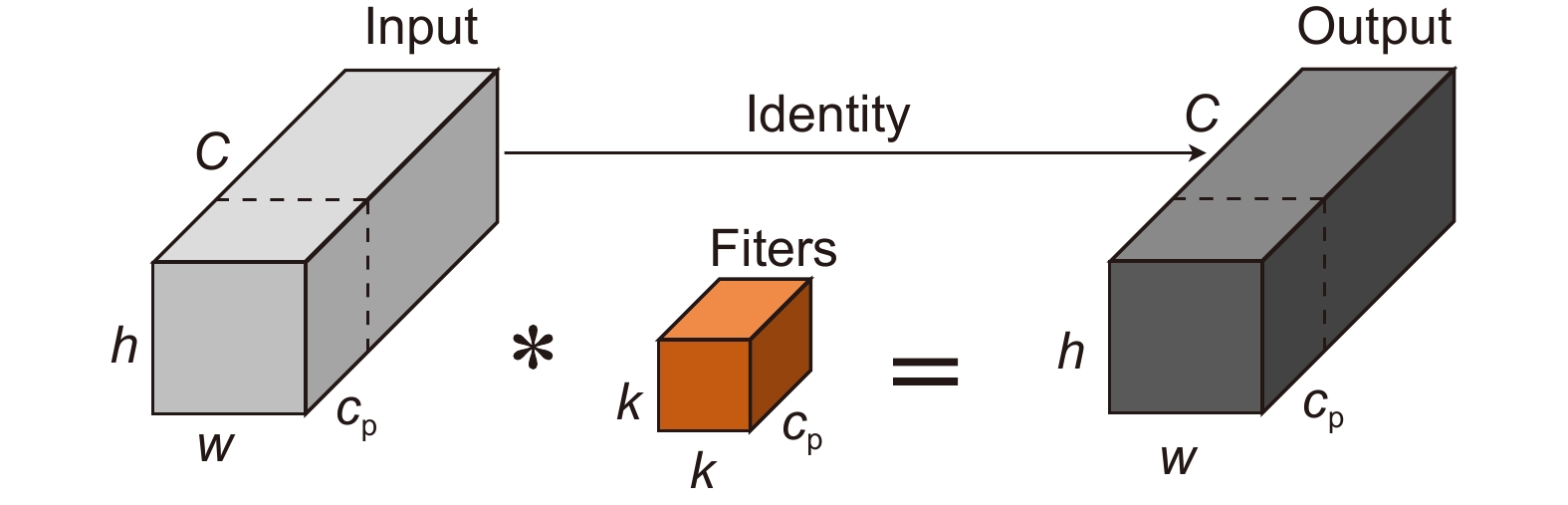
Figure 2.
PConv structure diagram
-
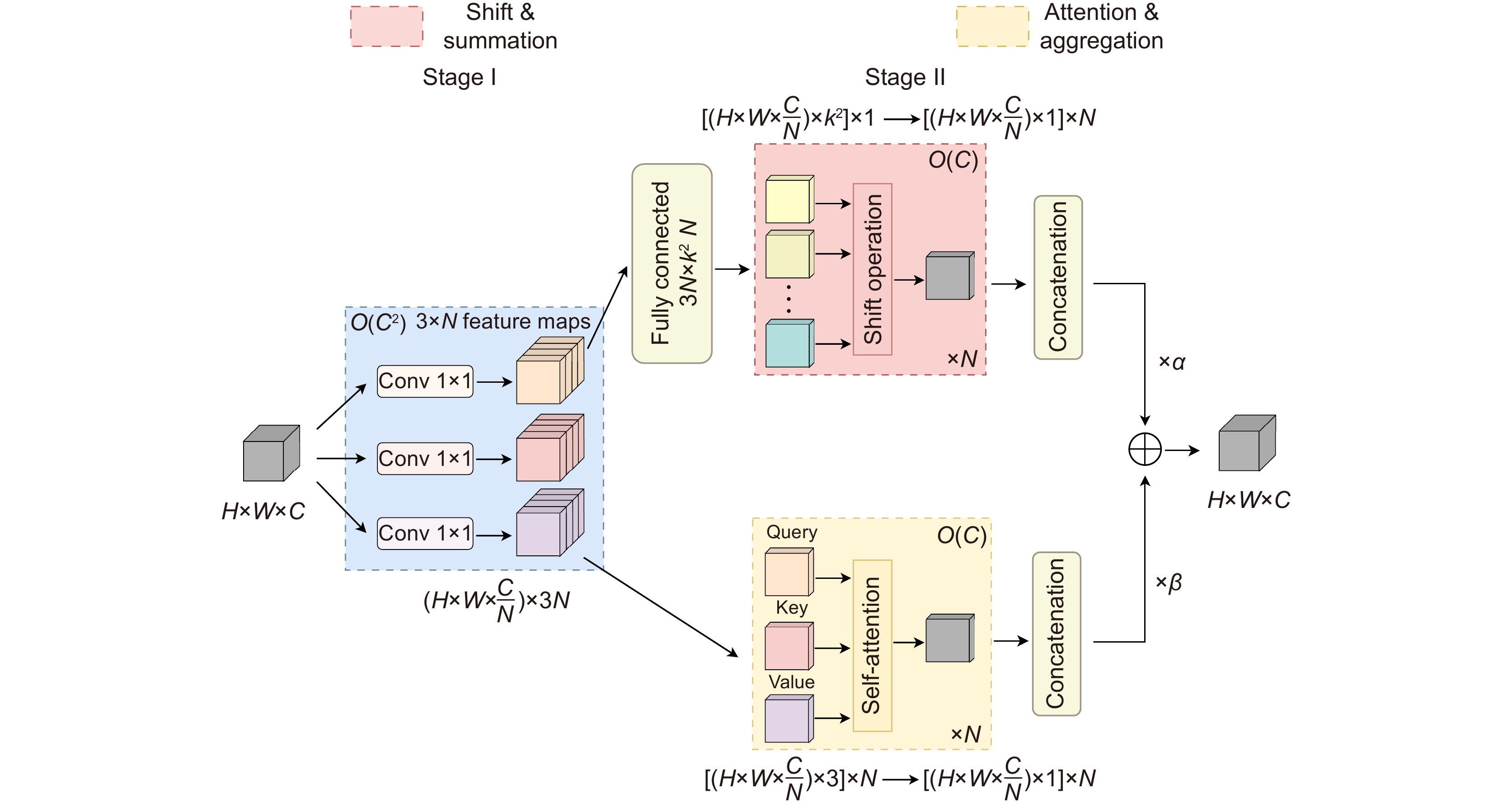
Figure 3.
The process of calculating ODConv
-
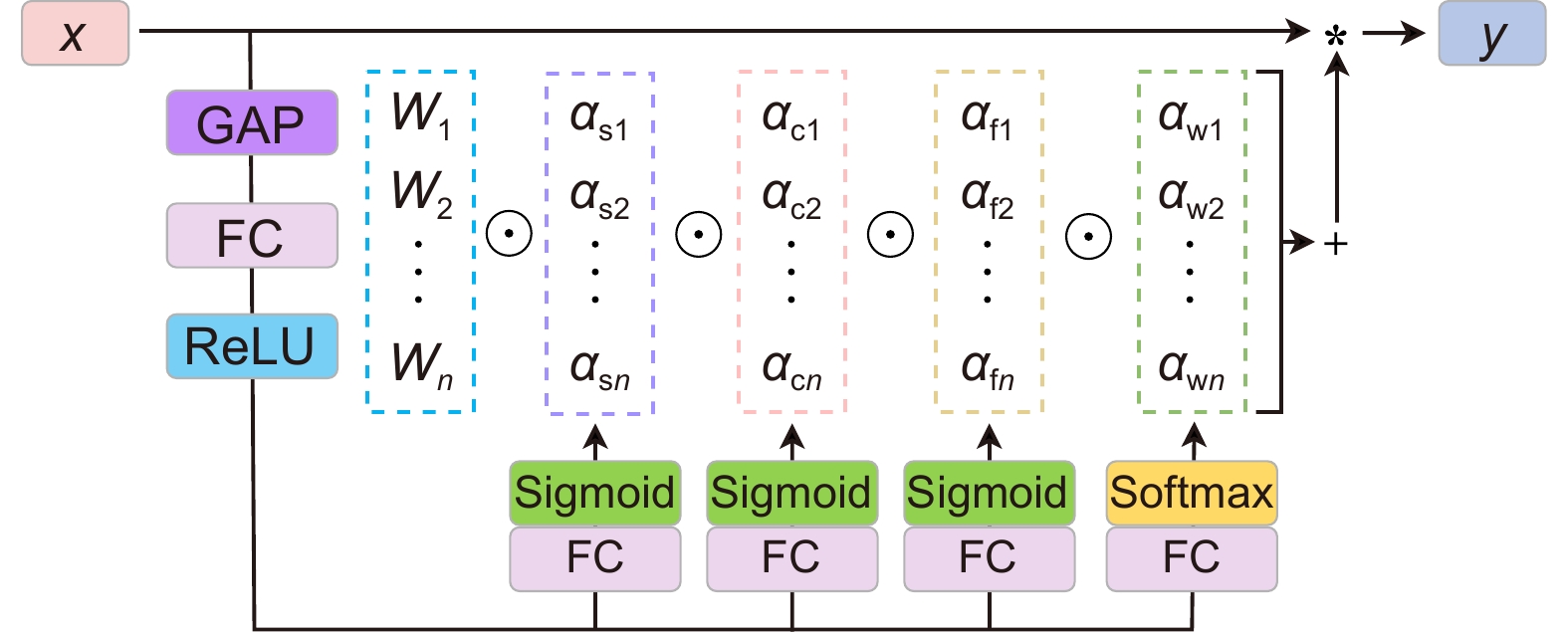
Figure 4.
ACmix structure diagram
-
Figure 6.
Results of different data expansion methods
-
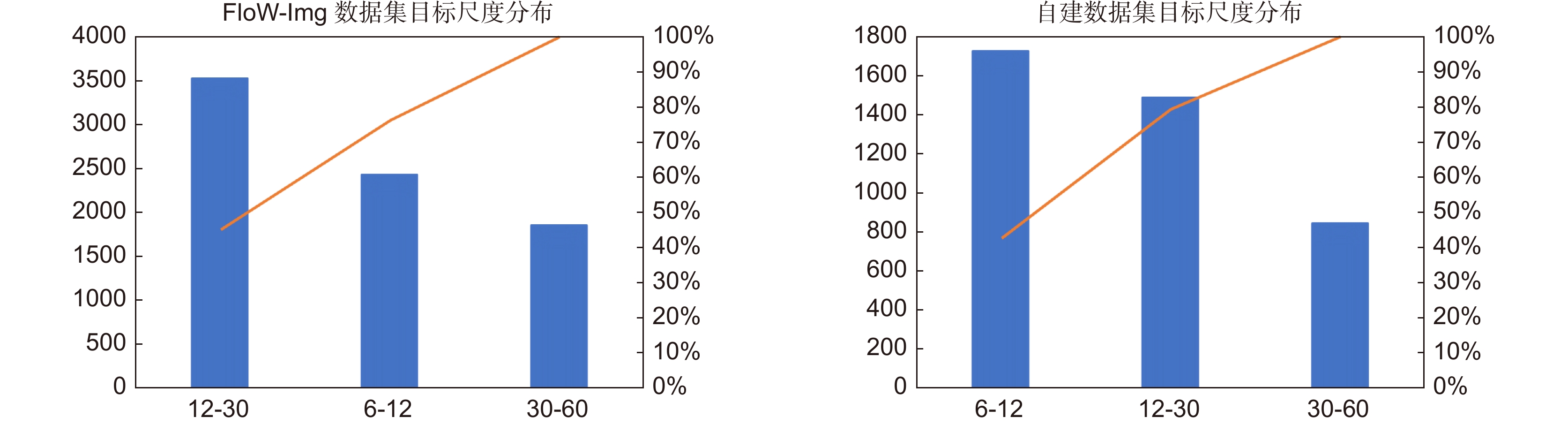
Figure 7.
Object scale distribution of the dataset
-
Figure 8.
Target detection results of different algorithms in different scenes. Left: detection image, Center: YOLOv7 model, Right: algorithm of this paper
-
Figure 9.
Comparison of detection accuracy of self-built datasets
-
Figure 10.
Comparison results of heat maps with different algorithms
- Figure .


