
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Jiang W T, Chen C, Zhang S C. Sparse feature image classification network with spatial position correction[J]. Opto-Electron Eng, 2024, 51(5): 240050. doi: 10.12086/oee.2024.240050

|
Sparse feature image classification network with spatial position correction
-
Abstract
To sparse semantics and enhance attention to key features, enhance the correlation between spatial and local features, and constrain the spatial position of features, this paper proposes a sparse feature image classification network with spatial position correction (SSCNet) for spatial position correction. This network is based on the ResNet-34 residual network. Firstly, a sparse semantic enhanced feature (SSEF) module is proposed, which combines depthwise separable convolution (DSC) and SE to enhance feature extraction ability while maintaining the integrity of spatial information; Then, the spatial position correction symmetric attention mechanism (SPCS) is proposed. SPCS adds the symmetric global coordinate attention mechanism to specific positions in the network, which can strengthen the spatial relationships between features, constrain and correct the spatial positions of features, and enhance the network's perception of global detailed features; Finally, the average pooling module (APM) is proposed and applied to each residual branch of the network, enabling the network to more effectively capture global feature information, enhance feature translation invariance, delay network overfitting, and improve network generalization ability. In the CIFAR-10, CIFAR-100, SVHN, Imagenette, and Imagewood datasets, SSCNet has shown varying degrees of improvement in classification accuracy compared to other high-performance networks, proving that SSCNet can better extract local detail information while balancing global information, with high classification accuracy and strong generalization performance. -

-
References
[1] Yang H, Li J. Label contrastive learning for image classification[J]. Soft Comput, 2023, 27(18): 13477−13486. doi: 10.1007/s00500-022-07808-z [2] Szegedy C, Liu W, Jia Y Q, et al. Going deeper with convolutions[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, 2015: 1–9. https://doi.org/10.1109/CVPR.2015.7298594. [3] Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proc IEEE, 1998, 86(11): 2278−2324. doi: 10.1109/5.726791 [4] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[J]. Commun ACM, 2017, 60(6): 84−90. doi: 10.1145/3065386 [5] He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, 2016: 770–778. https://doi.org/10.1109/CVPR.2016.90. [6] 徐胜军, 荆扬, 李海涛, 等. 渐进式多粒度ResNet车型识别网络[J]. 光电工程, 2023, 50(7): 230052. doi: 10.12086/oee.2023.230052 Xu S J, Jing Y, Li H T, et al. Progressive multi-granularity ResNet vehicle recognition network[J]. Opto-Electron Eng, 2023, 50(7): 230052. doi: 10.12086/oee.2023.230052 [7] Wang J, Yang Q P, Yang S Q, et al. Dual-path processing network for high-resolution salient object detection[J]. Appl Intell, 2022, 52(10): 12034−12048. doi: 10.1007/s10489-021-02971-6 [8] Xue T, Hong Y. IX-ResNet: fragmented multi-scale feature fusion for image classification[J]. Multimed Tools Appl, 2021, 80(18): 27855−27865. doi: 10.1007/s11042-021-10893-1 [9] Jiang Z W, Ma Z J, Wang Y N, et al. Aggregated decentralized down-sampling-based ResNet for smart healthcare systems[J]. Neural Comput Appl, 2023, 35(20): 14653−14665. doi: 10.1007/s00521-021-06234-w [10] Luo Z B, Sun Z T, Zhou W L, et al. Rethinking ResNets: improved stacking strategies with high-order schemes for image classification[J]. Complex Intell Syst, 2022, 8(4): 3395−3407. doi: 10.1007/S40747-022-00671-3 [11] Jafar A, Lee M. High-speed hyperparameter optimization for deep ResNet models in image recognition[J]. Cluster Comput, 2023, 26(5): 2605−2613. doi: 10.1007/s10586-021-03284-6 [12] 陈龙, 张建林, 彭昊, 等. 多尺度注意力与领域自适应的小样本图像识别[J]. 光电工程, 2023, 50(4): 220232. doi: 10.12086/oee.2023.220232 Chen L, Zhang J L, Peng H, et al. Few-shot image classification via multi-scale attention and domain adaptation[J]. Opto-Electron Eng, 2023, 50(4): 220232. doi: 10.12086/oee.2023.220232 [13] 梁礼明, 金家新, 冯耀, 等. 融合坐标感知与混合提取的视网膜病变分级算法[J]. 光电工程, 2024, 51(1): 230276. doi: 10.12086/oee.2024.230276 Liang L M, Jin J X, Feng Y, et al. Retinal lesions graded algorithm that integrates coordinate perception and hybrid extraction[J]. Opto-Electron Eng, 2024, 51(1): 230276. doi: 10.12086/oee.2024.230276 [14] 叶宇超, 陈莹. 跨尺度注意力融合的单幅图像去雨[J]. 光电工程, 2023, 50(10): 230191. doi: 10.12086/oee.2023.230191 Ye Y C, Chen Y. Single image rain removal based on cross scale attention fusion[J]. Opto-Electron Eng, 2023, 50(10): 230191. doi: 10.12086/oee.2023.230191 [15] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745. [16] Ying Y, Zhang N B, Shan P, et al. PSigmoid: improving squeeze-and-excitation block with parametric sigmoid[J]. Appl Intell, 2021, 51(10): 7427−7439. doi: 10.1007/s10489-021-02247-z [17] Hou Q B, Zhou D Q, Feng J S. Coordinate attention for efficient mobile network design[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, 2021: 13708–13717. https://doi.org/10.1109/CVPR46437.2021.01350. [18] Ji Q W, Yu B, Yang Z W, et al. LAM: lightweight attention module[C]//15th International Conference on Knowledge Science, Engineering and Management, Singapore, 2022: 485–497. https://doi.org/10.1007/978-3-031-10986-7_39. [19] Zhong H M, Han T T, Xia W, et al. Research on real-time teachers’ facial expression recognition based on YOLOv5 and attention mechanisms[J]. EURASIP J Adv Signal Process, 2023, 2023(1): 55. doi: 10.1186/s13634-023-01019-w [20] Qi F, Wang Y L, Tang Z. Lightweight plant disease classification combining GrabCut algorithm, new coordinate attention, and channel pruning[J]. Neural Process Lett, 2022, 54(6): 5317−5331. doi: 10.1007/s11063-022-10863-0 [21] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]//32nd International Conference on Machine Learning, Lille, 2015: 448–456. [22] Abdi M, Nahavandi S. Multi-residual networks: improving the speed and accuracy of residual networks[Z]. arXiv: 1609.05672, 2016. https://doi.org/10.48550/arXiv.1609.05672. [23] Ma C X, Wu J B, Si C Y, et al. Scaling supervised local learning with augmented auxiliary networks[Z]. arXiv: 2402.17318, 2024. https://doi.org/10.48550/arXiv.2402.17318. [24] Wu X D, Gao S Q, Zhang Z Y, et al. Auto-train-once: controller network guided automatic network pruning from scratch[Z]. arXiv: 2403.14729, 2024. https://doi.org/10.48550/arXiv.2403.14729. [25] Huang G, Liu Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, 2017: 2261–2269. https://doi.org/10.1109/CVPR.2017.243. [26] Lan H, Wang X H, Shen H, et al. Couplformer: rethinking vision transformer with coupling attention[C]//Proceedings of 2023 IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, 2023: 6464–6473. https://doi.org/10.1109/WACV56688.2023.00641. [27] Zhou C L, Zhang H, Zhou Z K, et al. QKFormer: hierarchical spiking transformer using Q-K attention[Z]. arXiv: 2403.16552, 2024. https://doi.org/10.48550/arXiv.2403.16552. [28] Shin H, Choi D W. Teacher as a lenient expert: teacher-agnostic data-free knowledge distillation[C]//Proceedings of the 38th AAAI Conference on Artificial Intelligence, Vancouver, 2024: 14991–14999. https://doi.org/10.1609/aaai.v38i13.29420. [29] Tan M X, Le Q. EfficientNet: rethinking model scaling for convolutional neural networks[C]//36th International Conference on Machine Learning, Long Beach, 2019: 6105–6114. -
Overview
To sparse semantics and enhance attention to key features, enhance the correlation between spatial and local features, and constrain the spatial position of features, this paper proposes a Sparse Feature Image Classification Network with Spatial Position Correction (SSCNet) for spatial position correction. Firstly, a Sparse Semantic Enhanced Feature Module (SSEF) module is proposed, which combines Depth Separable Convolution (DSC) and SE (Squeeze and Excitation) modules to enhance feature extraction ability while maintaining spatial information integrity; Then, the Spatial Position Correction Symmetric Attention Mechanism (SPCS) is proposed. SPCS adds the symmetric coordinate attention mechanism to specific positions in the network, which can strengthen the spatial relationships between features, constrain and correct their spatial positions, and enhance the network's perception of global detailed features; Finally, the Average Pooling Module (APM) is proposed and applied to each residual branch of the network, enabling the network to more effectively capture global feature information, enhance feature translation invariance, delay network overfitting, and improve network generalization ability. This article used CIFAR-10, CIFAR-100, SVHN, Imagenette, and Imagewood datasets as experimental datasets. The CIFAR-10 dataset contains a total of 60000 color images from 10 categories, each with a resolution of 32×32 pixels. This dataset is commonly used to test and compare the performance of image classification algorithms. The CIFAR-100 dataset is more challenging and used to evaluate model performance for finer grained image classification tasks. The SVHN dataset contains real-world street view house number images, which contain digital images from Google Street View images used to recognize numbers on house signs. The images in the SVHN dataset are divided into training, testing, and additional training sets, each containing one or more numbers, and the resolution of the images is also higher than that of the CIFAR dataset. The Imagenette and Imagewof datasets are small scale subsets extracted from ImageNet, which have been streamlined and adjusted based on the ImageNet dataset. This article compares the network model with 12 other network models on 5 datasets. In the CIFAR-10, CIFAR-100, SVHN, Imagenette, and Imagewood datasets, the classification accuracy of SSCNet is 96.72%, 80.63%, 97.43%, 88.75%, and 82.09%. Compared with other methods, SSCNet in this paper can better extract local detail information while balancing global information, and has higher classification accuracy and strong generalization performance.
-
Access History

Figures(14)
Tables(7)
Article Metrics


Export File
Citation
Jiang W T, Chen C, Zhang S C. Sparse feature image classification network with spatial position correction[J]. Opto-Electron Eng, 2024, 51(5): 240050. doi: 10.12086/oee.2024.240050
Format
Content
 DownLoad:
DownLoad:





-
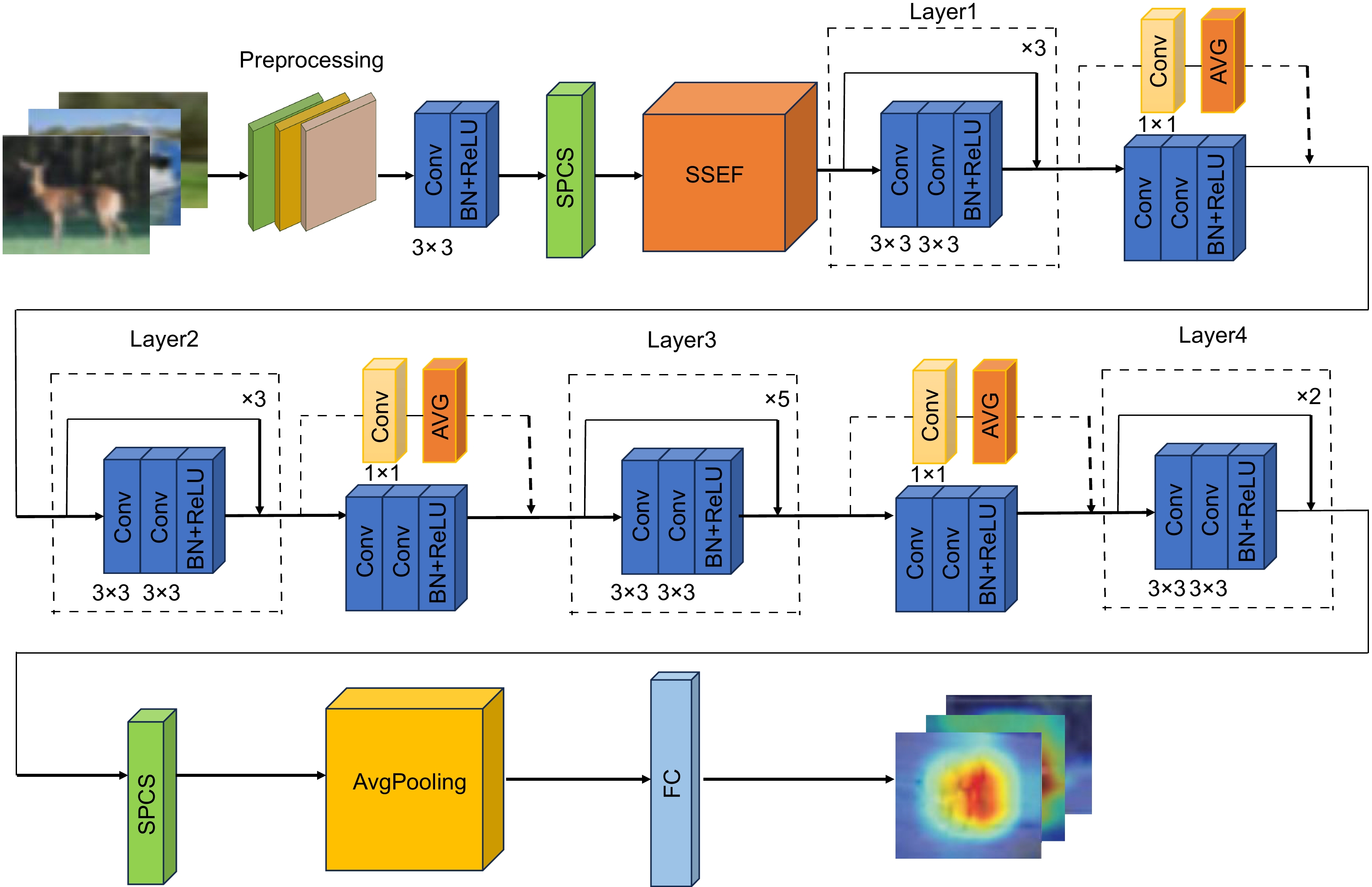
Figure 1.
SSCNet network structure
-
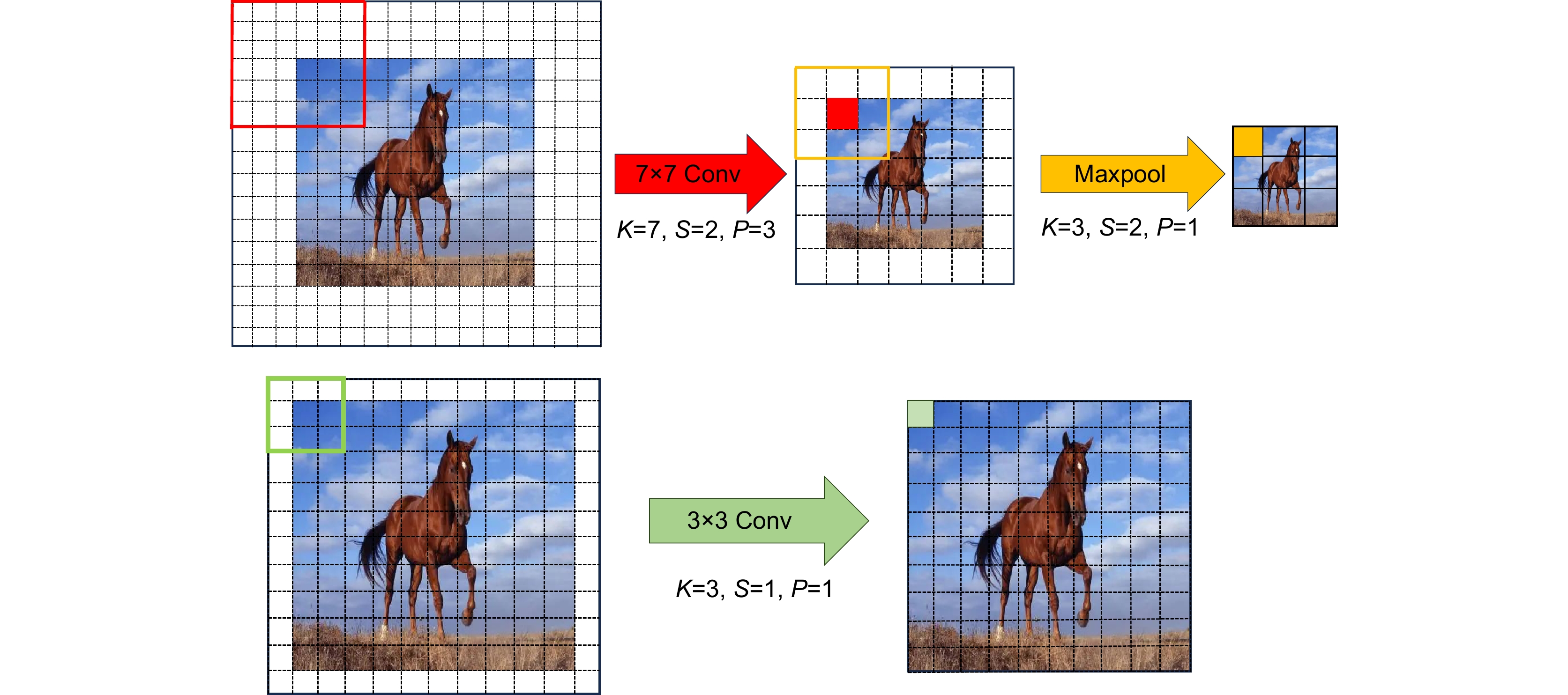
Figure 2.
Comparison of convolution operations before and after modifying the size of the first layer convolution kernel
-
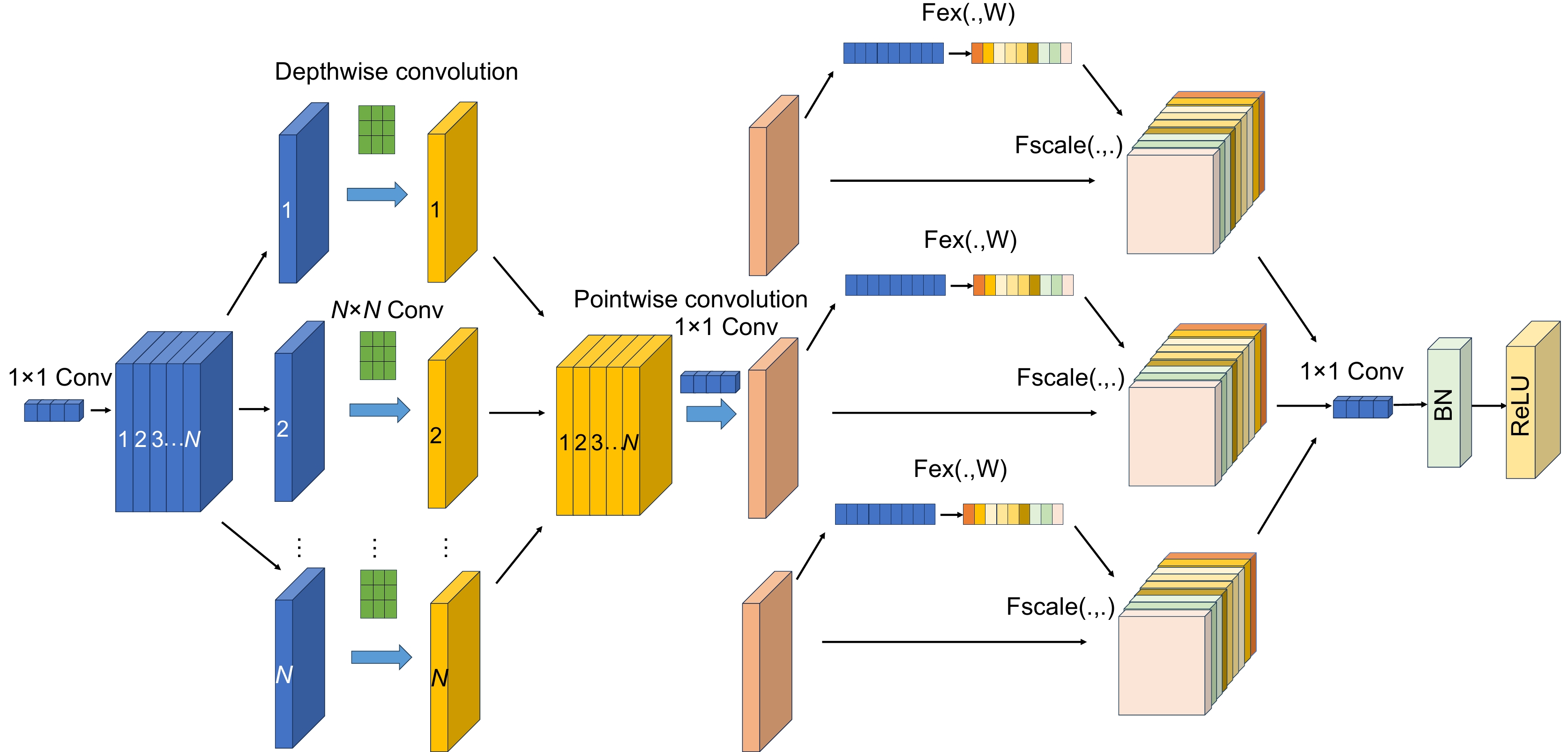
Figure 3.
SSEF module
-
Figure 4.
Spatial position rectification symmetric attention
-
Figure 5.
Coordinate attention structure
-
Figure 6.
Max coordinate attention structure
-
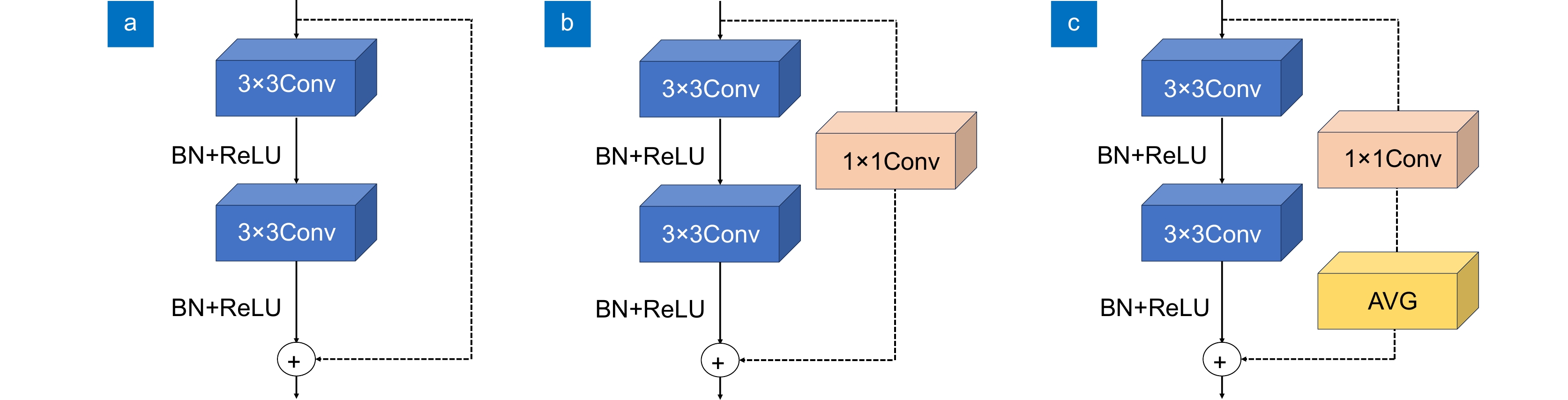
Figure 7.
Three types of residual blocks. (a) Basic block;(b) Residual block;(c) APM
-
Figure 8.
The arrangement of APM-Block and SSEF module positions and quantities
-
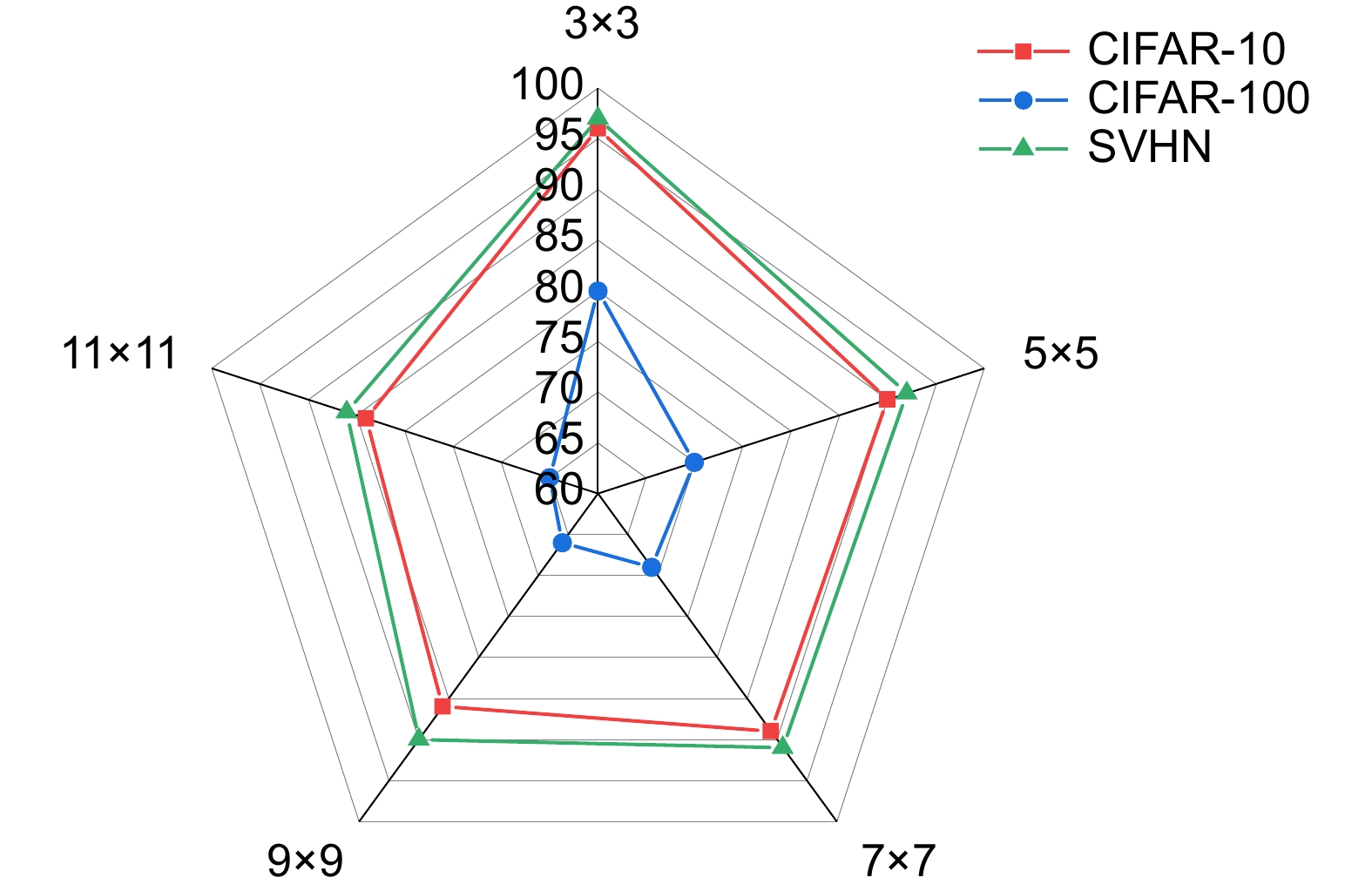
Figure 9.
Influence of different convolutional kernel sizes on classification accuracy
-
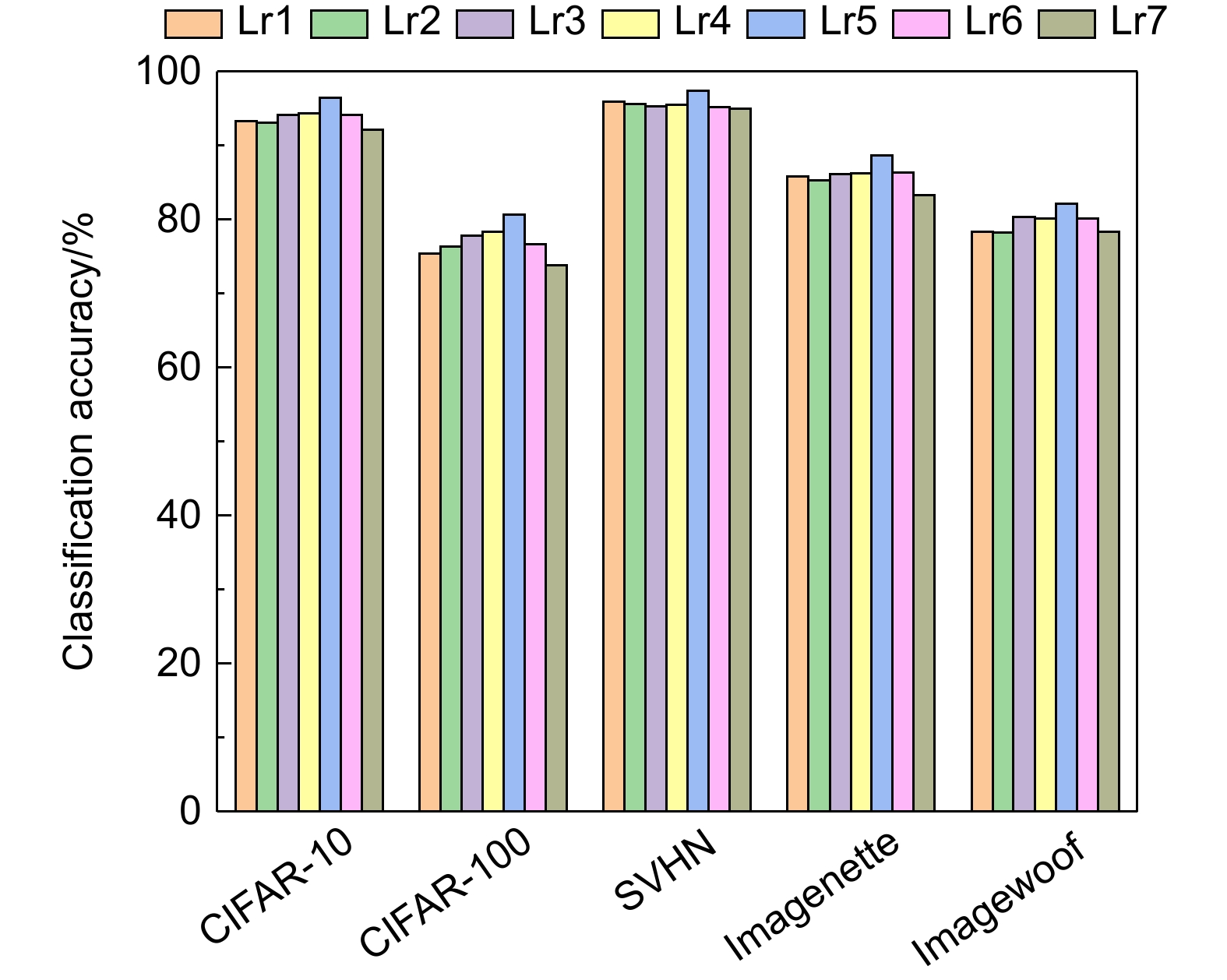
Figure 10.
Influence of different learning rates on classification accuracy
-
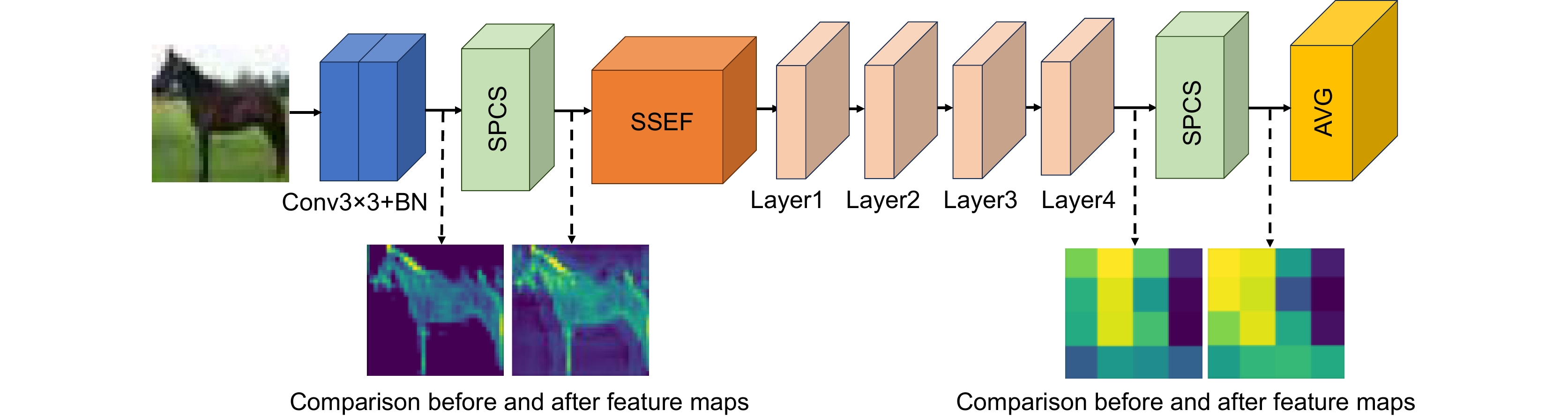
Figure 11.
Comparison of feature maps before and after SPCS module
-
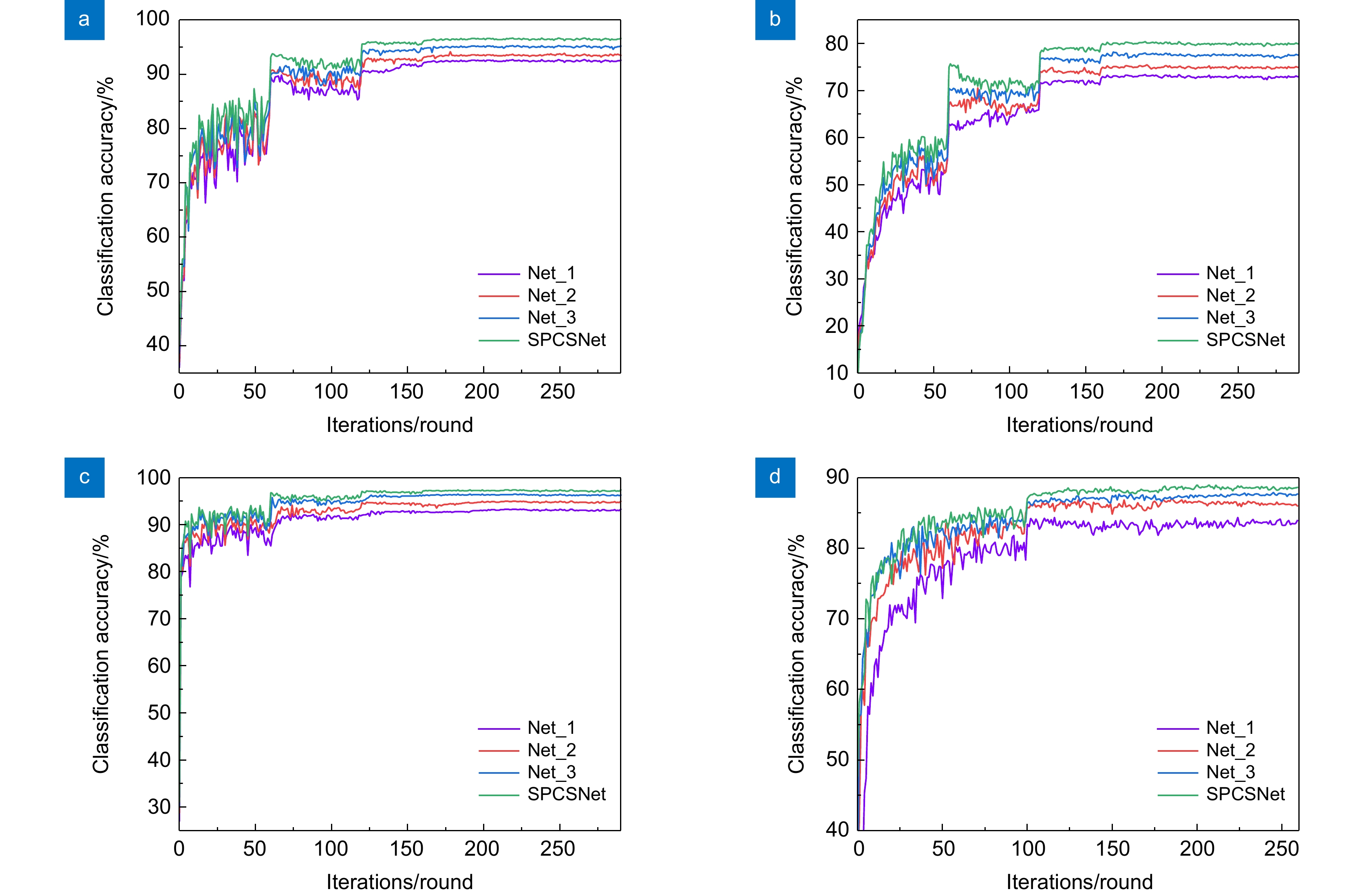
Figure 12.
Classification accuracy of each network on different datasets. (a) CIFAR-10;(b) CIFAR-100; (c) SVHN; (d) Imageneete
-
Figure 13.
Visualization images of heat maps for different networks
- Figure .


