
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Ge B, Xu N, Xia C X, et al. Quadrupl-stream input-guided feature complementary visible-infrared person re-identification[J]. Opto-Electron Eng, 2024, 51(9): 240119. doi: 10.12086/oee.2024.240119

|
Quadrupl-stream input-guided feature complementary visible-infrared person re-identification
-
Abstract
Current visible-infrared person re-identification research focuses on extracting modal shared saliency features through the attention mechanism to minimize modal differences. However, these methods only focus on the most salient features of pedestrians, and cannot make full use of modal information. To solve this problem, a quadrupl-stream input-guided feature complementary network (QFCNet) is proposed in this paper. Firstly, a quadrupl-stream feature extraction and fusion module is designed in the mode-specific feature extraction stage. By adding two data enhancement inputs, the color differences between modalities are alleviated, the semantic information of the modalities is enriched and the multi-dimensional feature fusion is further promoted. Secondly, a sub-salient feature complementation module is designed to supplement the pedestrian detail information ignored by the attention mechanism in the global feature through the inversion operation, to strengthen the pedestrian discriminative features. The experimental results on two public datasets SYSU-MM01 and RegDB show the superiority of this method. In the full search mode of SYSU-MM01, the rank-1 and mAP values reach 76.12% and 71.51%, respectively.-
Keywords:
- cross-modal /
- person re-identification /
- infrared /
- data augmentation /
- attention mechanism
-

-
References
[1] 石跃祥, 周玥. 基于阶梯型特征空间分割与局部注意力机制的行人重识别[J]. 电子与信息学报, 2022, 44(1): 195−202. doi: 10.11999/JEIT201006 Shi Y X, Zhou Y. Person re-identification based on stepped feature space segmentation and local attention mechanism[J]. J Electron Inf Technol, 2022, 44(1): 195−202. doi: 10.11999/JEIT201006 [2] 刘丽, 李曦, 雷雪梅. 多尺度多特征融合的行人重识别模型[J]. 计算机辅助设计与图形学学报, 2022, 34(12): 1868−1876. doi: 10.3724/SP.J.1089.2022.19218 Liu L, Li X, Lei X M. A person re-identification method with multi-scale and multi-feature fusion[J]. J Comput-Aided Des Comput Graphics, 2022, 34(12): 1868−1876. doi: 10.3724/SP.J.1089.2022.19218 [3] 程思雨, 陈莹. 伪标签细化引导的相机感知无监督行人重识别方法[J]. 光电工程, 2023, 50(12): 230239. doi: 10.12086/oee.2023.230239 Cheng S Y, Chen Y. Camera-aware unsupervised person re-identification method guided by pseudo-label refinement[J]. Opto-Electron Eng, 2023, 50(12): 230239. doi: 10.12086/oee.2023.230239 [4] 郑海君, 葛斌, 夏晨星, 等. 多特征聚合的红外-可见光行人重识别[J]. 光电工程, 2023, 50(7): 230136. doi: 10.12086/oee.2023.230136 Zheng H J, Ge B, Xia C X, et al. Infrared-visible person re-identification based on multi feature aggregation[J]. Opto-Electron Eng, 2023, 50(7): 230136. doi: 10.12086/oee.2023.230136 [5] Zhang Y K, Wang H Z. Diverse embedding expansion network and low-light cross-modality benchmark for visible-infrared person re-identification[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, 2023: 2153–2162. https://doi.org/10.1109/CVPR52729.2023.00214. [6] Wu Q, Dai P Y, Chen J, et al. Discover cross-modality nuances for visible-infrared person re-identification[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, 2021: 4330–4339. https://doi.org/10.1109/CVPR46437.2021.00431. [7] Zhang Y Y, Kang Y H, Zhao S Y, et al. Dual-semantic consistency learning for visible-infrared person re-identification[J]. IEEE Trans Inf Forensics Secur, 2022, 18: 1554−1565. doi: 10.1109/TIFS.2022.3224853 [8] Ye M, Shen J B, Crandall D J, et al. Dynamic dual-attentive aggregation learning for visible-infrared person re-identification[C]//Proceedings of the 16th European Conference, Glasgow, 2020: 229–247. https://doi.org/10.1007/978-3-030-58520-4_14. [9] Choi S, Lee S, Kim Y, et al. Hi-CMD: hierarchical cross-modality disentanglement for visible-infrared person re-identification[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 10257–10266. https://doi.org/10.1109/CVPR42600.2020.01027. [10] Zhang Y K, Yan Y, Lu Y, et al. Towards a unified middle modality learning for visible-infrared person re-identification[C]//New York: Proceedings of the 29th ACM International Conference on Multimedia, 2021: 788–796. https://doi.org/10.1145/3474085.3475250. [11] Ma L, Guan Z B, Dai X G, et al. A cross-modality person re-identification method based on joint middle modality and representation learning[J]. Electronics, 2023, 12(12): 2687. doi: 10.3390/electronics12122687 [12] Ye M, Shen J B, Shao L. Visible-infrared person re-identification via homogeneous augmented tri-modal learning[J]. IEEE Trans Inf Forensics Secur, 2021, 16: 728−739. doi: 10.1109/tifs.2020.3001665 [13] Zhang Q, Lai C Z, Liu J N, et al. FMCNet: feature-level modality compensation for visible-infrared person re-identification[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, 2022: 7349–7358. https://doi.org/10.1109/CVPR52688.2022.00720. [14] Lu J, Zhang S S, Chen M D, et al. Cross-modality person re-identification based on intermediate modal generation[J]. Opt Lasers Eng, 2024, 177: 108117. doi: 10.1016/j.optlaseng.2024.108117 [15] Li D G, Wei X, Hong X P, et al. Infrared-visible cross-modal person re-identification with an X modality[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, 2020: 4610–4617. https://doi.org/10.1609/aaai.v34i04.5891. [16] Ye M, Shen J B, Lin G J, et al. Deep learning for person re-identification: a survey and outlook[J]. IEEE Trans Pattern Anal Mach Intell, 2022, 44(6): 2872−2893. doi: 10.1109/TPAMI.2021.3054775 [17] Ye M, Ruan W J, Du B, et al. Channel augmented joint learning for visible-infrared recognition[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, Montreal, 2021: 13567–13576. https://doi.org/10.1109/ICCV48922.2021.01331. [18] Pan X G, Luo P, Shi J P, et al. Two at once: enhancing learning and generalization capacities via IBN-net[C]//Proceedings of the 15th European Conference on Computer Vision, Munich, 2018: 464–479. https://doi.org/10.1007/978-3-030-01225-0_29. [19] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745. [20] Wang X L, Girshick R, Gupta A, et al. Non-local neural networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 7794–7803. https://doi.org/10.1109/CVPR.2018.00813. [21] Wu A C, Zheng W S, Yu H X, et al. RGB-infrared cross-modality person re-identification[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, Venice, 2017: 5380–5389. https://doi.org/10.1109/ICCV.2017.575. [22] Nguyen D T, Hong H G, Kim K W, et al. Person recognition system based on a combination of body images from visible light and thermal cameras[J]. Sensors, 2017, 17(3): 605. doi: 10.3390/s17030605 [23] Wang G A, Zhang T Z, Cheng J, et al. RGB-infrared cross-modality person re-identification via joint pixel and feature alignment[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, Seoul, 2019: 3623–3632. https://doi.org/10.1109/ICCV.2019.00372. [24] Wang Z X, Wang Z, Zheng Y Q, et al. Learning to reduce dual-level discrepancy for infrared-visible person re-identification[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 618–626. https://doi.org/10.1109/CVPR.2019.00071. [25] Wang G A, Zhang T Z, Yang Y, et al. Cross-modality paired-images generation for RGB-infrared person re-identification[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, 2020: 12144–12151. https://doi.org/10.1609/aaai.v34i07.6894. [26] Hao X, Zhao S Y, Ye M, et al. Cross-modality person re-identification via modality confusion and center aggregation[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, Montreal, 2021: 16403–16412. https://doi.org/10.1109/ICCV48922.2021.01609. [27] Zheng X T, Chen X M, Lu X Q. Visible-infrared person re-identification via partially interactive collaboration[J]. IEEE Trans Image Process, 2022, 31: 6951−6963. doi: 10.1109/TIP.2022.3217697 [28] Lu H, Zou X Z, Zhang P P. Learning progressive modality-shared transformers for effective visible-infrared person re-identification[C]//Proceedings of the 37th AAAI Conference on Artificial Intelligence, Washington, 2023: 1835–1843. https://doi.org/10.1609/aaai.v37i2.25273. [29] Huang N C, Liu J N, Luo Y J, et al. Exploring modality-shared appearance features and modality-invariant relation features for cross-modality person Re-IDentification[J]. Pattern Recognit, 2023, 135: 109145. doi: 10.1016/j.patcog.2022.109145 [30] Liu H J, Xia D X, Jiang W. Towards homogeneous modality learning and multi-granularity information exploration for visible-infrared person re-identification[J]. IEEE J Sel Top Signal Process, 2023, 17(3): 545−559. doi: 10.1109/JSTSP.2022.3233716 [31] Huang N C, Xing B C, Zhang Q, et al. Co-segmentation assisted cross-modality person re-identification[J]. Inf Fusion, 2024, 104: 102194. doi: 10.1016/j.inffus.2023.102194 [32] Lu Z F, Lin R H, Hu H F. Tri-level modality-information disentanglement for visible-infrared person re-identification[J]. IEEE Trans Multimedia, 2024, 26: 2700−2714. doi: 10.1109/TMM.2023.3302132 [33] van der Maaten L, Hinton G. Visualizing data using t-SNE[J]. J Mach Learn Res, 2008, 9(86): 2579−2605. [34] Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[J]. Int J Comput Vis, 2020, 128(2): 336−359. doi: 10.1007/s11263-019-01228-7 -
Overview
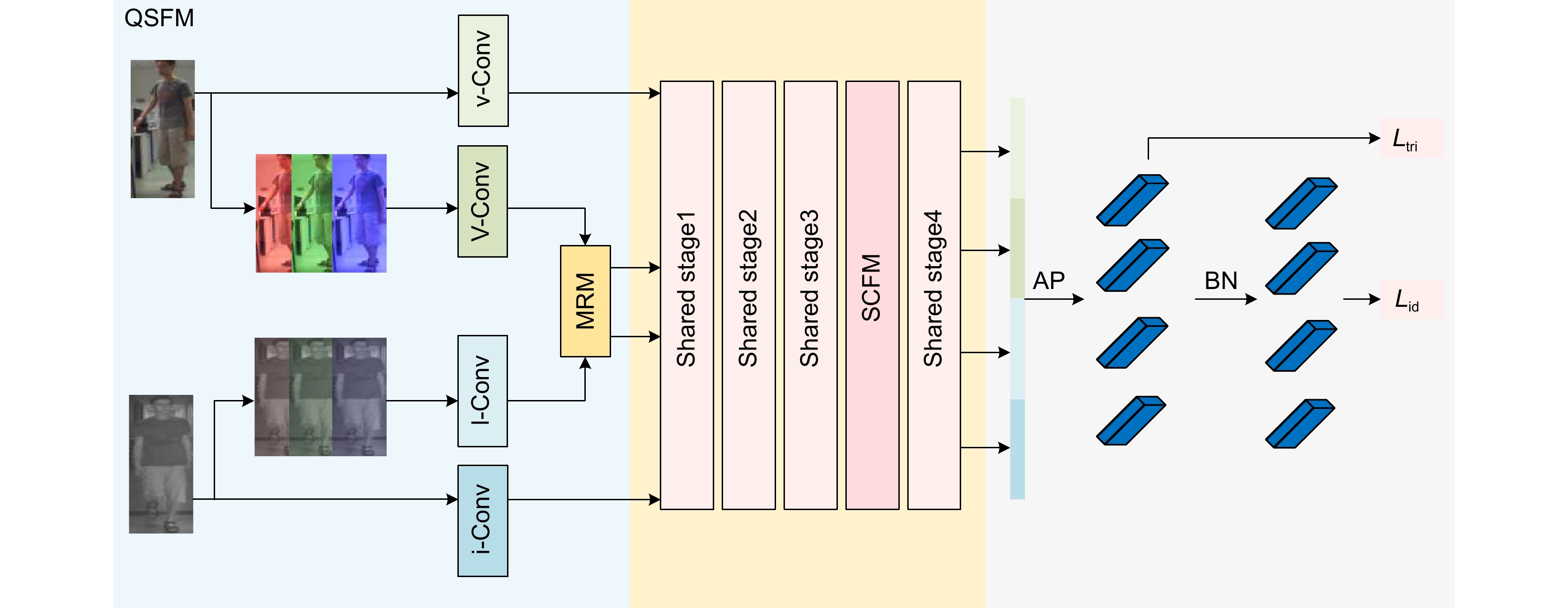
Cross-modal person re-identification is the task of identifying individuals from images of different modalities under non-overlapping camera angles, which has a wide range of practical applications. Different from the previous VV-ReID(visible-visible person reidentification), VI-ReID(visible-infrared person reidentification) aims at image matching between visible and infrared modalities. Due to the imaging differences between visible and infrared cameras, there are huge modal differences between cross-modal images, and traditional person re-identification methods are difficult to apply to this scenario. In view of this situation, it is particularly important to study the pedestrian matching between visible and infrared images. How to realize the mutual recognition between visible and infrared pedestrian images efficiently and accurately has a very great practical value for improving the level of social management, preventing crime, maintaining national security, and so on. Similarly, cross-modal person re-identification technology also involves many challenges. Not only intra-modal variations such as viewpoint, pose, and low resolution need to be considered, but also inter-modal differences caused by different image channel information need to be addressed. Existing VI-ReID methods mainly focus on two aspects: (1) solving cross-modal problems by maximizing modal invariance; (2) Generate intermediate or target images, and transform the cross-modal matching problem into an intra-modal matching task. The first method makes it difficult to guarantee the quality of the modal invariant features, which leads to the loss of indirect information in the image representation of people. The second method inevitably introduces noise, which affects the stability of training and makes the quality of generated images difficult to guarantee. Current visible-infrared person re-identification research focuses on extracting modal shared saliency features through the attention mechanism to minimize modal differences. However, these methods only focus on the most salient features of pedestrians, and cannot make full use of modal information. To solve this problem, this paper proposes a quadrupl-stream input-guided feature complementary method based on deep learning, which can effectively alleviate the differences between modalities while retaining useful structural information. Firstly, a quadrupl-stream feature extraction and fusion module is designed in the mode-specific feature extraction stage. By adding two data enhancement inputs, the semantic information of the modalities is enriched and the multi-dimensional feature fusion is further promoted. Secondly, a sub-salient feature complementation module is designed to supplement the pedestrian detail information ignored by the attention mechanism in the global feature through the inversion operation. The experimental results on two public datasets SYSU-MM01 and RegDB show the superiority of this method. In the full search mode of SYSU-MM01, the rank-1 and mAP values reach 76.12% and 71.51%, respectively.
-
Access History
Figures(8)
Tables(4)
Article Metrics


Export File
Citation
Ge B, Xu N, Xia C X, et al. Quadrupl-stream input-guided feature complementary visible-infrared person re-identification[J]. Opto-Electron Eng, 2024, 51(9): 240119. doi: 10.12086/oee.2024.240119
Format
Content
 DownLoad:
DownLoad:

-
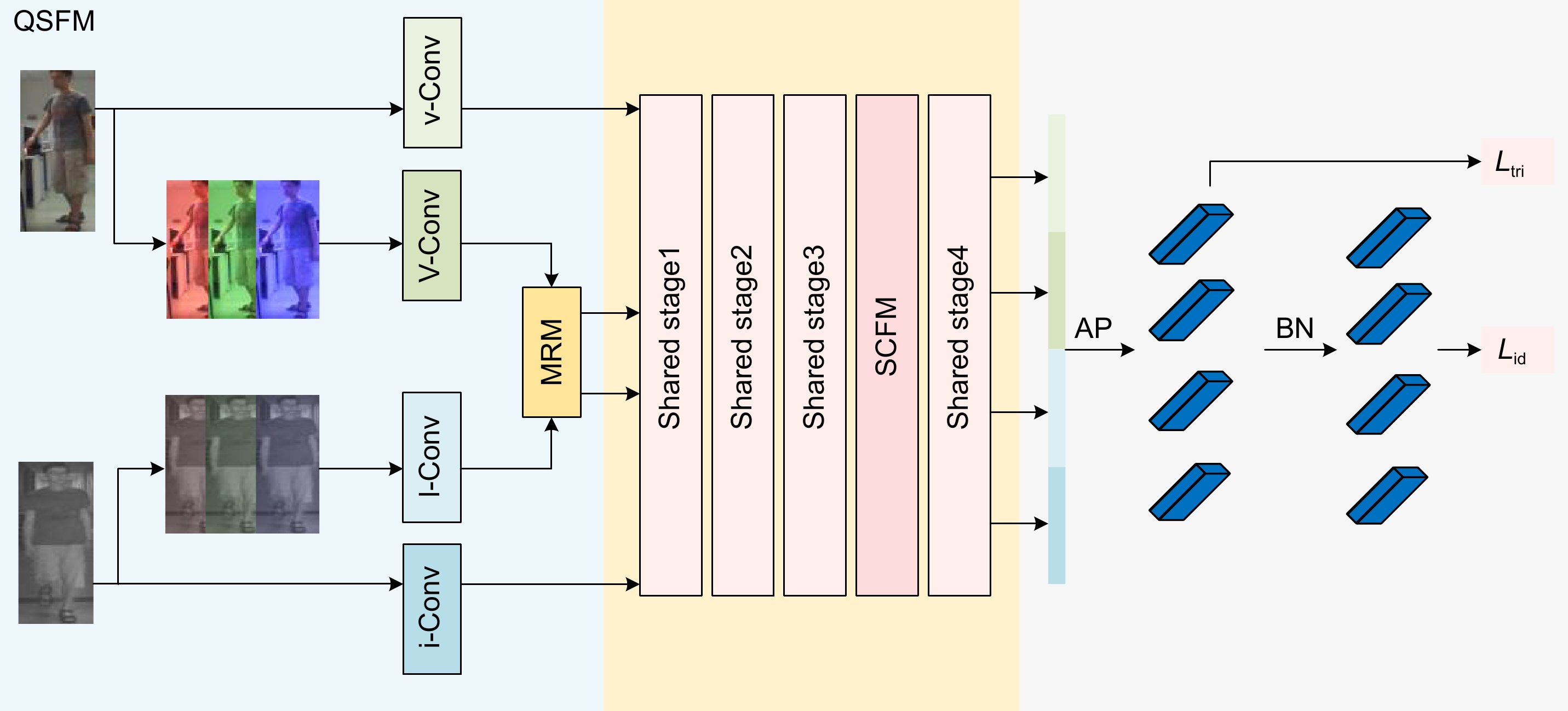
Figure 1.
QFCNet structure diagram
-
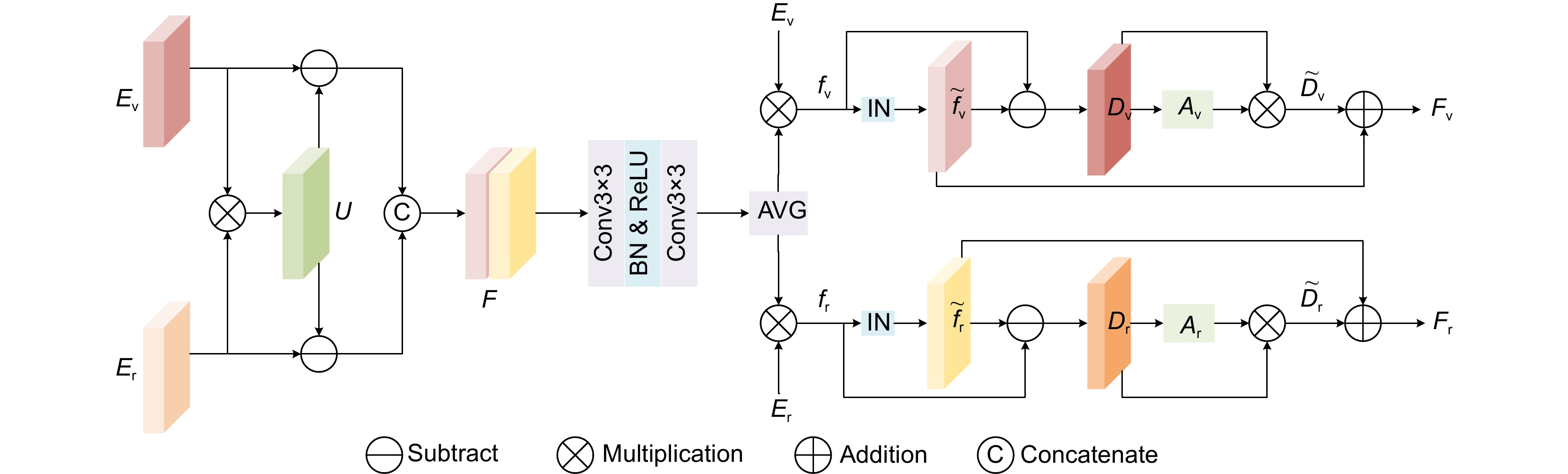
Figure 2.
Modal reweighted recovery module
-
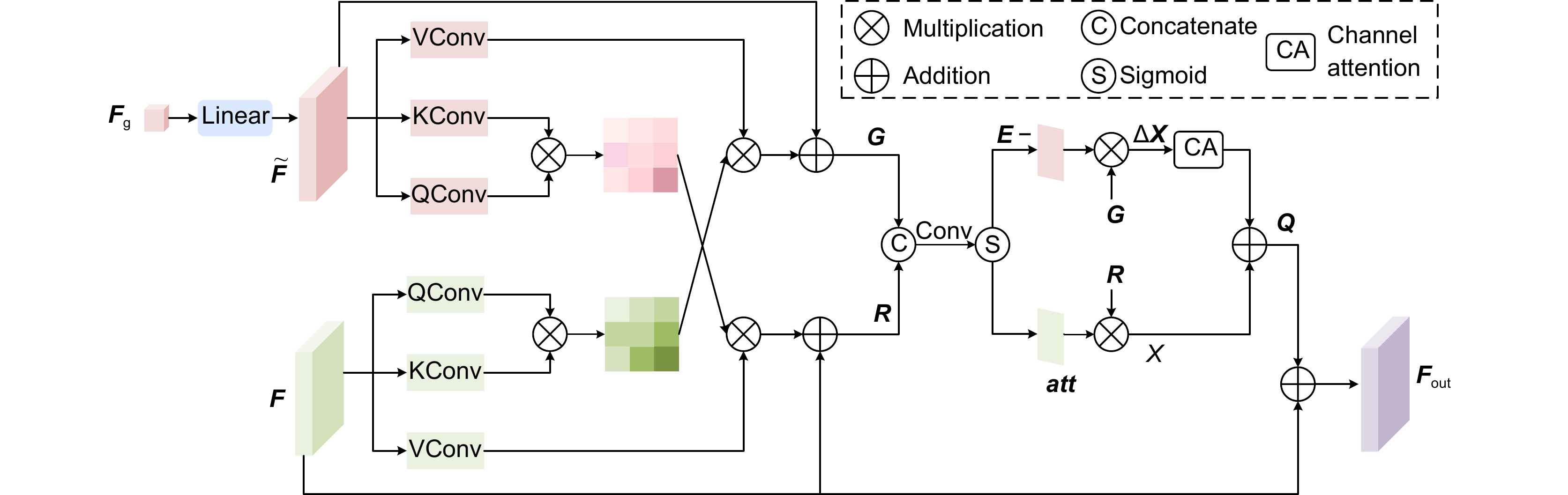
Figure 3.
Sub-critical features complementary module
-
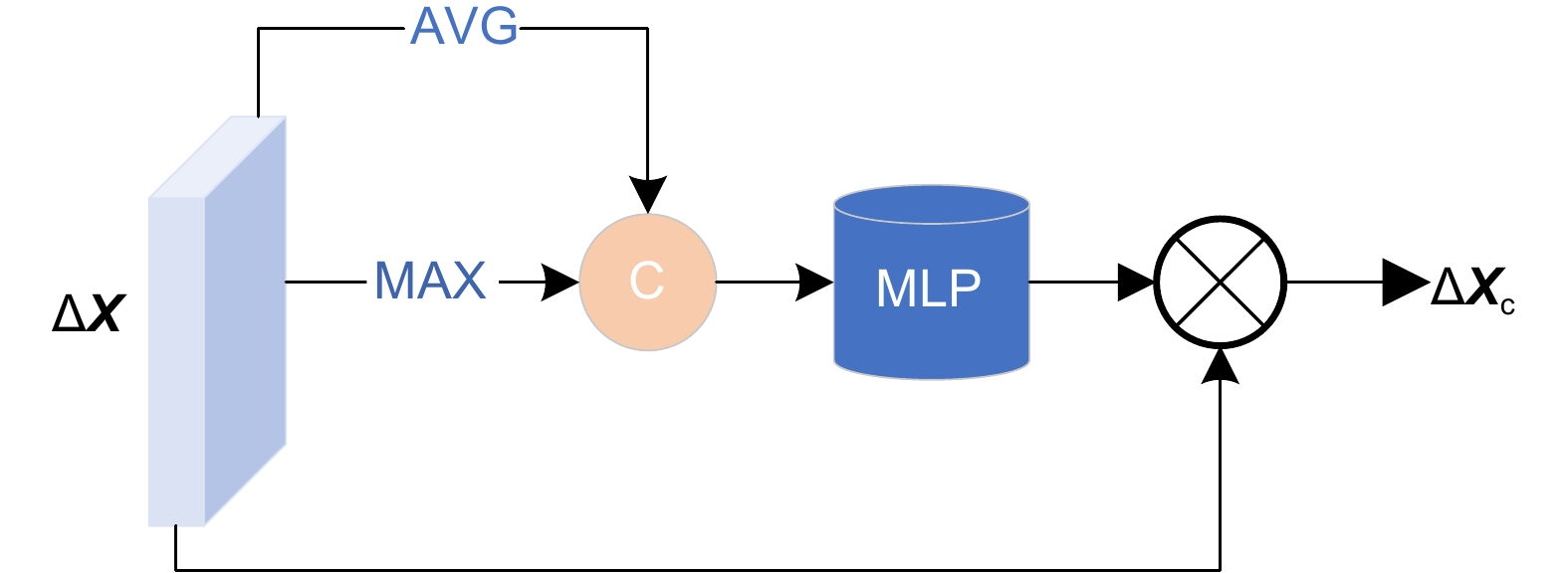
Figure 4.
Channel attention
-
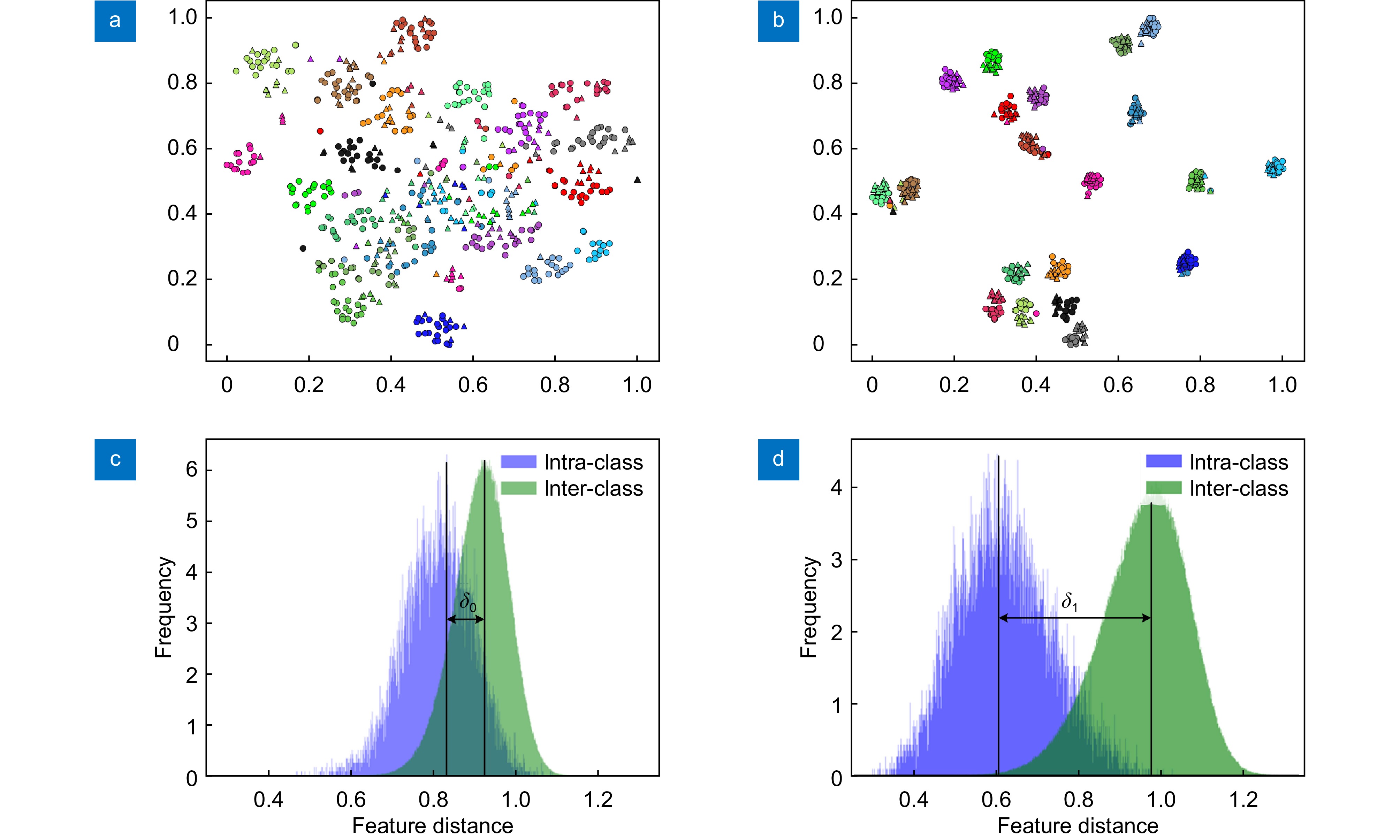
Figure 5.
Feature distribution diagram and intra-class and inter-class distances. (a) Baseline feature distribution diagram; (b) QFCNet feature distribution diagram; (c) Baseline intra-class and inter-class distances; (d) QFCNet intra-class and inter-class distances
-
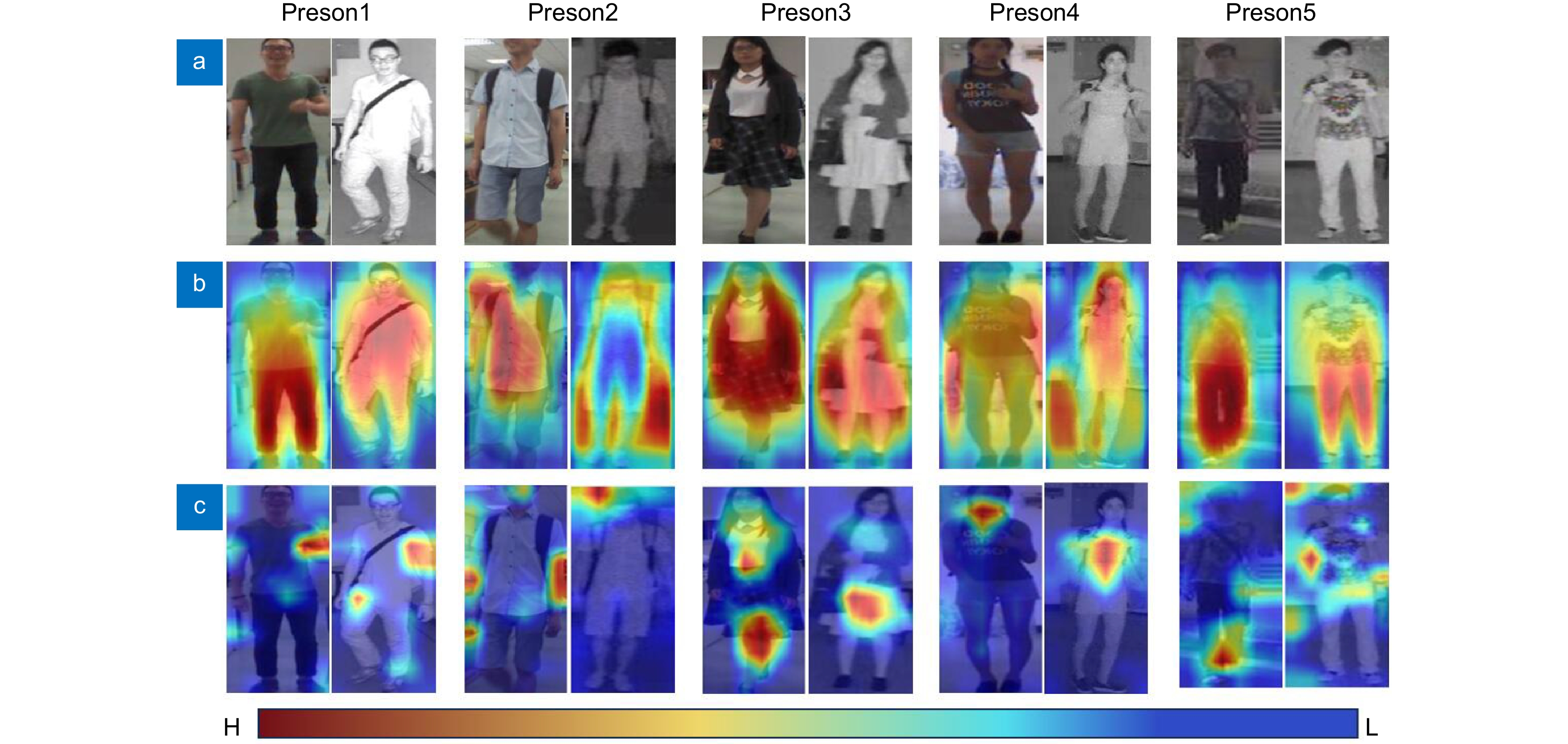
Figure 6.
Visualization of the heat map
-
Figure 7.
Visual sorting results on SYSU-MM01
- Figure .


