
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Zhang H M, Tian Q Q, Yan D D, et al. GLCrowd: a weakly supervised global-local attention model for congested crowd counting[J]. Opto-Electron Eng, 2024, 51(10): 240174. doi: 10.12086/oee.2024.240174

|
GLCrowd: a weakly supervised global-local attention model for congested crowd counting
-
Abstract
To address the challenges of crowd counting in dense scenes, such as complex backgrounds and scale variations, we propose a weakly supervised crowd counting model for dense scenes, named GLCrowd, which integrates global and local attention mechanisms. First, we design a local attention module combined with deep convolution to enhance local features through context weights while leveraging feature weight sharing to capture high-frequency local information. Second, the Vision Transformer (ViT) self-attention mechanism is used to capture low-frequency global information. Finally, the global and local attention mechanisms are effectively fused, and counting is accomplished through a regression token. The model was tested on the Shanghai Tech Part A, Shanghai Tech Part B, UCF-QNRF, and UCF_CC_50 datasets, achieving MAE values of 64.884, 8.958, 95.523, and 209.660, and MSE values of 104.411, 16.202, 173.453, and 282.217, respectively. The results demonstrate that the proposed GLCrowd model exhibits strong performance in crowd counting within dense scenes. -

-
References
[1] 田月媛, 邓淼磊, 高辉, 等. 基于深度学习的人群计数算法综述[J]. 电子测量技术, 2022, 45(7): 152−159. doi: 10.19651/j.cnki.emt.2108231 Tian Y Y, Deng M L, Gao H, et al. Review of crowd counting algorithms based on deep learning[J]. Electron Meas Technol, 2022, 45(7): 152−159. doi: 10.19651/j.cnki.emt.2108231 [2] Xiong H P, Lu H, Liu C X, et al. From open set to closed set: supervised spatial divide-and-conquer for object counting[J]. Int J Comput Vis, 2023, 131(7): 1722−1740. doi: 10.1007/s11263-023-01782-1 [3] Wu S K, Yang F Y. Boosting detection in crowd analysis via underutilized output features[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 15609–15618. https://doi.org/10.1109/CVPR52729.2023.01498. [4] Yu Y, Cai Z, Miao D Q, et al. An interactive network based on transformer for multimodal crowd counting[J]. Appl Intell, 2023, 53(19): 22602−22614. doi: 10.1007/s10489-023-04721-2 [5] Wang M J, Zhou J, Cai H, et al. CrowdMLP: weakly-supervised crowd counting via multi-granularity MLP[J]. Pattern Recognit, 2023, 144: 109830. doi: 10.1016/j.patcog.2023.109830 [6] 卢振坤, 刘胜, 钟乐, 等. 人群计数研究综述[J]. 计算机工程与应用, 2022, 58(11): 33−46. d. doi: 10.3778/j.issn.1002-8331.2111-0281 Lu Z K, Liu S, Zhong L, et al. Survey on reaserch of crowd counting[J]. Comput Eng Appl, 2022, 58(11): 33−46. doi: 10.3778/j.issn.1002-8331.2111-0281 [7] 郭爱心, 夏殷锋, 王大为, 等. 一种抗背景干扰的多尺度人群计数算法[J]. 计算机工程, 2022, 48(5): 251−257. doi: 10.19678/j.issn.1000-3428.0061423 Guo A X, Xia Y F, Wang D W, et al. A multi-scale crowd counting algorithm with removing background interference[J]. Comput Eng, 2022, 48(5): 251−257. doi: 10.19678/j.issn.1000-3428.0061423 [8] Zhang Q M, Xu Y F, Zhang J, et al. ViTAEv2: vision transformer advanced by exploring inductive bias for image recognition and beyond[J]. Int J Comput Vis, 2023, 131(5): 1141−1162. doi: 10.1007/s11263-022-01739-w [9] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 6000–6010. [10] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: transformers for image recognition at scale[C]//Proceedings of the 9th International Conference on Learning Representations, 2021. [11] Lin H, Ma Z H, Ji R R, et al. Boosting crowd counting via multifaceted attention[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 19628–19637. https://doi.org/10.1109/CVPR52688.2022.01901. [12] Liang D K, Xu W, Bai X. An end-to-end transformer model for crowd localization[C]//Proceedings of the 17th European Conference on Computer Vision, 2022: 38–54. https://doi.org/10.1007/978-3-031-19769-7_3. [13] Lin H, Ma Z H, Hong X P, et al. Gramformer: learning crowd counting via graph-modulated transformer[C]//Proceedings of the 38th AAAI Conference on Artificial Intelligence, 2024. https://doi.org/10.1609/aaai.v38i4.28126. [14] Li B, Zhang Y, Xu H H, et al. CCST: crowd counting with swin transformer[J]. Vis Comput, 2023, 39(7): 2671−2682. doi: 10.1007/s00371-022-02485-3 [15] Wang F S, Liu K, Long F, et al. Joint CNN and Transformer Network via weakly supervised Learning for efficient crowd counting[Z]. arXiv: 2203.06388, 2022. https://arxiv.org/abs/2203.06388. [16] Wang C A, Song Q Y, Zhang B S, et al. Uniformity in heterogeneity: diving deep into count interval partition for crowd counting[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 2021: 3234–3242. https://doi.org/10.1109/ICCV48922.2021.00322. [17] Song Q Y, Wang C A, Jiang Z K, et al. Rethinking counting and localization in crowds: a purely point-based framework[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 2021: 3365–3374. https://doi.org/10.1109/ICCV48922.2021.00335. [18] Shivapuja S V, Khamkar M P, Bajaj D, et al. Wisdom of (binned) crowds: a bayesian stratification paradigm for crowd counting[C]//Proceedings of the 29th ACM International Conference on Multimedia, 2021: 3574–3582. https://doi.org/10.1145/3474085.3475522. [19] Wang X Y, Zhang B F, Yu L M, et al. Hunting sparsity: density-guided contrastive learning for semi-supervised semantic segmentation[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 3114–3123. https://doi.org/10.1109/CVPR52729.2023.00304. [20] Lin W, Chan A B. Optimal transport minimization: crowd localization on density maps for semi-supervised counting[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 21663–21673. https://doi.org/10.1109/CVPR52729.2023.02075. [21] Gao H, Zhao W J, Zhang D X, et al. Application of improved transformer based on weakly supervised in crowd localization and crowd counting[J]. Sci Rep, 2023, 13(1): 1144. doi: 10.1038/s41598-022-27299-0 [22] Liu Y T, Wang Z, Shi M J, et al. Discovering regression-detection bi-knowledge transfer for unsupervised cross-domain crowd counting[J]. Neurocomputing, 2022, 494: 418−431. doi: 10.1016/j.neucom.2022.04.107 [23] Xu C F, Liang D K, Xu Y C, et al. AutoScale: learning to scale for crowd counting[J]. Int J Comput Vis, 2022, 130(2): 405−434. doi: 10.1007/s11263-021-01542-z [24] Liang D K, Xie J H, Zou Z K, et al. CrowdCLIP: unsupervised crowd counting via vision-language model[C]//Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 2893–2903. https://doi.org/10.1109/CVPR52729.2023.00283. [25] Zhang C Y, Zhang Y, Li B, et al. CrowdGraph: weakly supervised crowd counting via pure graph neural network[J]. ACM Trans Multimedia Comput, Commun Appl, 2024, 20(5): 135. doi: 10.1145/3638774 [26] Yang Y F, Li G R, Wu Z, et al. Weakly-supervised crowd counting learns from sorting rather than locations[C]// Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, 2020: 1–17. https://doi.org/10.1007/978-3-030-58598-3_1. [27] Liu Y T, Ren S C, Chai L Y, et al. Reducing spatial labeling redundancy for active semi-supervised crowd counting[J]. IEEE Trans Pattern Anal Mach Intell, 2022, 45(7): 9248−9255. doi: 10.1109/TPAMI.2022.3232712 [28] Deng M F, Zhao H L, Gao M. CLFormer: a unified transformer-based framework for weakly supervised crowd counting and localization[J]. Vis Comput, 2024, 40(2): 1053−1067. doi: 10.1007/s00371-023-02831-z [29] Liang D K, Chen X W, Xu W, et al. TransCrowd: weakly-supervised crowd counting with transformers[J]. Sci China Inf Sci, 2022, 65(6): 160104. doi: 10.1007/s11432-021-3445-y [30] Sun G L, Liu Y, Probst T, et al. Rethinking global context in crowd counting[Z]. arXiv: 2105.10926, 2021. https://arxiv.org/abs/2105.10926. [31] Tian Y, Chu X X, Wang H P. CCTrans: simplifying and improving crowd counting with transformer[Z]. arXiv: 2109.14483, 2021. https://arxiv.org/abs/2109.14483. [32] Chen X S, Lu H T. Reinforcing local feature representation for weakly-supervised dense crowd counting[Z]. arXiv: 2202.10681, 2022. https://arxiv.org/abs/2202.10681v1. [33] Gao J Y, Gong M G, Li X L. Congested crowd instance localization with dilated convolutional swin transformer[J]. Neurocomputing, 2022, 513: 94−103. doi: 10.1016/j.neucom.2022.09.113 [34] Wang F S, Sang J, Wu Z Y, et al. Hybrid attention network based on progressive embedding scale-context for crowd counting[J]. Inf Sci, 2022, 591: 306−318. doi: 10.1016/j.ins.2022.01.046 [35] Yang S P, Guo W Y, Ren Y H. CrowdFormer: an overlap patching vision transformer for top-down crowd counting[C]// Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, 2022: 23–29. https://doi.org/10.24963/ijcai.2022/215. [36] Zhang Y Y, Zhou D S, Chen S Q, et al. Single-image crowd counting via multi-column convolutional neural network[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 589–597. https://doi.org/10.1109/CVPR.2016.70. [37] Idrees H, Tayyab M, Athrey K, et al. Composition loss for counting, density map estimation and localization in dense crowds[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 532–546. https://doi.org/10.1007/978-3-030-01216-8_33. [38] Idrees H, Saleemi I, Seibert C, et al. Multi-source multi-scale counting in extremely dense crowd images[C]//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition, 2013: 2547–2554. https://doi.org/10.1109/CVPR.2013.329. [39] Patwal A, Diwakar M, Tripathi V, et al. Crowd counting analysis using deep learning: a critical review[J]. Proc Comput Sci, 2023, 218: 2448−2458. doi: 10.1016/j.procs.2023.01.220 [40] Chen Y Q, Zhao H L, Gao M, et al. A weakly supervised hybrid lightweight network for efficient crowd counting[J]. Electronics, 2024, 13(4): 723. doi: 10.3390/electronics13040723 [41] Lei Y J, Liu Y, Zhang P P, et al. Towards using count-level weak supervision for crowd counting[J]. Pattern Recognit, 2021, 109: 107616. doi: 10.1016/j.patcog.2020.107616 [42] Meng Y D, Zhang H R, Zhao Y T, et al. Spatial uncertainty-aware semi-supervised crowd counting[C]//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision, 2021: 15549–15559. https://doi.org/10.1109/ICCV48922.2021.01526. [43] Liang L J, Zhao H L, Zhou F B, et al. PDDNet: lightweight congested crowd counting via pyramid depth-wise dilated convolution[J]. Appl Intell, 2023, 53(9): 10472−10484. doi: 10.1007/S10489-022-03967-6 [44] Sindagi V A, Yasarla R, Babu D S, et al. Learning to count in the crowd from limited labeled data[C]//Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, 2020: 212–229. https://doi.org/10.1007/978-3-030-58621-8_13. [45] Wang Q, Gao J Y, Lin W, et al. Learning from synthetic data for crowd counting in the wild[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 8198–8207. https://doi.org/10.1109/CVPR.2019.00839. [46] Liu W Z, Durasov N, Fua P. Leveraging self-supervision for cross-domain crowd counting[C]//Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022: 5341–5352. https://doi.org/10.1109/CVPR52688.2022.00527. [47] Savner S S, Kanhangad V. CrowdFormer: weakly-supervised crowd counting with improved generalizability[J]. J Vis Commun Image Representation, 2023, 94: 103853. doi: 10.1016/j.jvcir.2023.103853 [48] Li Y C, Jia R S, Hu Y X, et al. A weakly-supervised crowd density estimation method based on two-stage linear feature calibration[J]. IEEE/CAA J Autom Sin, 2024, 11(4): 965−981. doi: 10.1109/JAS.2023.123960 -
Overview
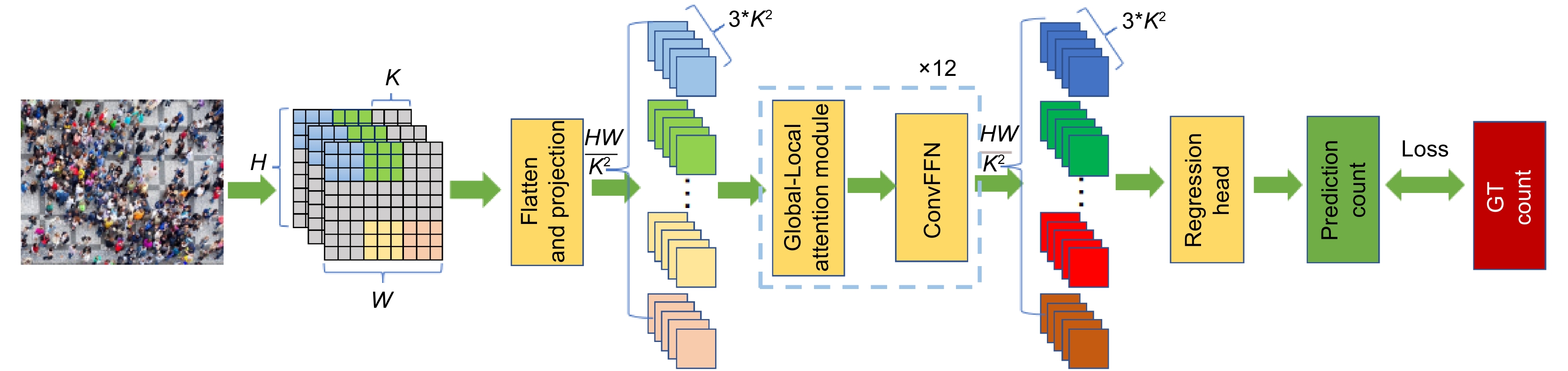
Crowd counting aims to estimate the number of people in an image using computer algorithms and has wide applications in public safety, urban planning, advertising, and tourism management. However, counting in dense crowds still faces significant challenges due to complex backgrounds and scale variations. Vision Transformer (ViT) offers superior information processing capabilities compared to convolutional neural networks (CNNs), but it falls short in detail capture compared to traditional CNNs, limiting its performance in dense scenarios. To address this issue and reduce reliance on extensive annotated data, this paper proposes a weakly supervised crowd counting method based on a Transformer with a combination of global and local attention mechanisms. The approach aims to leverage the complementary strengths of both global and local attention to enhance crowd counting performance.
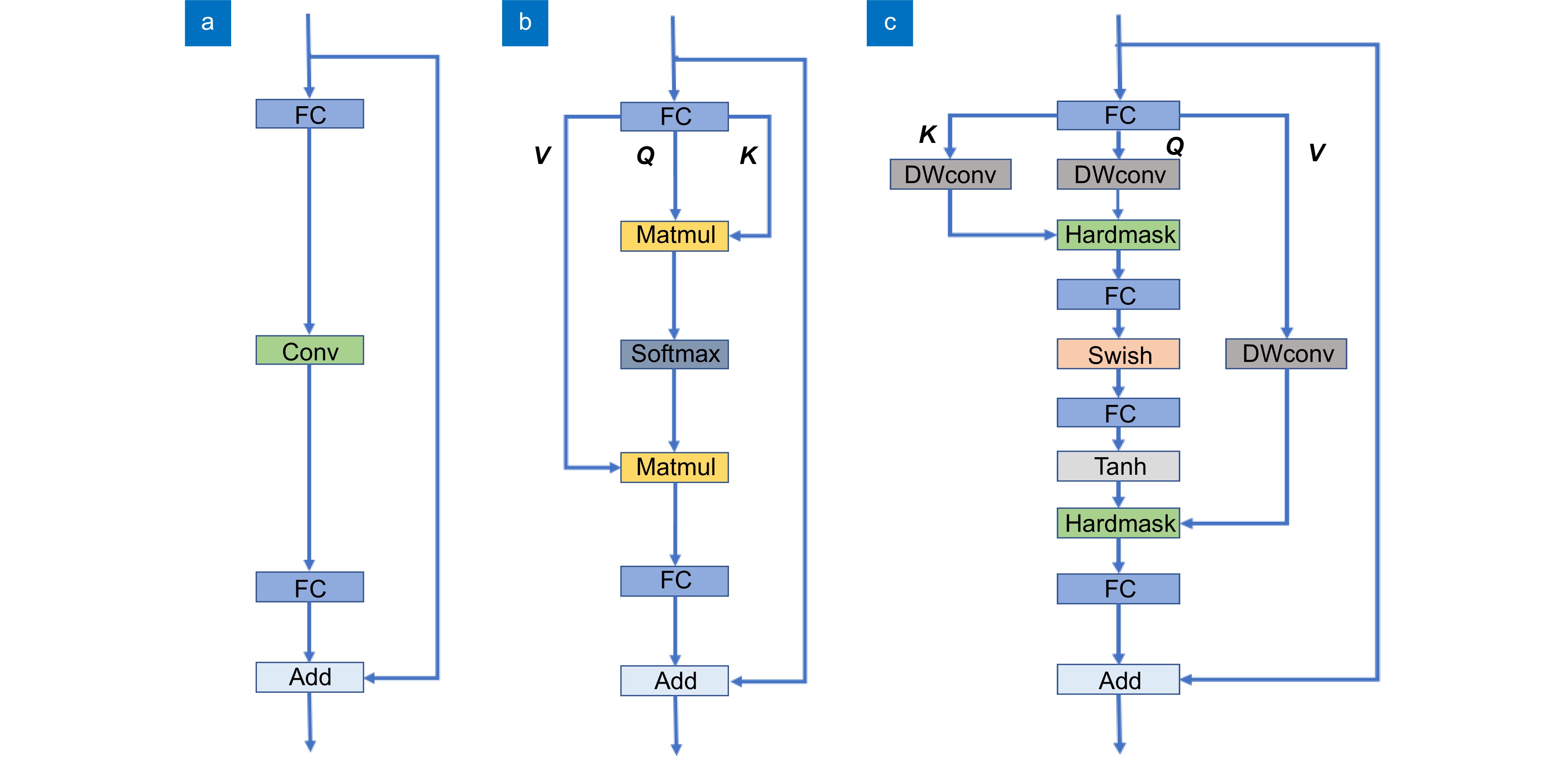
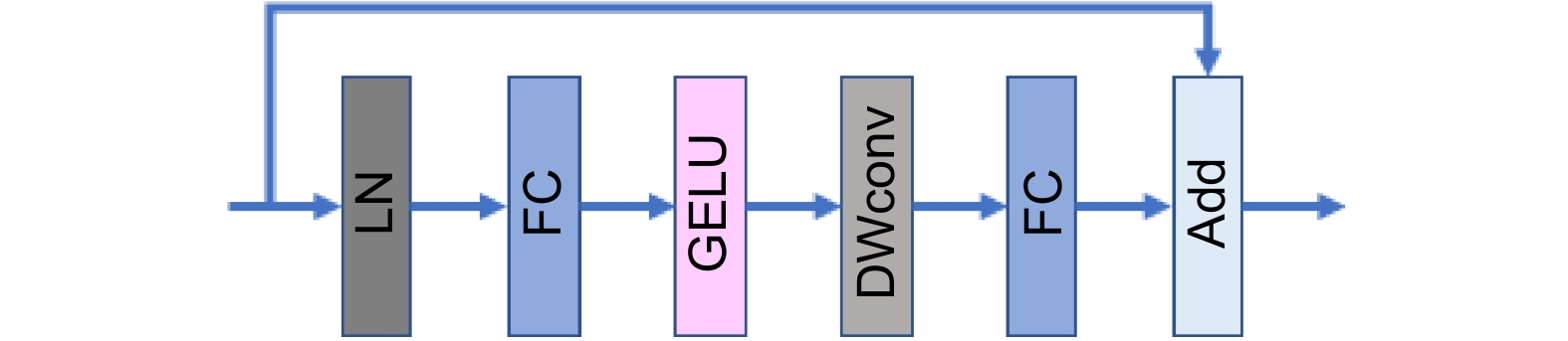
First, the Vision Transformer’s self-attention captures global features, focusing on low-frequency global information to understand the overall context and background layout of the image. Next, local attention captures high-frequency local information, using depthwise convolution (DWconv) to aggregate local features from the values (V). Depthwise convolution is also applied to queries (Q) and keys (K), and attention maps are generated through the Hadamard product and Tanh function. This approach aims to achieve higher-quality contextual weights with stronger nonlinearity for identifying specific objects and detailed features in the image. Global and local attention outputs are then concatenated along the channel dimension. To integrate local information into the feed-forward network (FFN), the paper replaces the original FFN in ViT with a feed-forward network that includes DWconv. Finally, a regression head is used to complete the crowd counting task.
The proposed model was validated on the Shanghai Tech, UCF-QNRF, and UCF_CC_50 datasets and compared with current mainstream weakly supervised crowd counting models. On the Shanghai Tech Part A dataset, the proposed model improved MAE by 1.2 and MSE by 0.7 compared to the second-best model, Transcrowd_gap. Although the OT_M model showed slight advantages in Shanghai Tech Part B, this is mainly because OT_M uses point annotations. The proposed model uses coarse annotations that only provide the total number of people in the image. On the UCF_QNRF dataset, the proposed model improved MAE by 1.7 compared to Transcrowd_gap. On the UCF_CC_50 dataset, the proposed model achieved a 9.2 improvement in MAE and a significant 48.2 improvement in MSE compared to the CrowdFormer model. These results demonstrate that the proposed network model outperforms other mainstream models in weakly supervised crowd counting.
-
Access History
Figures(6)
Tables(7)
Article Metrics


Export File
Citation
Zhang H M, Tian Q Q, Yan D D, et al. GLCrowd: a weakly supervised global-local attention model for congested crowd counting[J]. Opto-Electron Eng, 2024, 51(10): 240174. doi: 10.12086/oee.2024.240174
Format
Content
 DownLoad:
DownLoad:


-
Figure 1.
GLCrowd network structure
-
Figure 2.
Global-local attention module
-
Figure 3.
Comparison of different methods. (a) Traditional convolution; (b) Standard self-attention; (c) Local attention
-
Figure 4.
ConvFFN moudle
-
Figure 5.
Partial visualization results
- Figure .


