
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Liu Z M, Yang F J, Hu W J. Multi-scale feature interaction pseudo-label unsupervised domain adaptation for person re-identification[J]. Opto-Electron Eng, 2025, 52(1): 240238. doi: 10.12086/oee.2025.240238

|
Multi-scale feature interaction pseudo-label unsupervised domain adaptation for person re-identification
-
Abstract
To address issues of insufficient receptive fields and weak connections between global and local features in unsupervised domain adaptive person re-identification, a multi-scale feature interaction method was proposed. Firstly, the feature squeeze attention mechanism compressed image features, which were then fed into the network to enhance rich local information representation. Secondly, the residual feature interaction module encoded global information into the features by interaction, while increasing the model's receptive field and enhancing its ability to extract pedestrian features. Finally, a bottleneck module based on partial convolution conducted convolution operations on the part of the input channels, reducing redundant computations and improving spatial feature extraction efficiency. Experimental results on three adaptation datasets demonstrate that the method mAP reached 82.9%, 68.7%, and 26.6%, the Rank-1 reached 93.7%, 82.7%, and 54.7%, the Rank-5 reached 97.4%, 89.9%, and 67.5%, by comparison with baseline, respectively, demonstrating that the proposed method allows for better pedestrian features representation and improved recognition accuracy. -

-
References
[1] Wei L H, Zhang S L, Gao W, et al. Person transfer GAN to bridge domain gap for person re-identification[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 79–88. https://doi.org/10.1109/CVPR.2018.00016. [2] Deng W J, Zheng L, Ye Q X, et al. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identification[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 994–1003. https://doi.org/10.1109/CVPR.2018.00110. [3] Fu Y, Wei Y C, Wang G S, et al. Self-similarity grouping: a simple unsupervised cross domain adaptation approach for person re-identification[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 6112–6121. https://doi.org/10.1109/ICCV.2019.00621. [4] Ge Y X, Chen D P, Li H S. Mutual mean-teaching: pseudo label refinery for unsupervised domain adaptation on person re-identification[C]//Proceedings of the 8th International Conference on Learning Representations, 2020. [5] He T, Shen L Q, Guo Y C, et al. SECRET: self-consistent pseudo label refinement for unsupervised domain adaptive person re-identification[C]//Proceedings of the 36th AAAI Conference on Artificial Intelligence, 2022: 879–887. https://doi.org/10.1609/aaai.v36i1.19970. [6] Ye M, Ma A J, Zheng L, et al. Dynamic label graph matching for unsupervised video re-identification[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 5142–5150. https://doi.org/10.1109/ICCV.2017.550. [7] Fan H H, Zheng L, Yan C G, et al. Unsupervised person re-identification: clustering and fine-tuning[J]. ACM Trans Multimedia Comput Commun Appl, 2018, 14(4): 83. doi: 10.1145/3243316 [8] Yu H X, Zheng W S, Wu A C, et al. Unsupervised person re-identification by soft multilabel learning[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 2148–2157. https://doi.org/10.1109/CVPR.2019.00225. [9] Yang Q Z, Yu H X, Wu A C, et al. Patch-based discriminative feature learning for unsupervised person re-identification[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 3633–3642. https://doi.org/10.1109/CVPR.2019.00375. [10] Xuan S Y, Zhang S L. Intra-inter camera similarity for unsupervised person re-identification[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 11926–11935. https://doi.org/10.1109/CVPR46437.2021.01175. [11] Han X M, Yu X H, Li G R, et al. Rethinking sampling strategies for unsupervised person re-identification[J]. IEEE Trans Image Process, 2023, 32: 29−42. doi: 10.1109/TIP.2022.3224325 [12] Chen S N, Fan Z Y, Yin J Y. Pseudo label based on multiple clustering for unsupervised cross-domain person re-identification[J]. IEEE Signal Process Lett, 2020, 27: 1460−1464. doi: 10.1109/LSP.2020.3016528 [13] Li J N, Zhang S L. Joint visual and temporal consistency for unsupervised domain adaptive person re-identification[C]//Proceedings of the 16th European Conference on Computer Vision–ECCV 2020, 2020: 483–499. https://doi.org/10.1007/978-3-030-58586-0_29. [14] Yu S M, Wang S J. Consistency mean-teaching for unsupervised domain adaptive person re-identification[C]//Proceedings of the 2022 5th International Conference on Image and Graphics Processing, 2022: 159–166. https://doi.org/10.1145/3512388.3512451. [15] Chen Z Q, Cui Z C, Zhang C, et al. Dual clustering co-teaching with consistent sample mining for unsupervised person re-identification[J]. IEEE Trans Circuits Syst Video Technol, 2023, 33(10): 5908−5920. doi: 10.1109/TCSVT.2023.3261898 [16] Song H, Kim M, Park D, et al. Learning from noisy labels with deep neural networks: a survey[J]. IEEE Trans Neural Netw Learn Syst, 2023, 34(11): 8135−8153. doi: 10.1109/TNNLS.2022.3152527 [17] Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, 1996: 226–231. [18] Jaderberg M, Simonyan K, Zisserman A, et al. Spatial transformer networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 2017–2025. [19] Hendrycks D, Gimpel K. Gaussian error linear units (GELUs)[Z]. arXiv: 1606.08415, 2016. https://arxiv.org/abs/1606.08415. [20] El-Nouby A, Touvron H, Caron M, et al. XCiT: cross-covariance image transformers[C]//Proceedings of the 35th International Conference on Neural Information Processing Systems, 2021: 1531. [21] Ba J L, Kiros J R, Hinton G E. Layer normalization[Z]. arXiv: 1607.06450, 2016. https://arxiv.org/abs/1607.06450. [22] Mao A Q, Mohri M, Zhong Y T. Cross-entropy loss functions: theoretical analysis and applications[C]//Proceedings of the 40th International Conference on Machine Learning, 2023. [23] Schroff F, Kalenichenko D, Philbin J. FaceNet: a unified embedding for face recognition and clustering[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 815–823. https://doi.org/10.1109/CVPR.2015.7298682. [24] Zheng L, Shen L Y, Tian L, et al. Scalable person re-identification: a benchmark[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, 2015: 1116–1124. https://doi.org/10.1109/ICCV.2015.133. [25] Ristani E, Solera F, Zou R, et al. Performance measures and a data set for multi-target, multi-camera tracking[C]//Proceedings of the European Conference on Computer Vision, 2016: 17–35. https://doi.org/10.1007/978-3-319-48881-3_2. [26] Zhong Z, Zheng L, Kang G L, et al. Random erasing data augmentation[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence, 2020: 13001–13008. https://doi.org/10.1609/aaai.v34i07.7000. [27] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7132–7141. https://doi.org/10.1109/CVPR.2018.00745. [28] Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 3–19. https://doi.org/10.1007/978-3-030-01234-2_1. [29] Hou Q B, Zhou D Q, Feng J S. Coordinate attention for efficient mobile network design[C]//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021: 13713–13722. https://doi.org/10.1109/CVPR46437.2021.01350. [30] Zhong Z, Zheng L, Li S Z, et al. Generalizing a person retrieval model hetero-and homogeneously[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 172–188. https://doi.org/10.1007/978-3-030-01261-8_11. [31] Zhong Z, Zheng L, Luo Z M, et al. Invariance matters: exemplar memory for domain adaptive person re-identification[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 598–607. https://doi.org/10.1109/CVPR.2019.00069. [32] Zhang S A, Hu H F. Unsupervised person re-identification using unified domanial learning[J]. Neural Process Lett, 2023, 55(6): 6887−6905. doi: 10.1007/s11063-023-11242-z [33] Li Y J, Lin C S, Lin Y B, et al. Cross-dataset person re-identification via unsupervised pose disentanglement and adaptation[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 7919–7929. https://doi.org/10.1109/ICCV.2019.00801. [34] Zhang X Y, Cao J W, Shen C H, et al. Self-training with progressive augmentation for unsupervised cross-domain person re-identification[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 8222–8231. https://doi.org/10.1109/ICCV.2019.00831. [35] Wang D K, Zhang S L. Unsupervised person re-identification via multi-label classification[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 10981–10990. https://doi.org/10.1109/CVPR42600.2020.01099. [36] Jin X, Lan C L, Zeng W J, et al. Style normalization and restitution for generalizable person re-identification[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 3143–3152. https://doi.org/10.1109/CVPR42600.2020.00321. [37] Zhong Z, Zheng L, Luo Z M, et al. Learning to adapt invariance in memory for person re-identification[J]. IEEE Trans Pattern Anal Mach Intell, 2021, 43(8): 2723−2738. doi: 10.1109/TPAMI.2020.2976933 [38] Zhai Y P, Lu S J, Ye Q X, et al. AD-cluster: augmented discriminative clustering for domain adaptive person re-identification[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 9021–9030. https://doi.org/10.1109/CVPR42600.2020.00904. [39] Zhai Y P, Ye Q X, Lu S J, et al. Multiple expert brainstorming for domain adaptive person re-identification[C]//Proceedings of the 16th European Conference on Computer Vision, 2020: 594–611. https://doi.org/10.1007/978-3-030-58571-6_35. [40] Chen H, Wang Y H, Lagadec B, et al. Learning invariance from generated variance for unsupervised person re-identification[J]. IEEE Trans Pattern Anal Mach Intell, 2023, 45(6): 7494−7508. doi: 10.1109/TPAMI.2022.3226866 [41] Zheng K C, Lan C L, Zeng W J, et al. Exploiting sample uncertainty for domain adaptive person re-identification[C]//Proceedings of the 35th AAAI Conference on Artificial Intelligence, 2021: 3538–3546. https://doi.org/10.1609/aaai.v35i4.16468. [42] Li Y F, Zhu X D, Sun J, et al. Unsupervised person re-identification based on high-quality pseudo labels[J]. Appl Intell, 2023, 53(12): 15112−15126. doi: 10.1007/s10489-022-04270-0 [43] Zhao Y, Shu Q Y, Shi X, et al. Unsupervised person re-identification by dynamic hybrid contrastive learning[J]. Image Vis Comput, 2023, 137: 104786. doi: 10.1016/j.imavis.2023.104786 -
Overview
Person re-identification (ReID) is a computer vision task that matches target persons from images or video sequences and has wide application prospects. Although supervised ReID methods have achieved excellent performance on single-domain datasets by introducing deep learning technologies, they are difficult to apply directly to real scenarios because of the time-consuming and labor-intensive process of collecting and annotating pedestrian images. Furthermore, domain gaps between different datasets significantly degrade the recognition performance of these models. Due to these challenges, unsupervised domain adaptation (UDA) methods have been introduced to the ReID field to reduce the dependency on labeled datasets and enhance generalizability across domains. UDA ReID aims to leverage labeled source domain data to improve model performance on unlabeled target domains. Currently, there are roughly two ways to tackle the problem: generative-based and pseudo-label clustering-based methods. Generative methods mainly use generative adversarial networks to construct new images that bridge domain gaps between datasets or cameras. However, the unstable training process of generative adversarial networks often results in unrealistic or noisy images. In contrast, clustering-based methods employ clustering algorithms or strategies to generate pseudo-labels for target domain data, enabling supervised training. These methods are relatively straightforward in design and achieve outstanding performance among various UDA approaches. Nevertheless, existing clustering-based ReID methods face challenges such as limited receptive fields and weak connections between global and local features, leading to suboptimal feature extraction and recognition accuracy. To address this issue, we propose a multi-scale feature interaction method, which can fully extract features and effectively improve the recognition accuracy. First, the feature squeeze attention mechanism compresses input features along horizontal and vertical axes, enhancing local detail extraction while aggregating global features. Second, the residual feature interaction module expands the receptive field through multi-scale interactions and encodes global contextual information into features, strengthening connections between global and local features. Third, the partial convolution bottleneck module selectively applies convolution operations to a subset of input channels, reducing redundant computations while preserving spatial feature information. The method proposed in this paper was validated on three public datasets, and the results showed that the performance has been significantly improved compared to the baseline method. This method achieved the mAP (mean average precision) of 82.9%, Rank-1 accuracy of 93.7% on the Market-1501 dataset, mAP of 68.7%, and Rank-1 accuracy of 82.7% on the DukeMTMC-reID dataset, and the mAP of 26.6% and Rank-1 accuracy of 54.7% on the MSMT17 dataset. Ablation studies further confirm the independent contributions of various modules and the significant enhancements in feature extraction and computational efficiency achieved by their integration. These results demonstrate its superiority by extracting comprehensive multi-scale features and improving cross-domain recognition accuracy.
-
Access History
Figures(8)
Tables(6)
Article Metrics


Export File
Citation
Liu Z M, Yang F J, Hu W J. Multi-scale feature interaction pseudo-label unsupervised domain adaptation for person re-identification[J]. Opto-Electron Eng, 2025, 52(1): 240238. doi: 10.12086/oee.2025.240238
Format
Content
 DownLoad:
DownLoad:



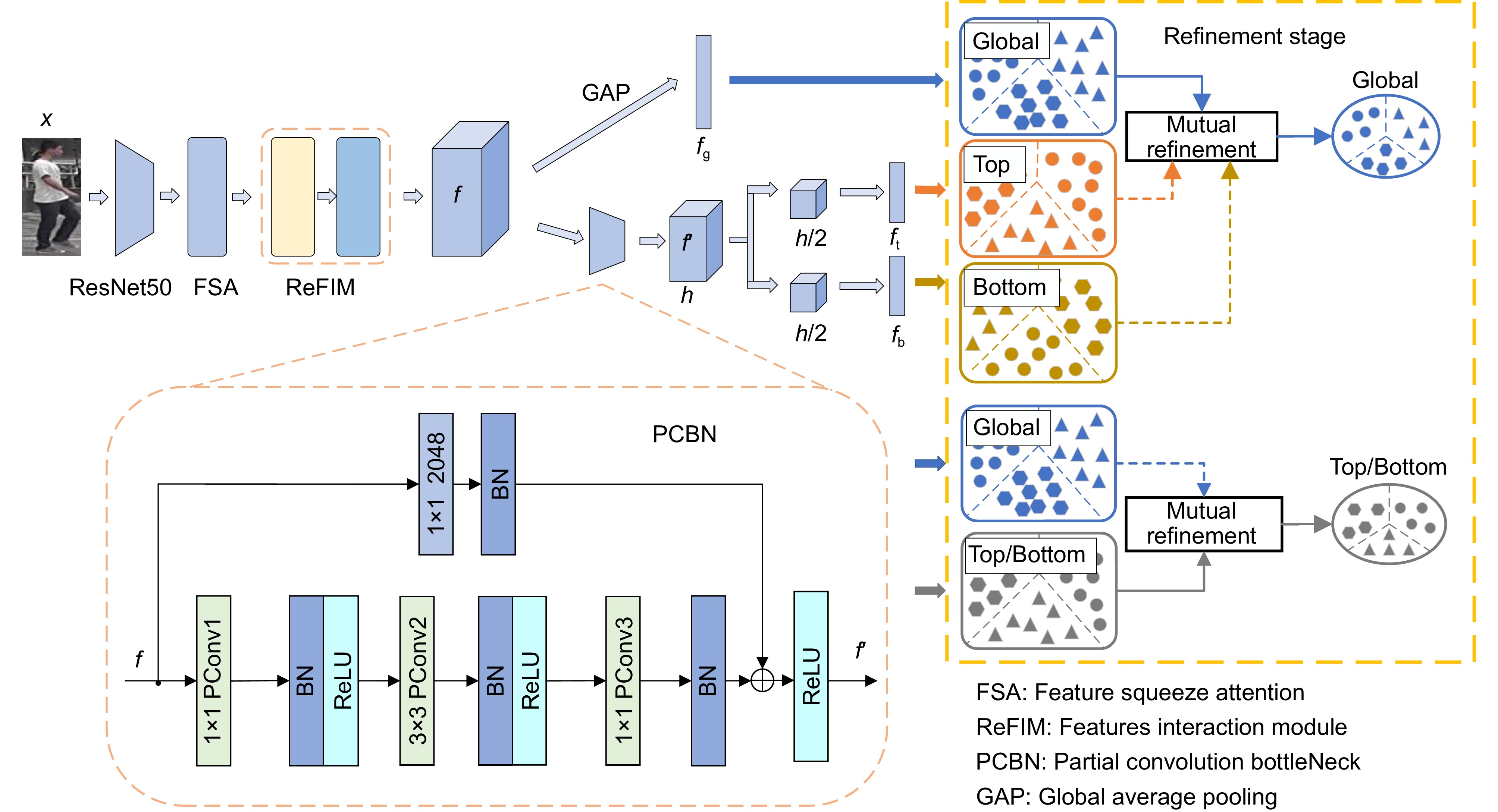
-
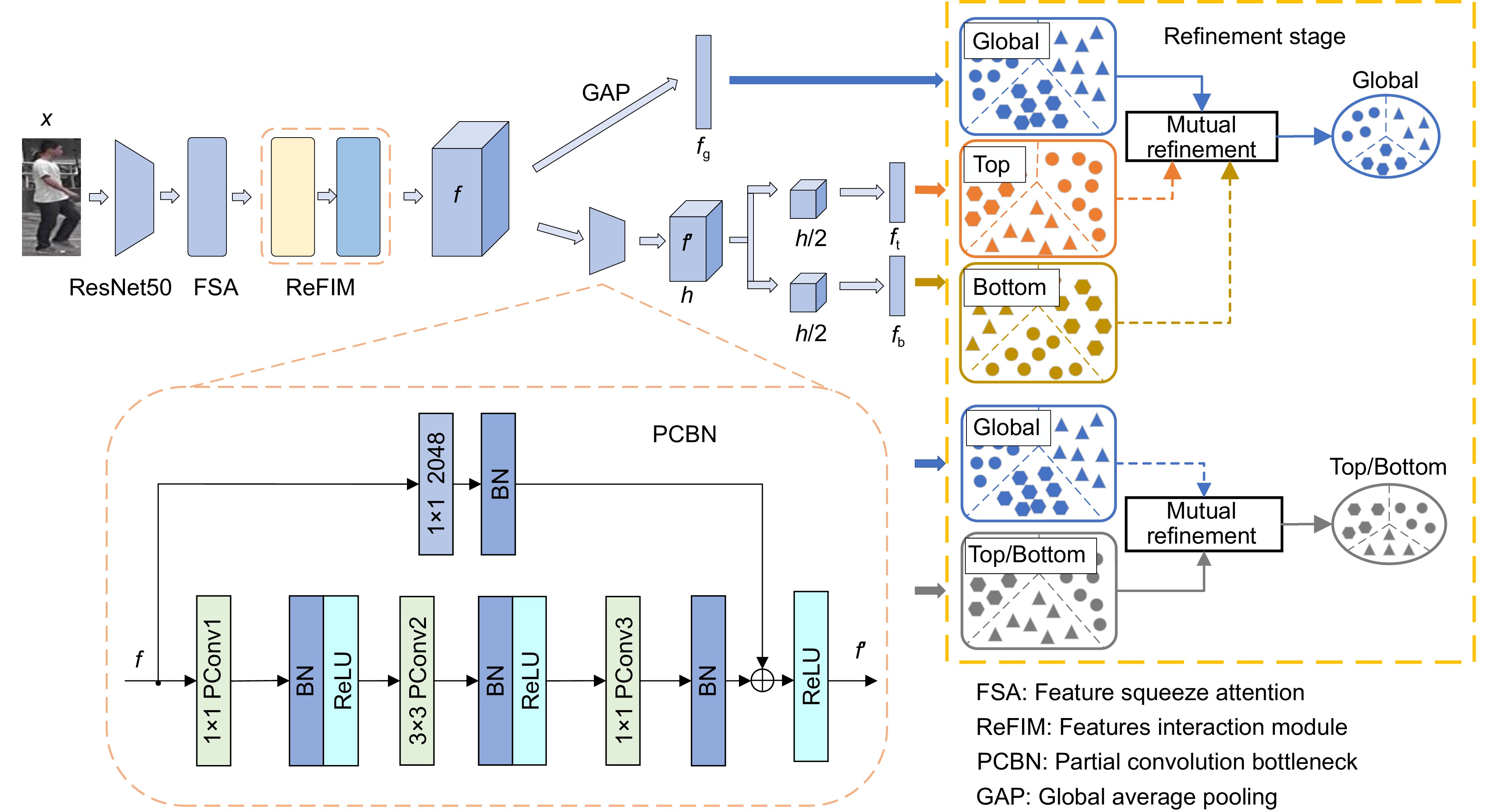
Figure 1.
Overall framework of the MSFINet model
-
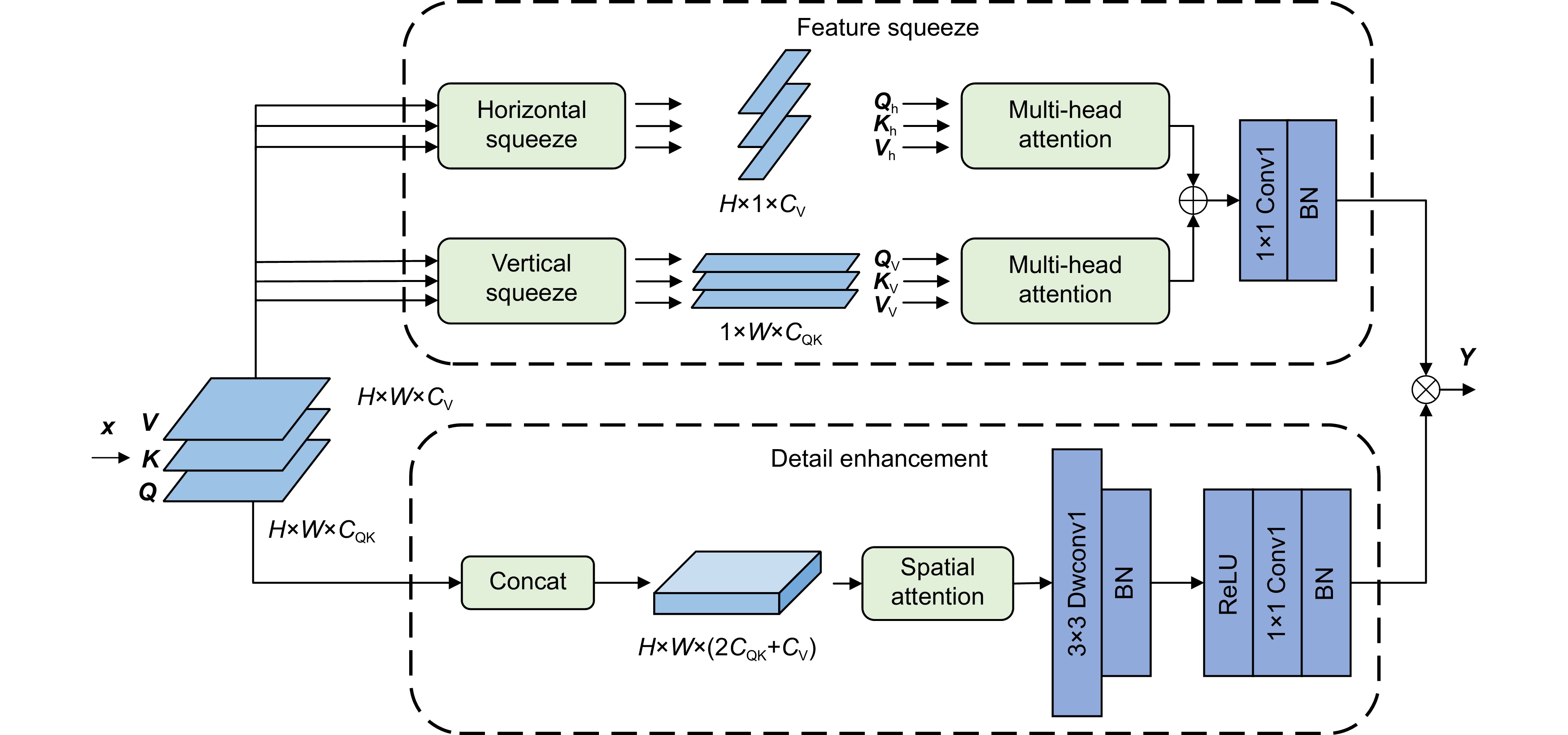
Figure 2.
FSA mechanism
-
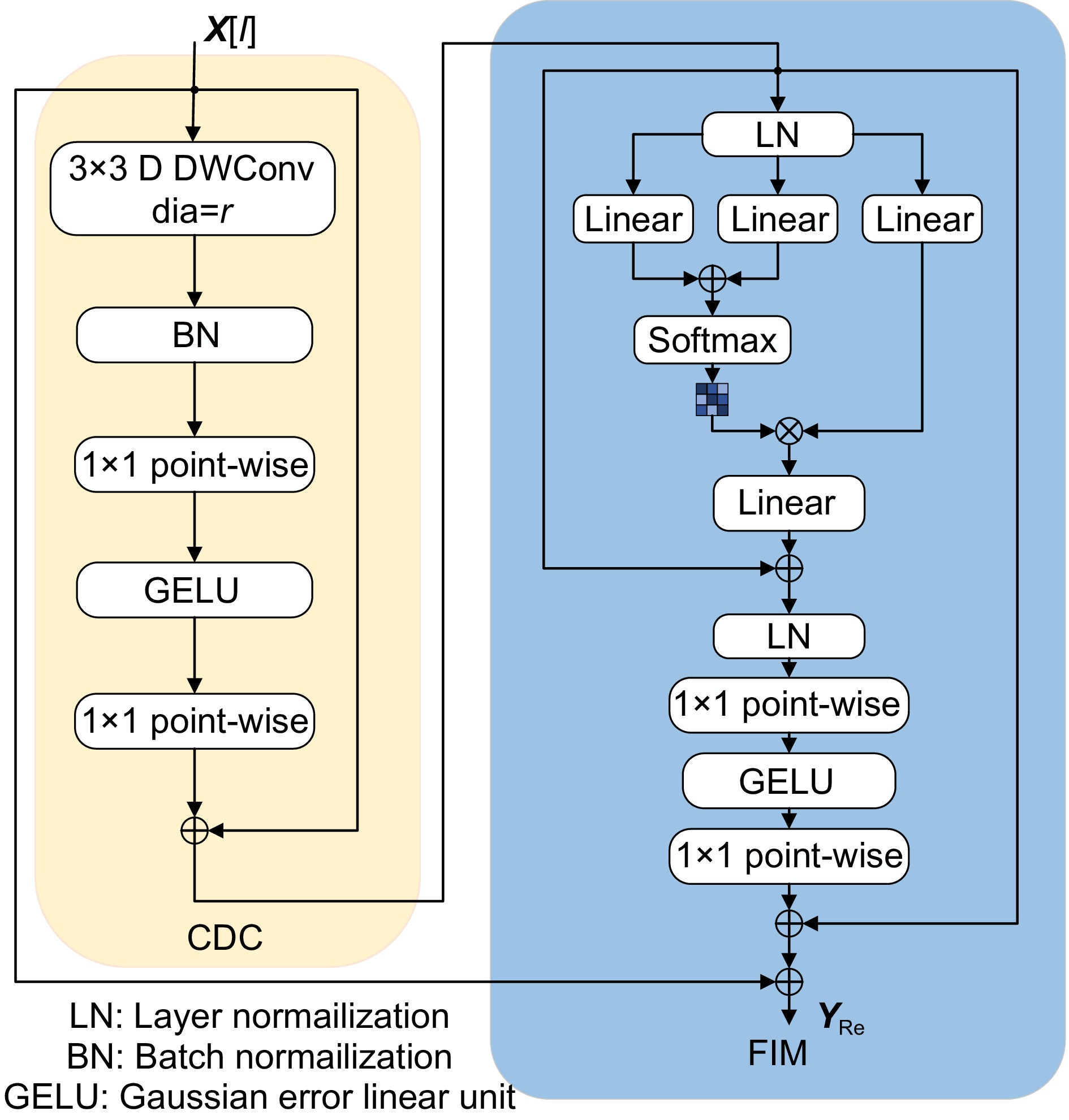
Figure 3.
Framework of the ReFIM
-
Figure 4.
Structure of PCBN module
-
Figure 5.
Partial convolution ablation experiment results of the PCBN module
-
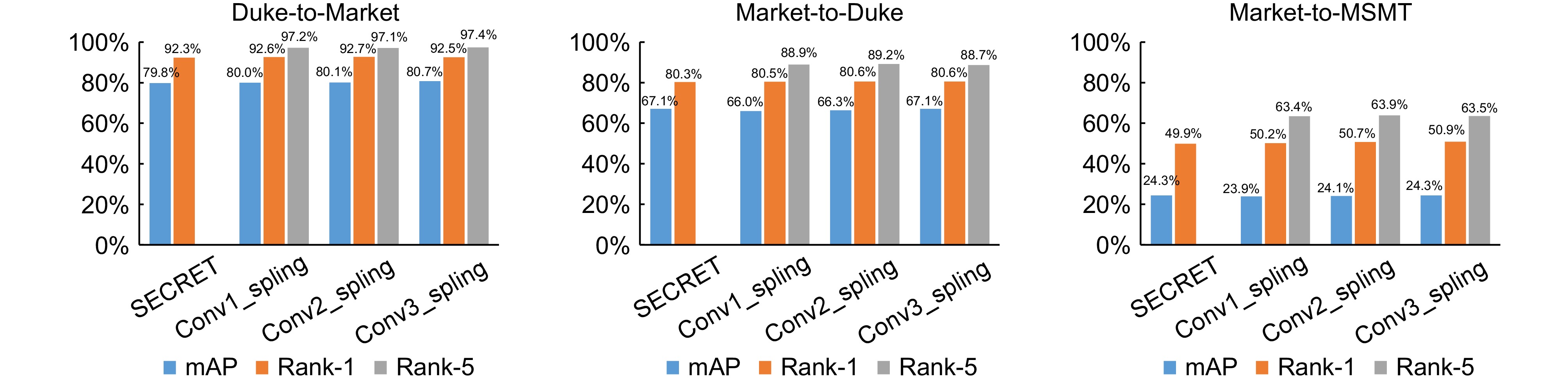
Figure 6.
Performance of different train epochs on mainstream datasets
-
Figure 7.
Ranking list of retrieval results with different models
- Figure .


