
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Jin Yao, Zhang Rui, Yin Dong. Object detection for small pixel in urban roads videos[J]. Opto-Electronic Engineering, 2019, 46(9): 190053. doi: 10.12086/oee.2019.190053

|
Object detection for small pixel in urban roads videos
-
Abstract
Small pixel targets in video images are difficult to detect. Aiming at the small pixel target in urban road video, this paper proposed a novel detection method named Road_Net based on the YOLOv3 convolutional neural network. Firstly, based on the improved YOLOv3, a new convolutional neural network Road_Net is designed. Secondly, for small pixel target detection depending on shallow level features, a detection method of 4 scales is adopted. Finally, combined with the improved M-Softer-NMS algorithm, it gets higher detection accuracy of the target in the image. In order to verify the effectiveness of the proposed algorithm, this paper collects and labels the data set named Road-garbage Dataset for small pixel target object detection on urban roads. The experimental results show that the algorithm can effectively detect objects such as paper scraps and stones, which are smaller pixel targets in the video relative to the road surface.-
Keywords:
- video image /
- smaller pixel object /
- convolutional neural network
-

-
References
[1] Lowe D G. Object recognition from local scale-invariant features[C]//The Proceedings of the 7th IEEE International Conference on Computer Vision, 1999, 2: 1150–1157. http://www.researchgate.net/publication/2373439_Object_Recognition_from_Local_Scale-Invariant_Features/ [2] Lowe D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91–110. doi: 10.1023/B:VISI.0000029664.99615.94 [3] Dalal N, Triggs B. Histograms of oriented gradients for human detection[C]//Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005, 1: 886–893. [4] Ojala T, Pietikainen M, Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971–987. doi: 10.1109/TPAMI.2002.1017623 [5] Cortes C, Vapnik V. Support-vector networks[J]. Machine Learning, 1995, 20(3): 273–297. [6] Ho T K. Random decision forests[C]//Proceedings of the 3rd International Conference on Document Analysis and Recognition, 1995, 1: 278–282. [7] 罗振杰, 曾国强.基于改进MTI算法的视频图像空间目标检测[J].光电工程, 2018, 45(8): 180048. doi: 10.12086/oee.2018.180048 Luo Z J, Zeng G Q. Space objects detection in video satellite images using improved MTI algorithm[J]. Opto-Electronic Engineering, 2018, 45(8): 180048. doi: 10.12086/oee.2018.180048 [8] 樊香所, 徐智勇, 张建林.改进粒子滤波的弱小目标跟踪[J].光电工程, 2018, 45(8): 170569. Fan X S, Xu Z Y, Zhang J L. Dim small target tracking based on improved particle filter[J]. Opto-Electronic Engineering, 2018, 45(8): 170569. [9] Schroff F, Kalenichenko D, Philbin J. FaceNet: a unified embedding for face recognition and clustering[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition, 2015: 815–823. [10] Wang X H, Gao L L, Wang P, et al. Two-stream 3-D convNet fusion for action recognition in videos with arbitrary size and length[J]. IEEE Transactions on Multimedia, 2018, 20(3): 634–644. doi: 10.1109/TMM.2017.2749159 [11] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580–587. http://www.researchgate.net/publication/258374356_Rich_feature_hierarchies_for_accurate_object_detection_and_semantic_segmentation/links/0301dd4e0cf23c5c592c85c9.pdf [12] Girshick R. Fast R-CNN[C]//Proceedings of 2015 IEEE International Conference on Computer Vision, 2015: 1440–1448. [13] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91–99. http://www.tandfonline.com/servlet/linkout?suffix=CIT0014&dbid=8&doi=10.1080%2F2150704X.2018.1475770&key=27295650 [14] Shrivastava A, Gupta A, Girshick R. Training region-based object detectors with online hard example mining[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 761–769. https://www.researchgate.net/publication/301876837_Training_Region-based_Object_Detectors_with_Online_Hard_Example_Mining [15] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779–788. [16] Uijlings J R R, Van De Sande K E A, Gevers T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154–171. doi: 10.1007/s11263-013-0620-5 [17] Zitnick C L, Dollár P. Edge boxes: locating object proposals from edges[C]//Proceedings of the 13th European Conference on Computer Vision, 2014: 391–405. [18] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 770–778. [19] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936–944. [20] 戴伟聪, 金龙旭, 李国宁, 等.遥感图像中飞机的改进YOLOv3实时检测算法[J].光电工程, 2018, 45(12): 180350. doi: 10.12086/oee.2018.180350 Dai W C, Jin L X, Li G N, et al. Real-time airplane detection algorithm in remote-sensing images based on improved YOLOv3[J]. Opto-Electronic Engineering, 2018, 45(12): 180350. doi: 10.12086/oee.2018.180350 [21] Bodla N, Singh B, Chellappa R, et al. Soft-NMS—improving object detection with one line of code[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 5562–5570. [22] He Y H, Zhang X Y, Savvides M, et al. Softer-NMS: rethinking bounding box regression for accurate object detection[J]. arXiv: 1809.08545v1[cs.CV], 2018. -
Overview

Overview: Small pixel target detection is a kind of difficult program. Existing object detection benchmarks and methods mainly focus on standard detection task. However, these ways cannot get good performance on low-pixel ratio object detection, which has a few pixel in high resolution images. And the early target detection frameworks such as R-CNN, YOLO series are not very good for small pixel target detection. In order to solve this problem, this paper proposes an improved YOLOv3 network and the algorithm using M-Softer-NMS to improve the detection ability of small targets. Firstly, Road_Net convolutional neural network is proposed. YOLOv3's Darknet53 network is too complicated and redundant. What's more, too many parameters will bring difficulty in training, increase the requirements on the dataset, and reduce the speed of detection, which will not achieve better real-time performance. Accuracy and real-time performance are challenging in small object detection on urban roads. Therefore, we proposed a convolutional neural network Road_Net with relatively low computational complexity as a feature extraction network. Secondly, a detection method of 4 scales is used to more fully use shallow level features. In view of the fact that the targets in this context are mostly small pixel targets, the original three scale detections are extended to four scale detections, and the larger feature maps are assigned to the smaller pixel targets with more accurate anchor frames. Finally, M-Softer-NMS algorithm is used to further improve the detection accuracy of the target in the image. Softer-NMS is further improved after Soft-NMS. A new loss function (KL Loss) for bounding box regression is proposed to learn the bounding box transformation and positional reliability at the same time. Combined with the characteristics of small pixel targets in this paper, the M-softer-NMS algorithm for this paper is proposed based on softer-NMS. In order to verify the effectiveness of the algorithm, we collected and labeled the data set named Road-garbage Dataset for the detection of small pixel target objects on the road. The Dataset is based on several main roads in a certain city and selects 1200 different main roads in different regions. The experimental results show that the accuracy, recall rate and AP can reach 95.29%, 91.12% and 82.41% respectively, while real-time detection is 57.9 f/s. In the next work, we will continue to improve the network and optimize the algorithm for higher accuracy and lower time cost, and continue to capture and use our more realistic scene images to expand our dataset for better application.
-
Access History


Export File
Citation
Jin Yao, Zhang Rui, Yin Dong. Object detection for small pixel in urban roads videos[J]. Opto-Electronic Engineering, 2019, 46(9): 190053. doi: 10.12086/oee.2019.190053
Format
Content
 DownLoad:
DownLoad:


-
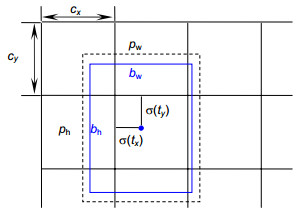
Figure 1.
Predicting target box position
-
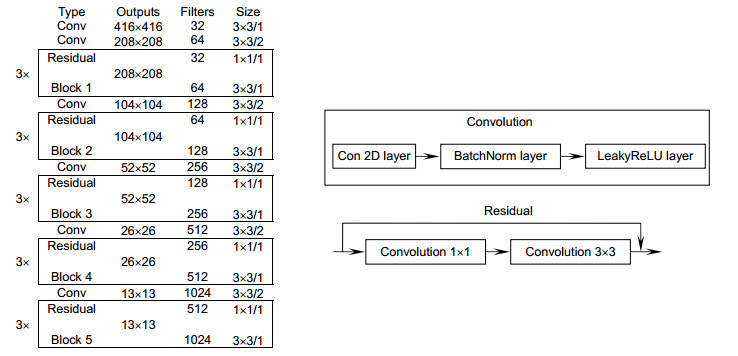
Figure 2.
Road_Net network architecture diagram
-
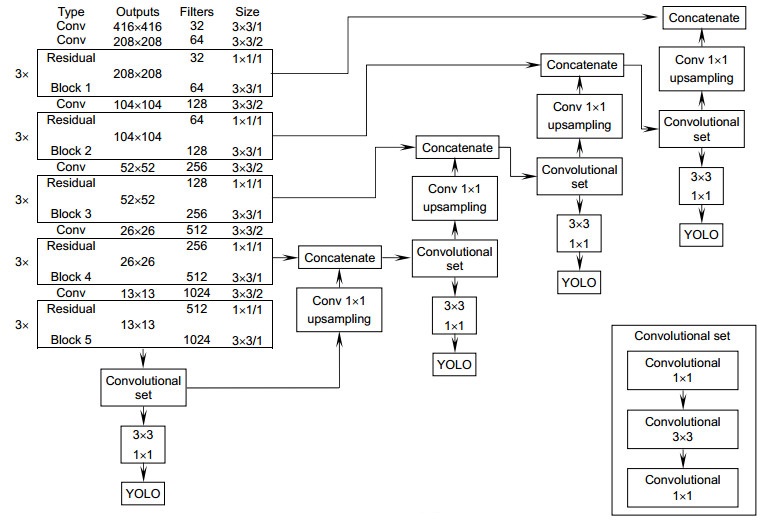
Figure 3.
Multi-scale detection
-
Figure 4.
Testing images and detection results
-
Figure 5.
Examples for anomaly detection


