
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |

|
Video object segmentation algorithm based on adaptive template updating and multi-feature fusion
-
Abstract
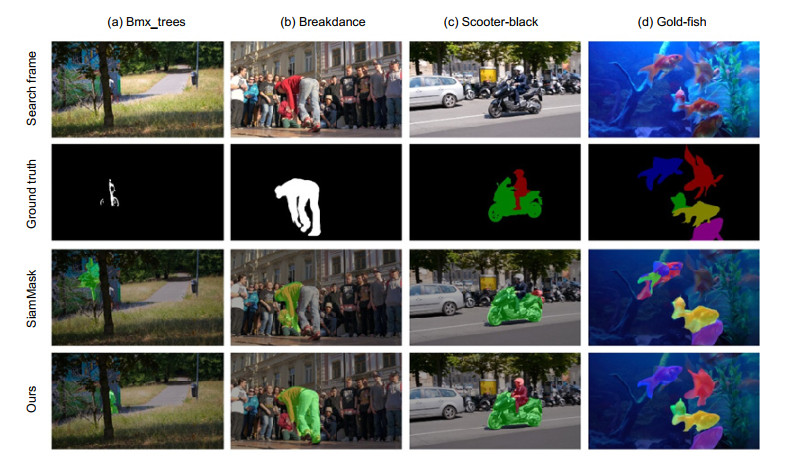
In order to solve the problem that SiamMask cannot adapt to the change of target appearance and the lack of use of feature information leads to rough mask generation, this paper proposes a video object segmentation algorithm based on the adaptive template update and the multi-feature fusion. First of all, the algorithm adaptively updates the template using the segmentation results of each frame; secondly, the hybrid pooling module is used to enhance the features extracted in the fourth stage of the backbone network, and the enhanced features are fused with the rough mask; finally, the feature fusion module is used to refine the rough mask stage by stage, which can effectively combine the spliced features. Experimental results show that, compared with SiamMask, the performance of the proposed algorithm is significantly improved. On the DAVIS2016 data-set, the region similarity and contour similarity of this algorithm are 0.727 and 0.696, respectively, which is 1.0% and 1.8% higher than that of the benchmark algorithm, and the speed reaches 40.2 f/s. On the DAVIS2017 data-set, the region similarity and contour similarity of this algorithm are 0.567 and 0.615, respectively, which is 2.4% and 3.0% higher than that of the benchmark algorithm, and the speed reaches 42.6 f/s.-
Keywords:
- video object segmentation /
- template update /
- feature fusion /
- mask thinning
-

-
References
[1] Miao J X, Wei Y C, Yang Y. Memory aggregation networks for efficient interactive video object segmentation[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 10366-10375. [2] Lu X K, Wang W G, Shen J B, et al. Learning video object segmentation from unlabeled videos[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 8957-8967. [3] Caelles S, Maninis K K, Pont-Tuset J, et al. One-shot video object segmentation[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 5320-5329. [4] Perazzi F, Khoreva A, Benenson R, et al. Learning video object segmentation from static images[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 3491-3500. [5] Voigtlaender P, Leibe B. Online adaptation of convolutional neural networks for video object segmentation[Z]. arXiv: 1706.09364, 2017. [6] Luiten J, Voigtlaender P, Leibe B. PReMVOS: proposal-generation, refinement and merging for video object segmentation[C]//Proceedings of the 14th Asian Conference on Computer Vision, 2018: 565-580. [7] Li X X, Loy C C. Video object segmentation with joint re-identification and attention-aware mask propagation[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 93-110. [8] Cheng J C, Tsai Y H, Hung W C, et al. Fast and accurate online video object segmentation via tracking parts[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7415-7424. [9] Chen Y H, Pont-Tuset J, Montes A, et al. Blazingly fast video object segmentation with pixel-wise metric learning[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 1189-1198. [10] Hu Y T, Huang J B, Schwing A G. VideoMatch: matching based video object segmentation[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 56-73. [11] Voigtlaender P, Chai Y N, Schroff F, et al. FEELVOS: fast end-to-end embedding learning for video object segmentation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 9473-9482. [12] Johnander J, Danelljan M, Brissman E, et al. A generative appearance model for end-to-end video object segmentation[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 8945-8954. [13] Yang L J, Wang Y R, Xiong X H, et al. Efficient video object segmentation via network modulation[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 6499-6507. [14] Oh S W, Lee J Y, Sunkavalli K, et al. Fast video object segmentation by reference-guided mask propagation[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 7376-7385. [15] Oh S W, Lee J Y, Xu N, et al. Video object segmentation using space-time memory networks[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 9225-9234. [16] Wang Q, Zhang L, Bertinetto L, et al. Fast online object tracking and segmentation: a unifying approach[C]//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019: 1328-1338. [17] Li B, Yan J J, Wu W, et al. High performance visual tracking with Siamese region proposal network[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 8971-8980. [18] Perazzi F, Pont-Tuset J, McWilliams B, et al. A benchmark dataset and evaluation methodology for video object segmentation[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 724-732. [19] Pont-Tuset J, Perazzi F, Caelles S, et al. The 2017 DAVIS challenge on video object segmentation[Z]. arXiv: 1704.00675, 2018. [20] Zhang L C, Gonzalez-Garcia A, Van De Weijer J, et al. Learning the model update for Siamese trackers[C]//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision, 2019: 4009-4018. [21] Zhao H S, Shi J P, Qi X J, et al. Pyramid scene parsing network[C]//Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 6230-6239. [22] Hou Q B, Zhang L, Cheng M M, et al. Strip pooling: rethinking spatial pooling for scene parsing[C]//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 4002-4011. [23] Yu C Q, Wang J B, Peng C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation[C]//Proceedings of the 15th European Conference on Computer Vision, 2018: 334-349. [24] Jampani V, Gadde R, Gehler P V. Video propagation networks[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 3154-3164. [25] Märki N, Perazzi F, Wang O, et al. Bilateral space video segmentation[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 743-751. [26] Yoon J S, Rameau F, Kim J, et al. Pixel-level matching for video object segmentation using convolutional neural networks[C]//Proceedings of 2017 IEEE International Conference on Computer Vision, 2017: 2186-2195. [27] Chen X, Yan B, Zhu J W, et al. Transformer tracking[Z]. arXiv: 2103.15436, 2021. -
Overview

Overview: In recent years, video object segmentation (VOS) has been widely used in video surveillance, autopilot, intelligent robot, and other fields, and it has attracted more and more researchers' attention. According to the degree of human participation, video object segmentation can be divided into interactive video object segmentation, unsupervised video object segmentation, and semi-supervised video object segmentation. Semi-supervised VOS is the most concerned task in the field of video object segmentation, and it is also the research direction of this paper. Semi-supervised VOS gives the real mask of the target in the first frame of the video, and its purpose is to segment the target mask automatically in the remaining frames. However, in the whole video sequence, the target to be segmented may experience great appearance changes, occlusion, and fast movement, so it is a very challenging task to segment the target robust in the video sequence.
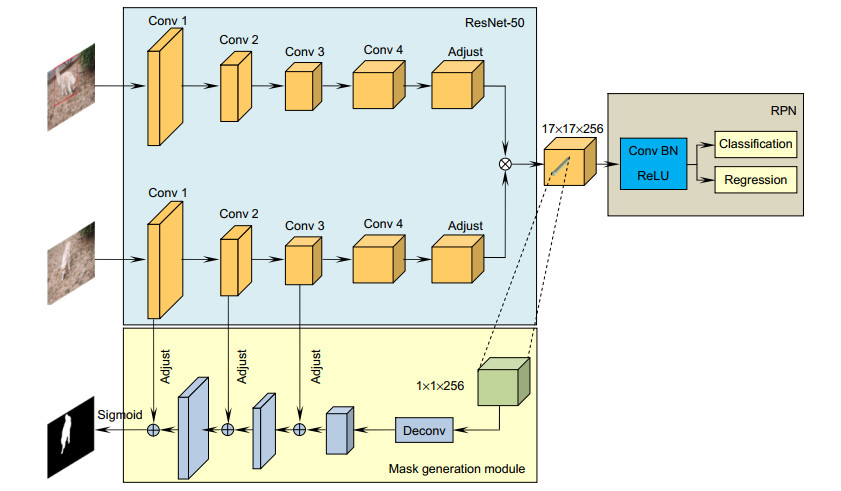
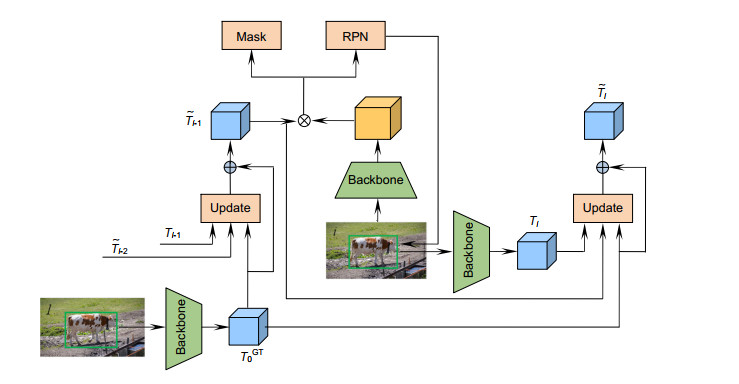
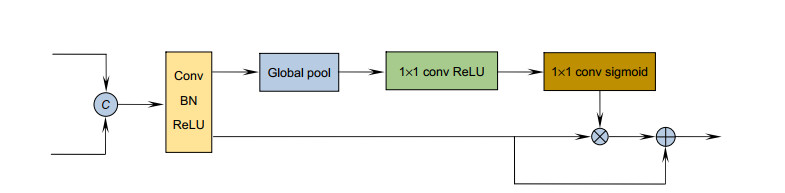
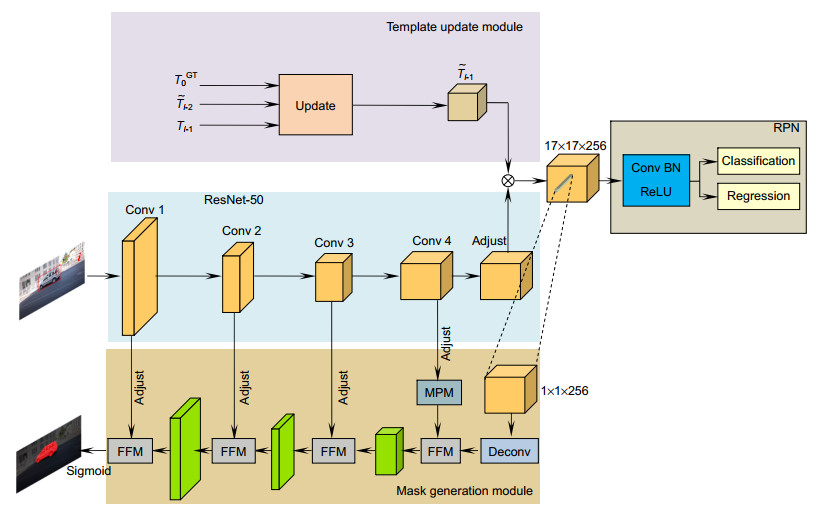
SiamMask forms is a multi-branch twin network framework by adding Mask branches to SiamRPN. In the field of video object segmentation, SiamMask achieves competitive segmentation accuracy on DAVIS2016 and DAVIS2017 data-sets. At the same time, the speed is nearly an order of magnitude faster than the method in the same period. Compared with the classical OSVOS, SiamMask is two orders of magnitude faster, so the video object segmentation can be applied in practice. However, due to the lack of template update, SiamMask is prone to tracking drift in complex videos. In addition, in the process of mask generation, SiamMask uses a lot of feature information loss, the fusion process is relatively rough, and does not use the feature map of the whole stage of the backbone network to refine the mask. In order to solve the above problems, this paper proposes a video object segmentation algorithm based on the adaptive template update and the multi-feature fusion. First of all, the proposed algorithm uses an adaptive update strategy to process the template, which can update the template using the segmentation results of each frame. Secondly, in order to use more feature information to refine the mask, this algorithm uses the hybrid pooling module to enhance the features extracted in the fourth stage of the backbone network, and fuses the enhanced features with the rough mask. Finally, in order to generate a more fine mask, this algorithm uses the feature fusion module to participate in the mask thinning process of intermediate features with richer spatial information in each stage of the backbone network. The experimental results show that the proposed algorithm significantly improves the tracking drift caused by occlusion and similar background interference, the performances on DAVIS2016 and DAVIS2017 data-sets are significantly improved, and the running speed meets the real-time requirements.
-
Access History
Figures(6)
Tables(3)
Article Metrics


Export File
Citation
Format
Content
 DownLoad:
DownLoad:

-
Figure 1.
Overall framework of siamMask algorithm
-
Figure 2.
Template update module and template update process
-
Figure 3.
Mixed pooling module (MPM)
-
Figure 4.
Feature fusion module (FFM)
-
Figure 5.
The overall framework of the algorithm in this paper
-
Figure 6.
Qualitative experimental results


