
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Zhang J, Lv M H, Feng Y A, et al. A road extraction algorithm that fuses element multiplication and detail optimization[J]. Opto-Electron Eng, 2024, 51(12): 240210. doi: 10.12086/oee.2024.240210

|
A road extraction algorithm that fuses element multiplication and detail optimization
-
Abstract
To address the existing challenges of discontinuity in road region extraction and difficulty in extracting roads of different sizes, especially the misclassification of narrow roads, a novel road extraction algorithm combining element-wise multiplication and detail optimization was proposed. Firstly, an element-wise multiplication module (IEM module) was introduced in the encoder part to perform feature extraction, preserving and extracting multi-scale and multi-level road features. A Conv3×3 with a stride of 2 was used for twofold downsampling, reducing information loss during the extraction process of remote sensing images. The encoder-decoder was structured with five layers and utilized skip connections to maintain multi-scale extraction capabilities while improving road continuity. Secondly, PFAAM was employed to enhance the network's focus on road features. Finally, a fine residual network (RRN) was utilized to enhance the network's ability to extract boundary details, refining the boundary information. Experiments were conducted on the public road dataset of Massachusetts (CHN6-CUG) to test the network model, achieving evaluation metrics of OA (accuracy), IoU (intersection over union), mIoU (mean IoU), F1-score of 98.06% (97.19%)、64.52% (60.24%)、81.25% (78.66%), and 88.70% (86.85%). The experimental results demonstrated that the proposed method outperformed all the compared methods, effectively improving the accuracy of road segmentation.-
Keywords:
- deep learning /
- road extraction /
- image segmentation /
- multi-scale information /
- boundary extraction
-

-
References
[1] 杭昊, 黄影平, 张栩瑞, 等. 面向道路场景语义分割的移动窗口变换神经网络设计[J]. 光电工程, 2024, 51 (1): 230304. doi: 10.12086/oee.2024.230304 Hang H, Huang Y P, Zhang X R, et al. Design of Swin transformer for semantic segmentation of road scenes[J]. Opto-Electron Eng, 2024, 51 (1): 230304. doi: 10.12086/oee.2024.230304 [2] 吴马靖, 张永爱, 林珊玲, 等. 基于BiLevelNet的实时语义分割算法[J]. 光电工程, 2024, 51 (5): 240030. doi: 10.12086/oee.2024.240030 Wu M J, Zhang Y A, Lin S L, et al. Real-time semantic segmentation algorithm based on BiLevelNet[J]. Opto-Electron Eng, 2024, 51 (5): 240030. doi: 10.12086/oee.2024.240030 [3] Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, 2015: 234–241. https://doi.org/10.1007/978-3-319-24574-4_28. [4] Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39 (12): 2481−2495. doi: 10.1109/TPAMI.2016.2644615 [5] Hou Y W, Liu Z Y, Zhang T, et al. C-UNet: complement UNet for remote sensing road extraction[J]. Sensors, 2021, 21 (6): 2153. doi: 10.3390/s21062153 [6] 肖振久, 郝明, 曲海成, 等. 融合注意力和扩张卷积的遥感影像道路信息提取方法[J]. 遥感信息, 2024, 39 (1): 18−25. doi: 10.20091/j.cnki.1000-3177.2024.01.003 Xiao Z J, Hao M, Qu H C, et al. Road information extraction method of remote sensing image by combining attention and extended convolution[J]. Remote Sens Inf, 2024, 39 (1): 18−25. doi: 10.20091/j.cnki.1000-3177.2024.01.003 [7] 何哲, 陶于祥, 罗小波, 等. 基于改进U-Net的遥感图像道路提取[J]. 激光与光电子学进展, 2023, 60 (16): 1628004. doi: 10.3788/LOP222634 He Z, Tao Y X, Luo X B, et al. Road extraction from remote sensing image based on an improved U-Net[J]. Laser Optoelectron Prog, 2023, 60 (16): 1628004. doi: 10.3788/LOP222634 [8] Wang F, Jiang M Q, Qian C, et al. Residual attention network for image classification[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, 2017: 6450–6458. https://doi.org/10.1109/CVPR.2017.683. [9] Li P K, Zhang Y, Wang C, et al. Road network extraction via deep learning and line integral convolution[C]//2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, 2016: 1599–1602. https://doi.org/10.1109/IGARSS.2016.7729408. [10] Zhang X K, Ma X Z, Yang Z G, et al. A context-aware road extraction method for remote sensing imagery based on transformer network[J]. IEEE Geosci Remote Sens Lett, 2023, 20: 5511205. doi: 10.1109/LGRS.2023.3324644 [11] Ma X Z, Zhang X K, Zhou D X, et al. StripUnet: a method for dense road extraction from remote sensing images[J]. IEEE Trans Intell Veh, 2024. doi: 10.1109/TIV.2024.3393508 [12] Ma X, Dai X Y, Bai Y, et al. Rewrite the stars[C]//Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2024: 5694–5703. https://doi.org/10.1109/CVPR52733.2024.00544. [13] Körber N. Parameter-free average attention improves convolutional neural network performance (almost) free of charge[Z]. arXiv: 2210.07828, 2022. https://arxiv.org/abs/2210.07828. [14] Qin X B, Zhang Z C, Huang C Y, et al. BASNet: boundary-aware salient object detection[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 2019: 7471–7481. https://doi.org/10.1109/CVPR.2019.00766. [15] Hu M, Li Y L, Fang L, et al. A2-FPN: attention aggregation based feature pyramid network for instance segmentation[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, 2021: 15338–15347. https://doi.org/10.1109/CVPR46437.2021.01509. [16] Liu Y L, Chen H, Shen C H, et al. ABCNet: real-time scene text spotting with adaptive Bezier-curve network[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 2020: 9806–9815. https://doi.org/10.1109/CVPR42600.2020.00983. [17] Fan T L, Wang G L, Li Y, et al. MA-Net: a multi-scale attention network for liver and tumor segmentation[J]. IEEE Access, 2020, 8: 179656−179665. doi: 10.1109/ACCESS.2020.3025372 [18] Zhou L C, Zhang C, Wu M. D-LinkNet: LinkNet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, 2018: 192–1924. https://doi.org/10.1109/CVPRW.2018.00034. [19] Qi Y L, He Y T, Qi X M, et al. Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation[C]//Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision, Paris, 2023: 6047–6056. https://doi.org/10.1109/ICCV51070.2023.00558. [20] Huang Z L, Wang X G, Wei Y C, et al. CCNet: criss-cross attention for semantic segmentation[J]. IEEE Trans Pattern Anal Mach Intell, 2023, 45 (6): 6896−6908. doi: 10.1109/TPAMI.2020.3007032 -
Overview
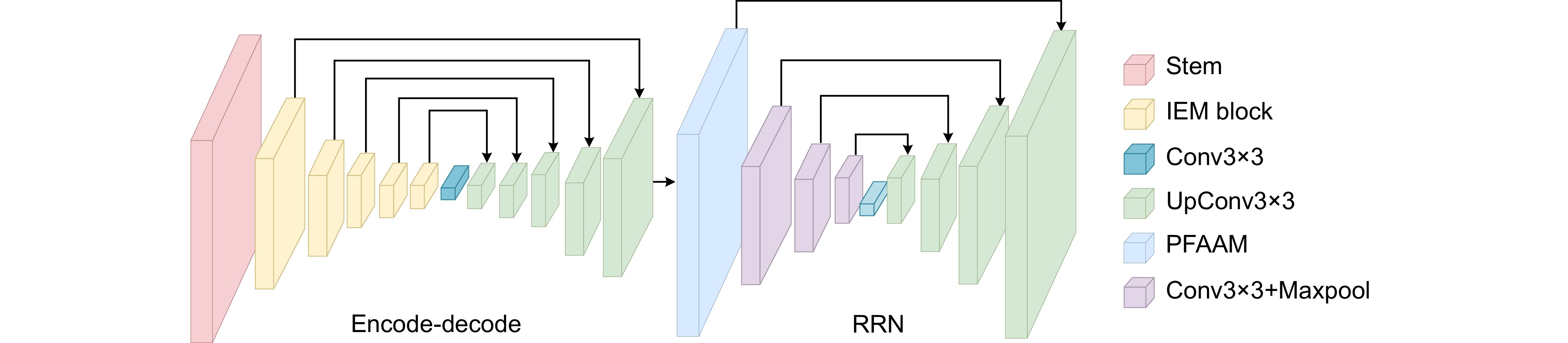
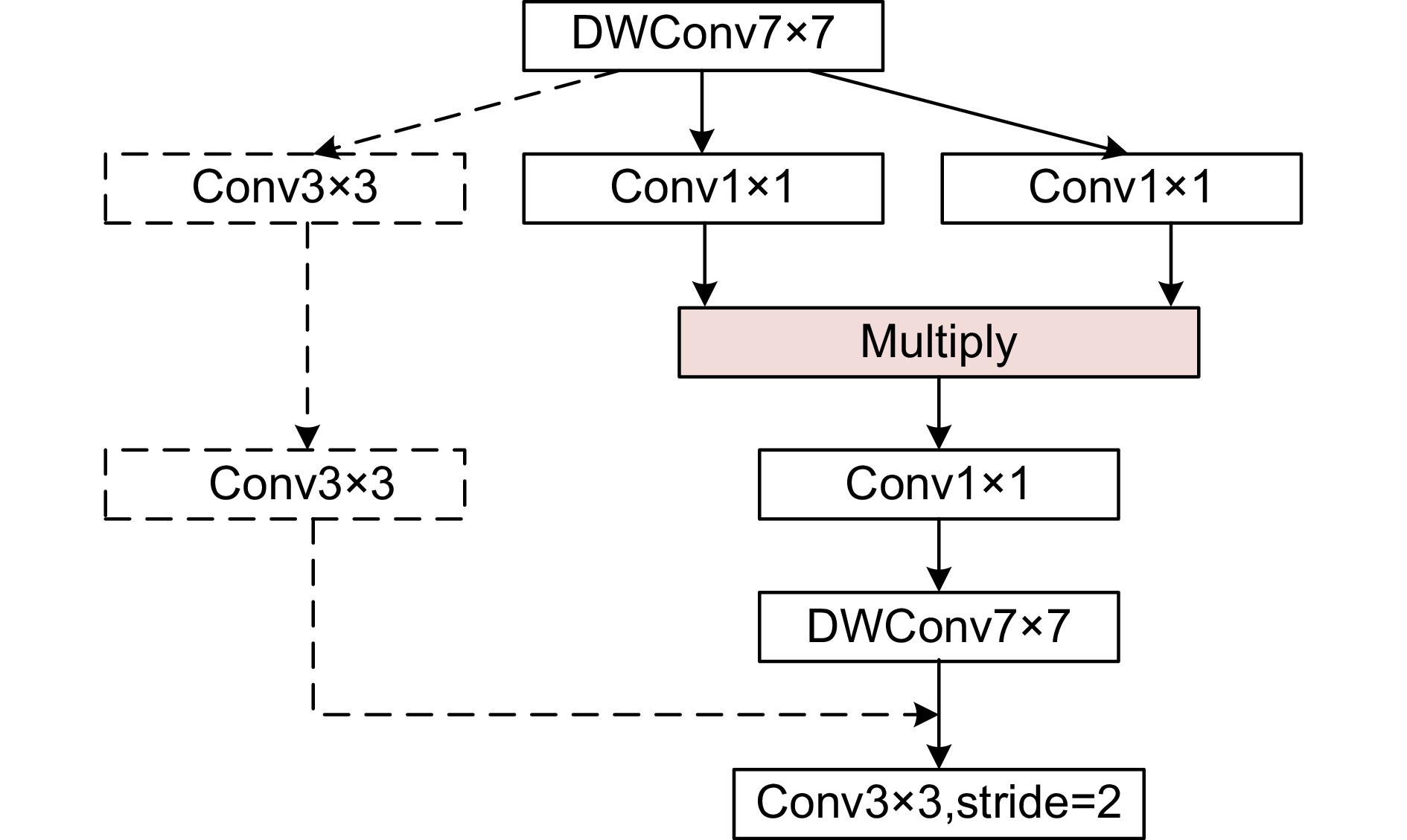
To address the issues of discontinuity in road region extraction, difficulties in extracting roads of varying sizes, and misclassification of narrow roads, this paper proposes a road extraction algorithm that integrates element-wise multiplication with detail optimization. This algorithm is designed with a focus on multi-scale feature extraction and fine-grained boundary processing to enhance the continuity and accuracy of road region extraction. Firstly, the algorithm introduces an element-wise multiplication module (IEM) in the encoder. This module utilizes element-wise multiplication to map dimensional space features to a higher dimensional space, facilitating more effective feature extraction while preserving multi-scale and multi-level features, and thus minimizing information loss. Specifically, after extracting features using depthwise separable convolution, the features undergo two passes of Conv1×1 and are then mapped to higher dimensions through element-wise multiplication, replacing traditional additive methods. This approach better captures multi-scale information, and each layer of the encoder uses a stride-2 Conv3×3 for downsampling, reducing information loss during the extraction process of remote sensing images while maintaining high efficiency in feature extraction. This enables the network to better capture road features at different scales, particularly in narrow roads and complex terrain. Secondly, to enhance the network's focus on road regions, a partial attention fusion module (PFAAM) is proposed. By introducing an attention mechanism during the decoding process, PFAAM increases the network's focus on road regions, especially in areas where boundaries are blurred or noise is prevalent. PFAAM dynamically adjusts the network’s weight distribution across different feature layers, ensuring effective road feature recognition at various scales. Finally, the algorithm incorporates a refined residual network (RRN) to enhance the extraction of boundary details. RRN further refines boundary information within the decoder, allowing the network to more accurately segment road edges and avoiding common issues, such as edge blurring and misclassification seen in traditional methods. This refinement enables the algorithm to produce smoother and more continuous road boundaries, thus improving overall segmentation accuracy. Experimental results on the public road dataset of Massachusetts and CHN6-CUG demonstrate that the proposed network achieves outstanding performance with overall accuracy (OA) of 98.06% and 97.19%, intersection over union (IoU) of 64.52% and 60.24%, mean IoU (mIoU) of 81.25% and 78.66%, and F1 score of 88.70% and 86.85%. The visualization results also indicate superior performance in multi-scale road and detail extraction. These improvements highlight the significant advantages of the proposed road extraction algorithm, integrating element-wise multiplication and detail optimization, in terms of multi-scale road segmentation accuracy and detail processing.
-
Access History
Figures(14)
Tables(4)
Article Metrics


Export File
Citation
Zhang J, Lv M H, Feng Y A, et al. A road extraction algorithm that fuses element multiplication and detail optimization[J]. Opto-Electron Eng, 2024, 51(12): 240210. doi: 10.12086/oee.2024.240210
Format
Content
 DownLoad:
DownLoad:






-
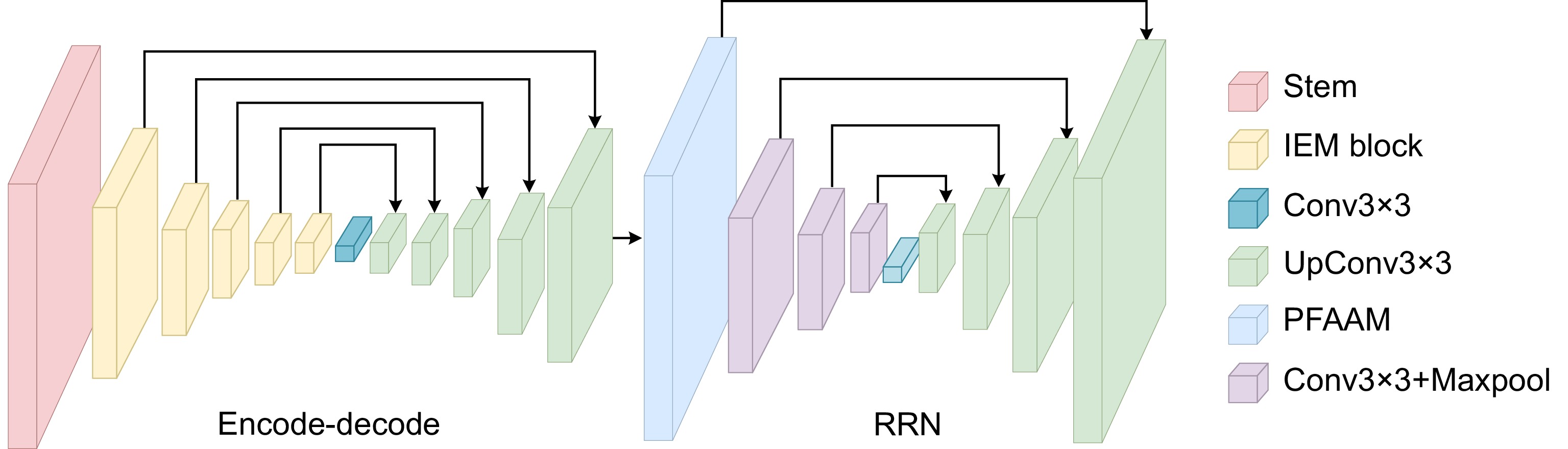
Figure 1.
Road extraction algorithm incorporating elemental multiplication and detail optimisation
-
Figure 2.
IEM block
-
Figure 3.
Comparison of receptive fields in different models. (a) IEM block sensory field; (b) IEM block without two Conv3×3 branches
-
Figure 4.
Depthwise convolution
-
Figure 5.
Pointwise convolution
-
Figure 6.
Classification of 2D planes
-
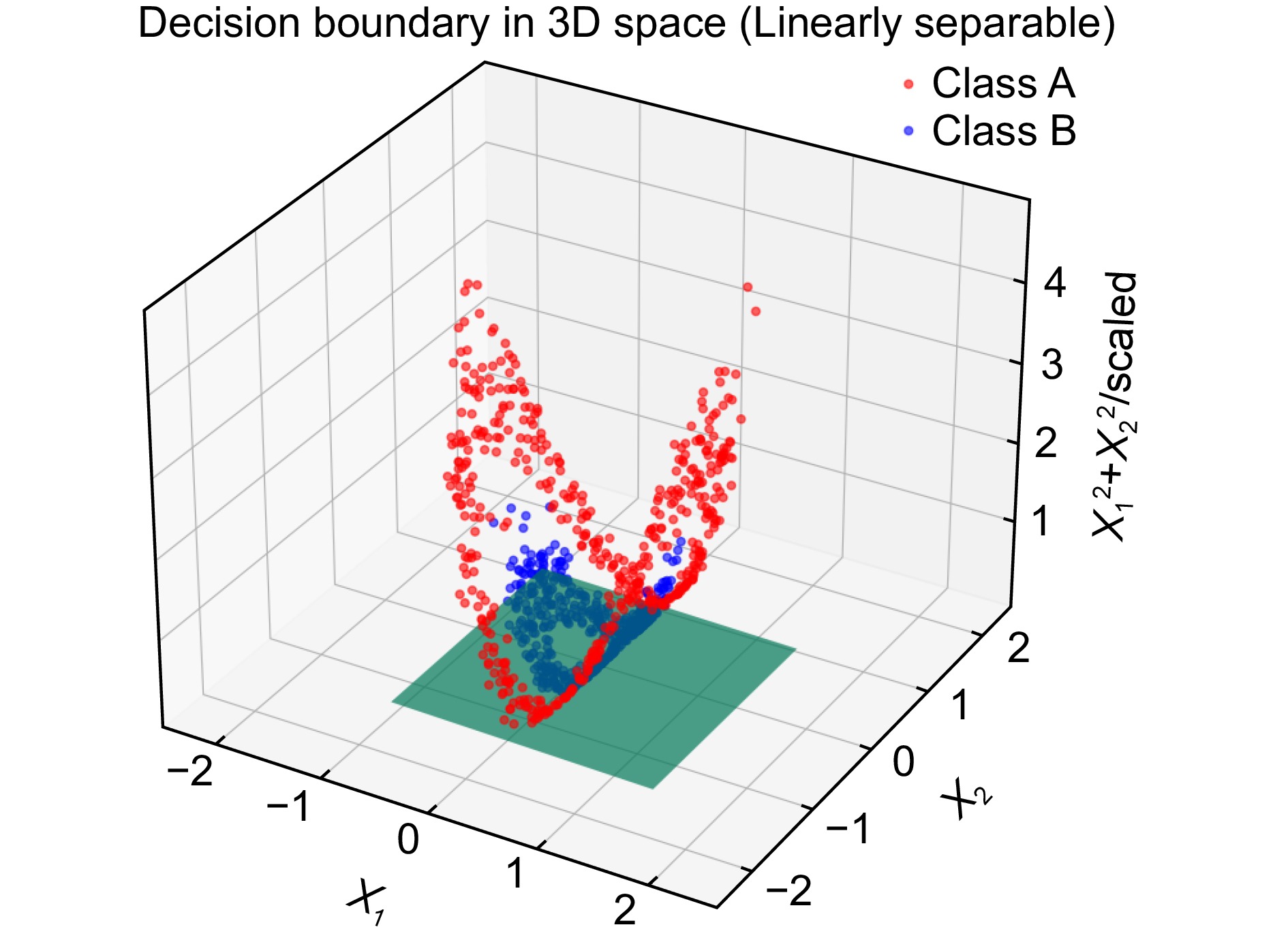
Figure 7.
Three-dimensional plane classification
-
Figure 8.
Comparison of heat maps. (a) Image; (b) Conv3×3; (c) Original IEM; (d) IEM
-
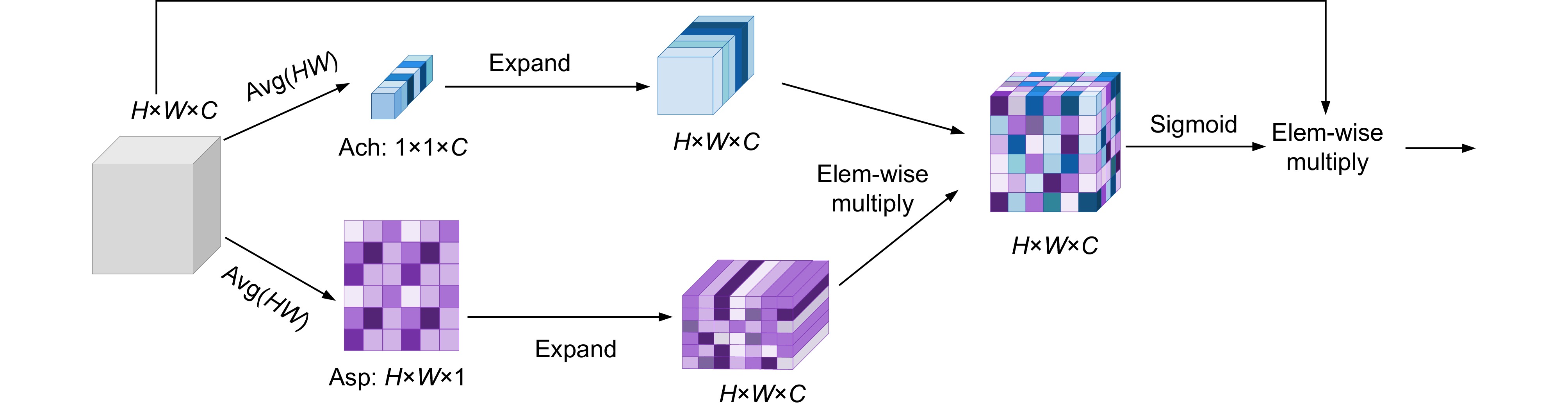
Figure 9.
Parameter-free attention mechanism of PFAAM
-
Figure 10.
Comparison of heat maps. (a) Image; (b) Direct output; (c) Output + RRN
-
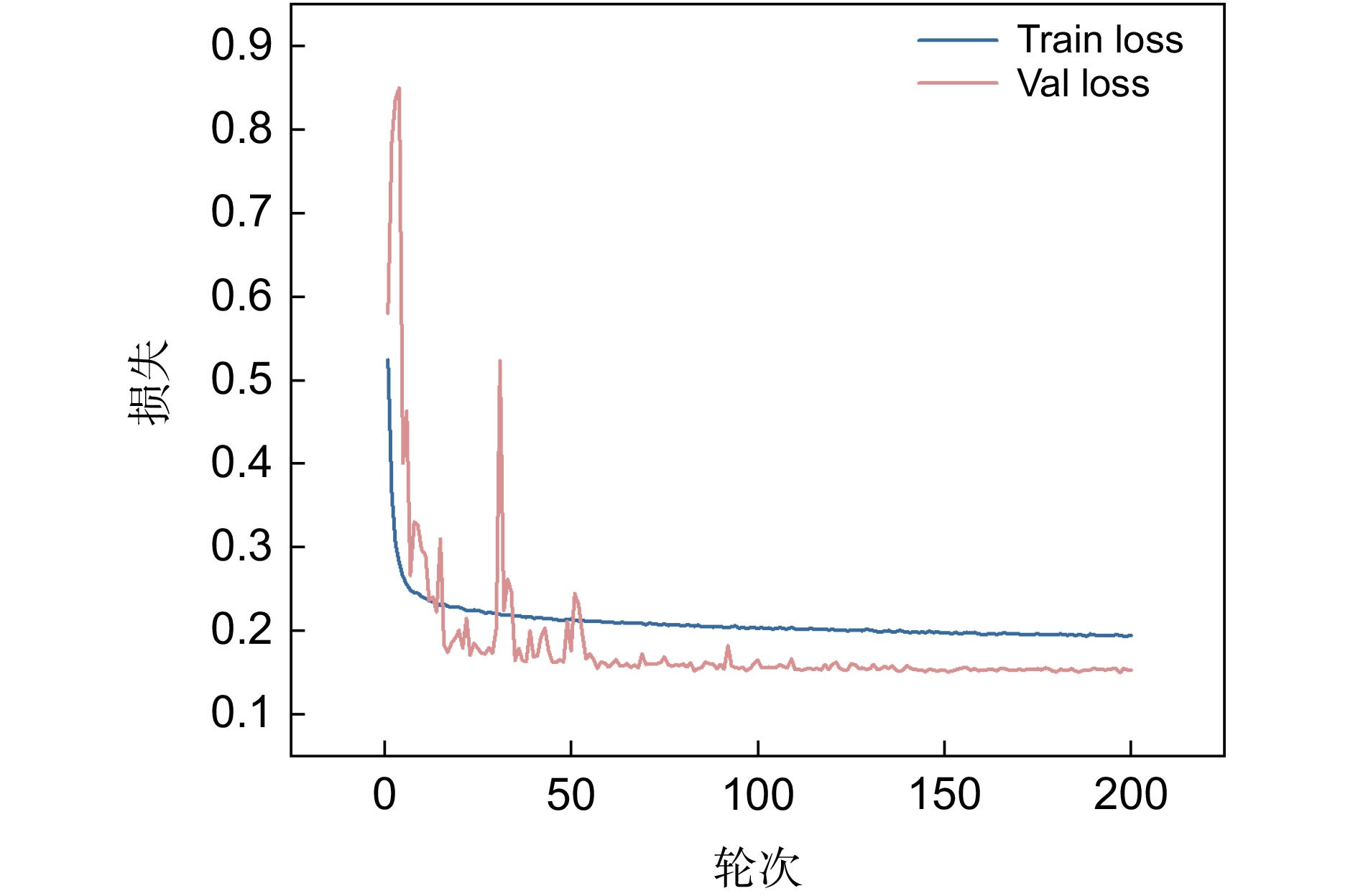
Figure 11.
Output loss function value conversion curves
-
Figure 12.
Comparison of visualization results extracted by various methods
-
Figure 13.
Comparison of visualization results extracted by various methods
- Figure .


