
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Xiao Z J, Tian H, Zhang J H, et al. Fusion of dynamic features enhances remote sensing building segmentation[J]. Opto-Electron Eng, 2025, 52(3): 240231. doi: 10.12086/oee.2025.240231

|
Fusion of dynamic features enhances remote sensing building segmentation
-
Abstract
Aiming at the poor segmentation effect caused by the large scale difference of objects, uneven spatial distribution of samples, fuzzy boundary of objects and large span of scene area, this paper proposes a high-precision remote sensing building segmentation algorithm enhanced by integrating dynamic features. Firstly, the New_GhostNetV2 network is constructed, and the adaptive context-aware convolution is used to improve the algorithm's ability to capture the features of the sample space. Secondly, multi-level information enhancement modules are designed using ghost convolution combined with skip connections and feature branching strategies to enhance the feature integration. Then CGA (cascaded group attention) is introduced to enhance the adaptability of the model to diverse ground object forms through the calculation of independent attention within the group. Finally, the feature fusion module is constructed by the dynamic depth feature enhancer to further enhance the ability of model capture. The experimental results on the WHU data set show that the improved algorithm is 8.57% higher than the baseline model F1-Score and 12.48% higher than mIoU. Compared with other mainstream semantic segmentation models, the improved DeepLabv3+ has better segmentation accuracy. -

-
References
[1] 徐胜军, 荆扬, 李海涛, 等. 渐进式多粒度ResNet车型识别网络[J]. 光电工程, 2023, 50(7): 230052. doi: 10.12086/oee.2023.230052 Xu S J, Jing Y, Li H T, et al. Progressive multi-granularity ResNet vehicle recognition network[J]. Opto-Electron Eng, 2023, 50(7): 230052. doi: 10.12086/oee.2023.230052 [2] 潘李琳, 邵剑飞. 融合图注意力的多分辨率点云补全[J]. 激光技术, 2023, 47(5): 700−707. doi: 10.7510/jgjs.issn.1001-3806.2023.05.019 Pan L L, Shao J F. Multi-resolution point cloud completion fusing graph attention[J]. Laser Technol, 2023, 47(5): 700−707. doi: 10.7510/jgjs.issn.1001-3806.2023.05.019 [3] 王璨, 武新慧, 张燕青, 等. 基于双注意力语义分割网络的田间苗期玉米识别与分割[J]. 农业工程学报, 2021, 37(9): 211−221. doi: 10.11975/j.issn.1002-6819.2021.09.024 Wang C, Wu X H, Zhang Y Q, et al. Recognition and segmentation of maize seedlings in field based on dual attention semantic segmentation network[J]. Trans Chin Soc Agric Eng, 2021, 37(9): 211−221. doi: 10.11975/j.issn.1002-6819.2021.09.024 [4] 傅启凡, 路茗, 张质懿, 等. 基于语义分割的水位监测方法研究[J]. 激光与光电子学进展, 2022, 59(4): 0410004. doi: 10.3788/LOP202259.0410004 Fu Q F, Lu M, Zhang Z Y, et al. Water level monitoring method based on semantic segmentation[J]. Laser Optoelectron Prog, 2022, 59(4): 0410004. doi: 10.3788/LOP202259.0410004 [5] 孟俊熙, 张莉, 曹洋, 等. 基于Deeplab v3+的图像语义分割算法优化研究[J]. 激光与光电子学进展, 2022, 59(16): 1610009. doi: 10.3788/LOP202259.1610009 Meng J X, Zhang L, Cao Y, et al. Optimization of image semantic segmentation algorithms based on Deeplab v3+[J]. Laser Optoelectron Prog, 2022, 59(16): 1610009. doi: 10.3788/LOP202259.1610009 [6] Pan S, Li J W, Jiang J W. A street view semantic segmentation algorithm based on DeeplabV3+ architecture[J]. Proc SPIE, 2023, 12717: 127172D. doi: 10.1117/12.2684626 [7] Harkat H, Nascimento J M P, Bernardino A, et al. Assessing the impact of the loss function and encoder architecture for fire aerial images segmentation using deeplabv3+[J]. Remote Sens, 2022, 14(9): 2023. doi: 10.3390/rs14092023 [8] Das S, Fime A A, Siddique N, et al. Estimation of road boundary for intelligent vehicles based on DeepLabV3+ architecture[J]. IEEE Access, 2021, 9: 121060−121075. doi: 10.1109/ACCESS.2021.3107353 [9] Su Y A, Lin Y, Fang X B, et al. Improved DeepLabV3+ network segmentation method for urban road scenes[C]//2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), 2022: 1274–1280. https://doi.org/10.1109/ITAIC54216.2022.9836922. [10] Guo L L, Zhou J Z. A lightweight network for semantic segmentation of road images based on improved DeepLabv3+[C]//2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), 2022: 832–837. https://doi.org/10.1109/PRAI55851.2022.9904092. [11] Li Z Y, Wang R, Zhang W, et al. Multiscale features supported DeepLabV3+ optimization scheme for accurate water semantic segmentation[J]. IEEE Access, 2019, 7: 155787−155804. doi: 10.1109/ACCESS.2019.2949635 [12] 刘尚旺, 崔智勇, 李道义. 基于Unet网络多任务学习的遥感图像建筑地物语义分割[J]. 国土资源遥感, 2020, 32(4): 74−83. doi: 10.6046/gtzyyg.2020.04.11 Liu S W, Cui Z Y, Li D Y. Multi-task learning for building object semantic segmentation of remote sensing image based on Unet network[J]. Remote Sens Land Resour, 2020, 32(4): 74−83. doi: 10.6046/gtzyyg.2020.04.11 [13] Wang J, Zhang X L, Yan T H, et al. DPNet: dual-pyramid semantic segmentation network based on improved deeplabv3 plus[J]. Electronics, 2023, 12(14): 3161. doi: 10.3390/electronics12143161 [14] Kwak J, Sung Y. DeepLabV3-refiner-based semantic segmentation model for dense 3D point clouds[J]. Remote Sens, 2021, 13(8): 1565. doi: 10.3390/rs13081565 [15] Dong W K, Gong S C. Hazy images segmentation method based on improved DeeplabV3[J]. Acad J Comput Inf Sci, 2023, 6(5): 21−29. doi: 10.25236/AJCIS.2023.060504 [16] Basir S, Aziz N A A, Abiddin N Z. Semantic segmentation of paddy parcels using deep neural networks based on DeepLabV3[C]//Proceedings of the 10th International Conference on Geographical Information Systems Theory, Applications and Management, 2024, 1 : 173–180. https://doi.org/10.5220/0012698200003696. [17] Nie Z, Xu J C, Zhang S C. Analysis on DeepLabV3+ performance for automatic steel defects detection[Z]. arXiv: 2004.04822, 2020. https://doi.org/10.48550/arXiv.2004.04822. [18] Cabrera I, Zhou Y X, Ngo E, et al. Image segmentation using transfer learning with DeepLabv3 to facilitate photogrammetric limb scanning[Z]. https://doi.org/10.36227/techrxiv.19742488.v1. [19] Ikedo R, Hotta K. Feature sharing cooperative network for semantic segmentation[C]//Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, 2021, 5 : 577–584. https://doi.org/10.5220/0010312505770584. [20] Quan B, Liu B Y, Fu D C, et al. Improved Deeplabv3 for better road segmentation in remote sensing images[C]//2021 International Conference on Computer Engineering and Artificial Intelligence (ICCEAI), 2021: 331–334. https://doi.org/10.1109/ICCEAI52939.2021.00066. [21] Tang M C S, Teoh S S, Ibrahim H. Retinal vessel segmentation from fundus images using DeepLabv3+[C]//2022 IEEE 18th International Colloquium on Signal Processing & Applications (CSPA), 2022: 377–381. https://doi.org/10.1109/CSPA55076.2022.9781891. [22] Harkat H, Nascimento J M P, Bernardino A. Fire detection using residual deeplabv3+ model[C]//2021 Telecoms Conference (ConfTELE), 2021: 1–6. https://doi.org/10.1109/ConfTELE50222.2021.9435459. [23] Tang Y H, Han K, Guo J Y, et al. GhostNetv2: enhance cheap operation with long-range attention[C]//Proceedings of the 36th International Conference on Neural Information Processing Systems, 2022: 724. https://doi.org/10.5555/3600270.3600994. [24] Liu X Y, Peng H W, Zheng N X, et al. EfficientViT: Memory efficient vision transformer with cascaded group attention[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023: 14420–14430. https://doi.org/10.1109/CVPR52729.2023.01386. [25] Gu Z J, Jamison K W, Sabuncu M R, et al. Heritability and interindividual variability of regional structure-function coupling[J]. Nat Commun, 2021, 12(1): 4894. doi: 10.1038/s41467-021-25184-4 [26] Deng G H, Wu D Z, Chen W Z. Attention guided food recognition via multi-stage local feature fusion[J]. Comput Mater Continua, 2024, 80(2): 1985−2003. doi: 10.32604/cmc.2024.052174 [27] Chen Y P, Dai X Y, Liu M C, et al. Dynamic convolution: Attention over convolution kernels[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 11027–11036. https://doi.org/10.1109/CVPR42600.2020.01104. [28] Ji S P, Wei S Q, Lu M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set[J]. IEEE Trans Geosci Remote Sens, 2019, 57(1): 574−586. doi: 10.1109/TGRS.2018.2858817 [29] Ronneberger O, Fischer P, Brox T. U-net: convolutional networks for biomedical image segmentation[C]//18th International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015: 234–241. https://doi.org/10.1007/978-3-319-24574-4_28. [30] Badrinarayanan V, Kendall A, Cipolla R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(12): 2481−2495. doi: 10.1109/TPAMI.2016.2644615 [31] Chen L C, Zhu Y K, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proceedings of the 15th European Conference on Computer Vision (ECCV), 2018: 833–851. https://doi.org/10.1007/978-3-030-01234-2_49. [32] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 3431–3440. https://doi.org/10.1109/CVPR.2015.7298965. -
Overview
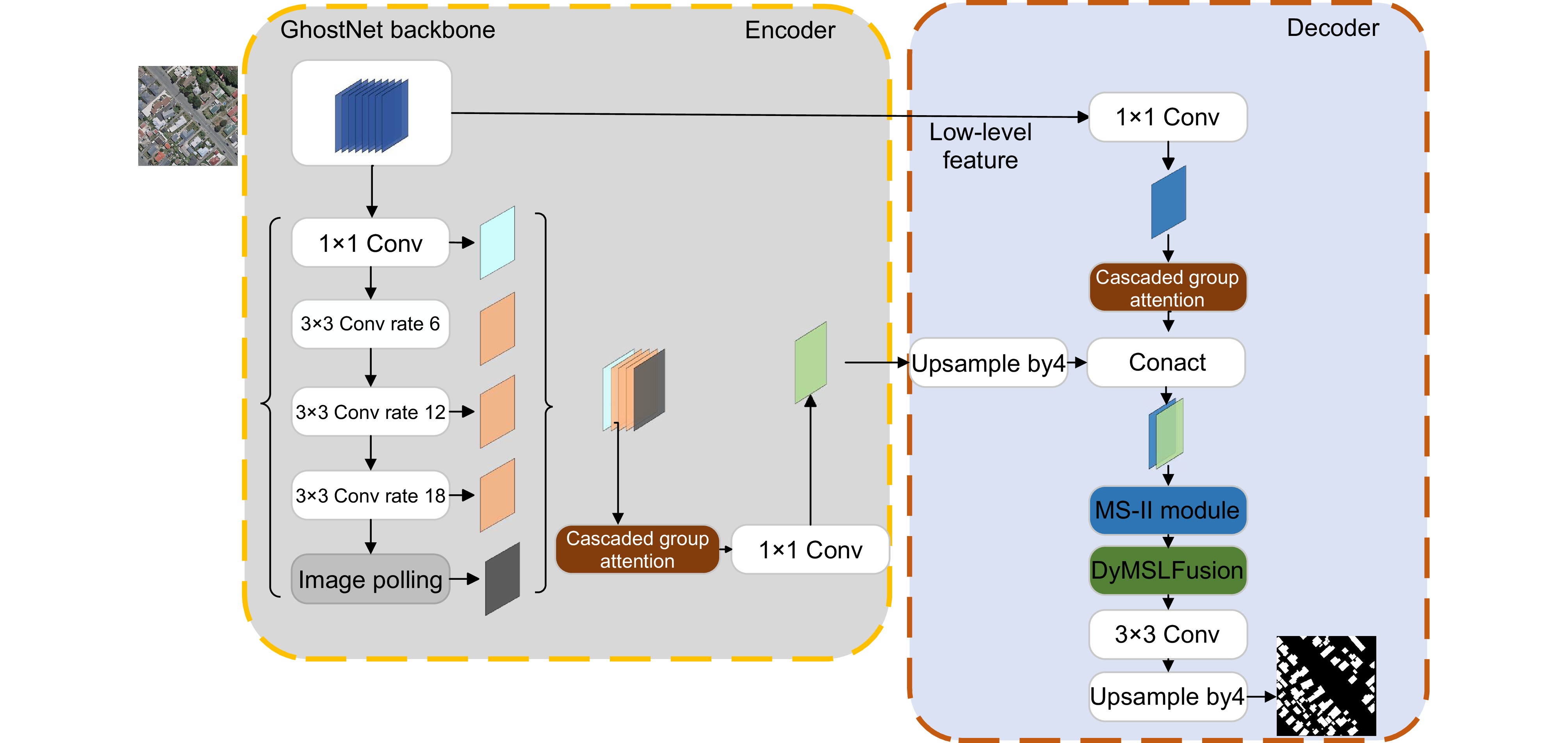
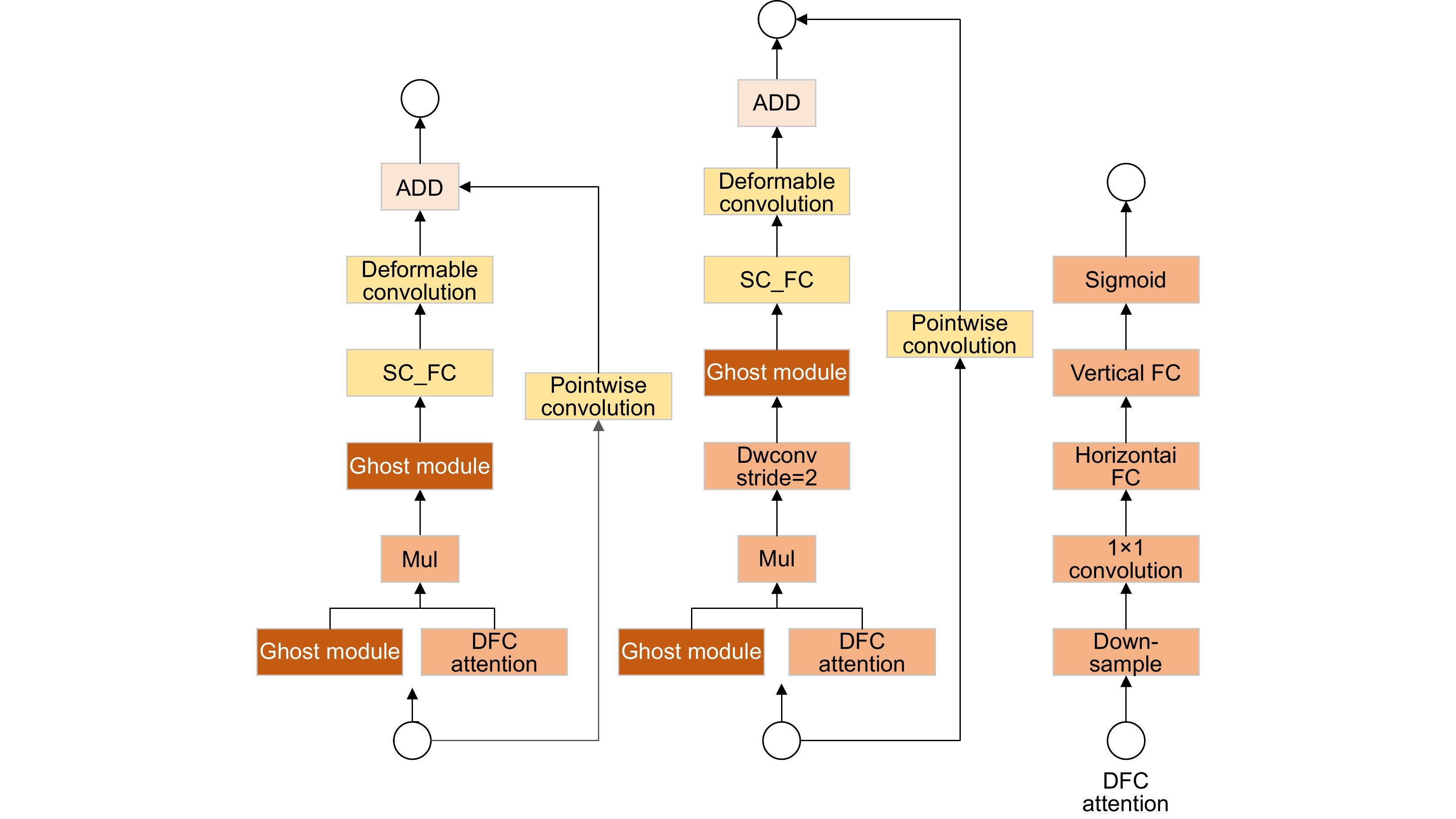
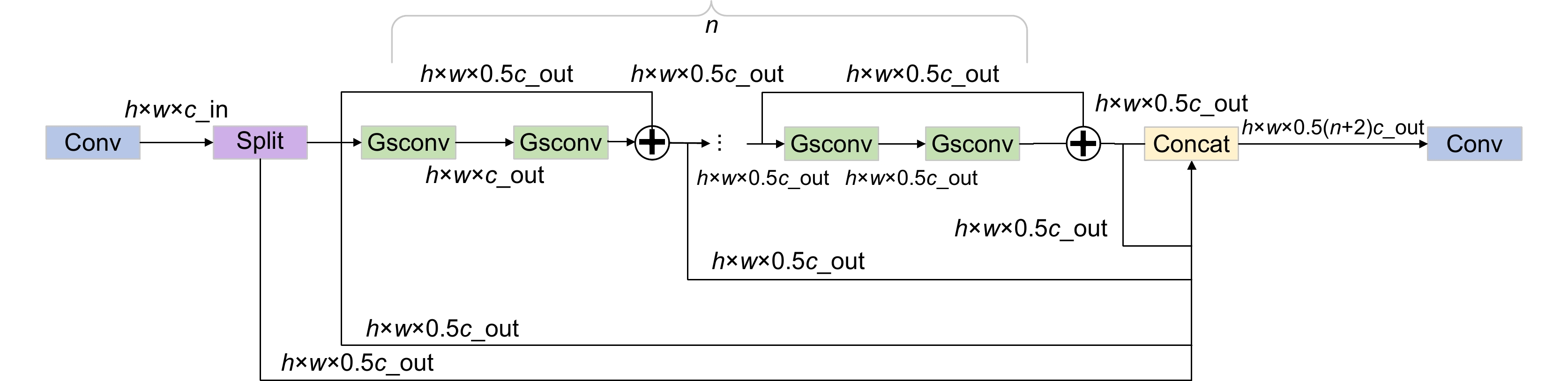
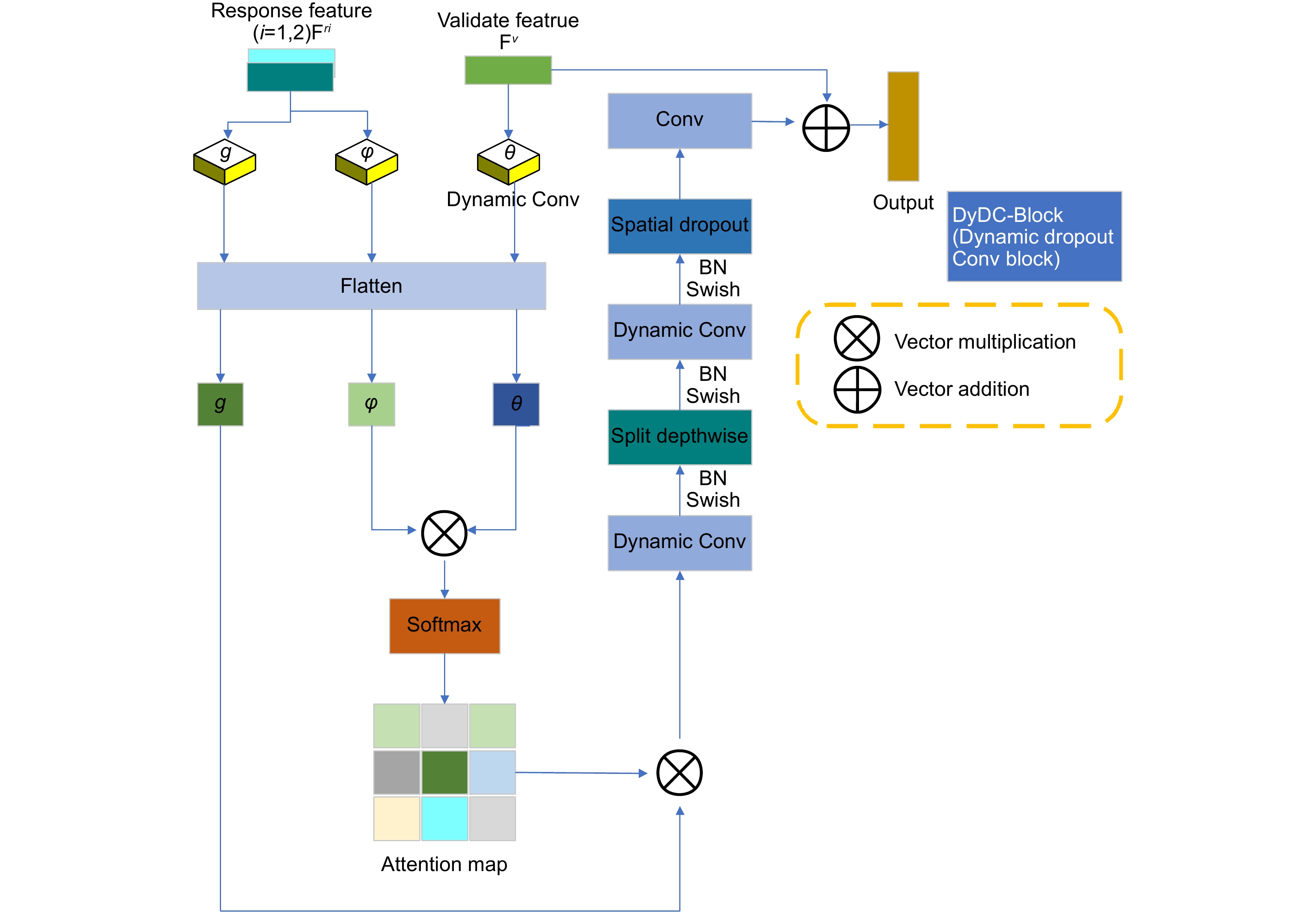
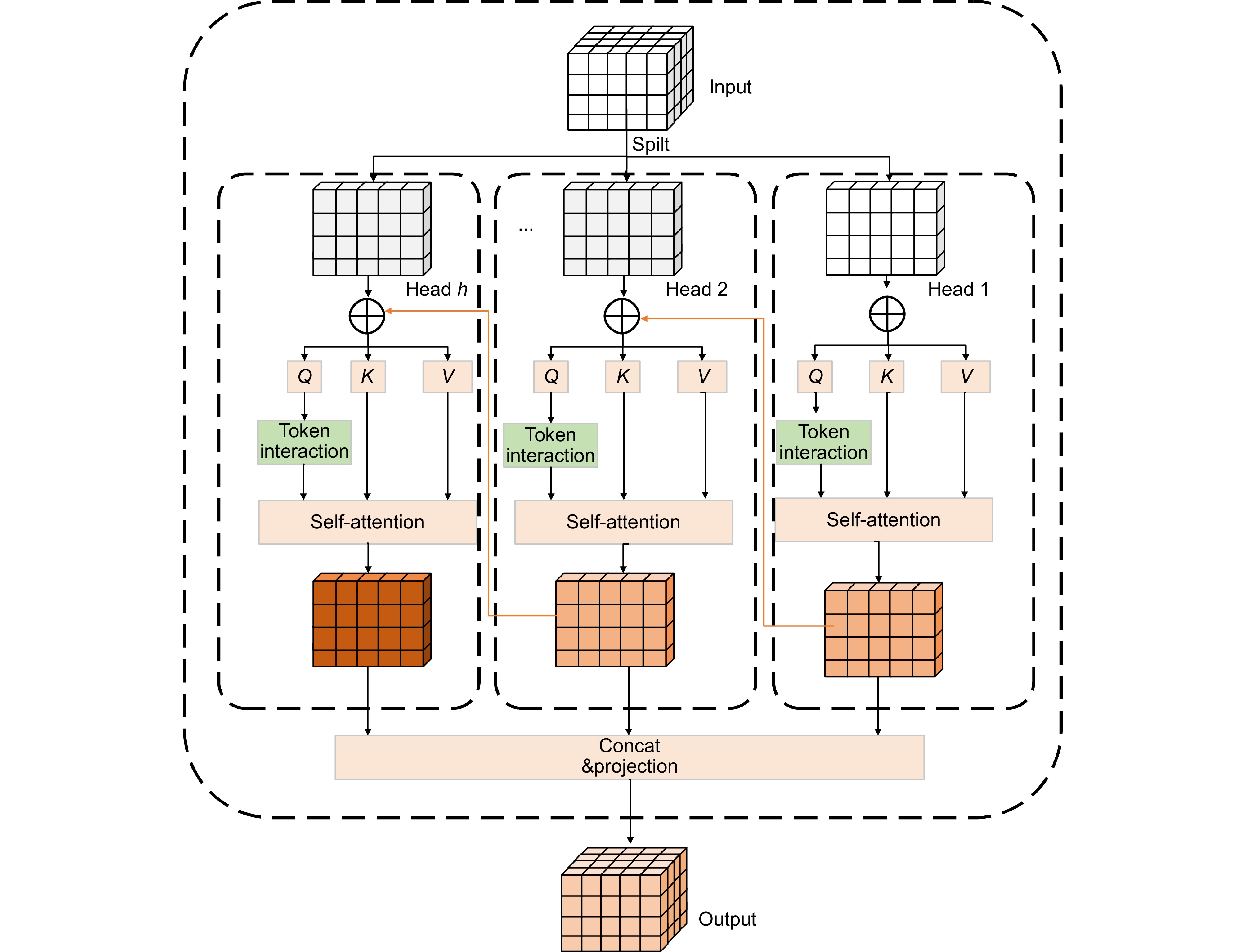
Due to the complex and variable characteristics of objects in remote sensing images, such as shape, size, texture, etc., objects may overlap with each other, and at the same time, they are affected by environmental factors such as atmospheric conditions, cloud cover, and changes in lighting, which leads to a decline in image quality and increases the difficulty of accurate segmentation. Modern deep learning technology has enabled semantic segmentation models to show strong robustness and recognition ability in complex scenes, but due to the differences in regions and application scenarios, there still exist problems such as insufficient capture of complex scene details, insufficient capture of long-distance dependencies, and difficulty in integrating multi-scale features, which makes the research in the direction of semantic segmentation very important. Aiming at the poor segmentation effect caused by large scale difference of objects, uneven spatial distribution of samples, fuzzy boundaries of objects and large span of scene area, this paper proposes a high-precision remote sensing building segmentation algorithm enhanced by integrating dynamic features. Firstly, the New_GhostNetV2 network is constructed, and the adaptive context-aware convolution is used to strengthen the discriminative ability of geometric deformation and the recognition ability of strong correlation features, improve the algorithm's ability to capture the local spatial features of samples and the global long-term dependence relationship, and realize the preliminary learning of sample images. Secondly, multi-level information enhancement modules are designed using Ghost Convolution combined with skip connections and feature branching strategies to solve the problem of key information loss and feature ambiguity caused by subsampling, enhance feature interaction and integration, and effectively reduce boundary ambiguity and segmentation errors. Then, the feature fusion module is constructed by the dynamic depth feature enhancer. According to the spatial position correlation of the feature, the feature mapping is self-adapted by channel and cross-scale to further strengthen the model's ability to mine and capture global key features and local fine-grained features, and improve the algorithm's attention to small objects. Finally, a cascade grouping attention mechanism is introduced to adjust the proportion of low-level and high-level features layer by layer, effectively suppressing background interference, and gradually optimize the segmentation results, so that the model can better cope with the diversified features in the image. Experimental results on the WHU dataset show that, compared with the baseline model, the improved algorithm is 8.57% higher than F1-Score, 12.48% higher than mIou, 13.28% higher than Recall and 12.13% higher than precision. Compared with other mainstream semantic segmentation models, the improved DeepLabv3+ has better segmentation accuracy, effectively improving semantic segmentation performance.
-
Access History
Figures(9)
Tables(2)
Article Metrics


Export File
Citation
Xiao Z J, Tian H, Zhang J H, et al. Fusion of dynamic features enhances remote sensing building segmentation[J]. Opto-Electron Eng, 2025, 52(3): 240231. doi: 10.12086/oee.2025.240231
Format
Content
 DownLoad:
DownLoad:

-
Figure 1.
Overall model structure
-
Figure 2.
Structure of backbone network (New_GhostNetV2)
-
Figure 3.
Information integration (MS-II) module
-
Figure 4.
Feature fusion module (DyMSLFusion)
-
Figure 5.
Attention mechanism (CGA)
-
Figure 6.
Dataset sample and label chart example
-
Figure 7.
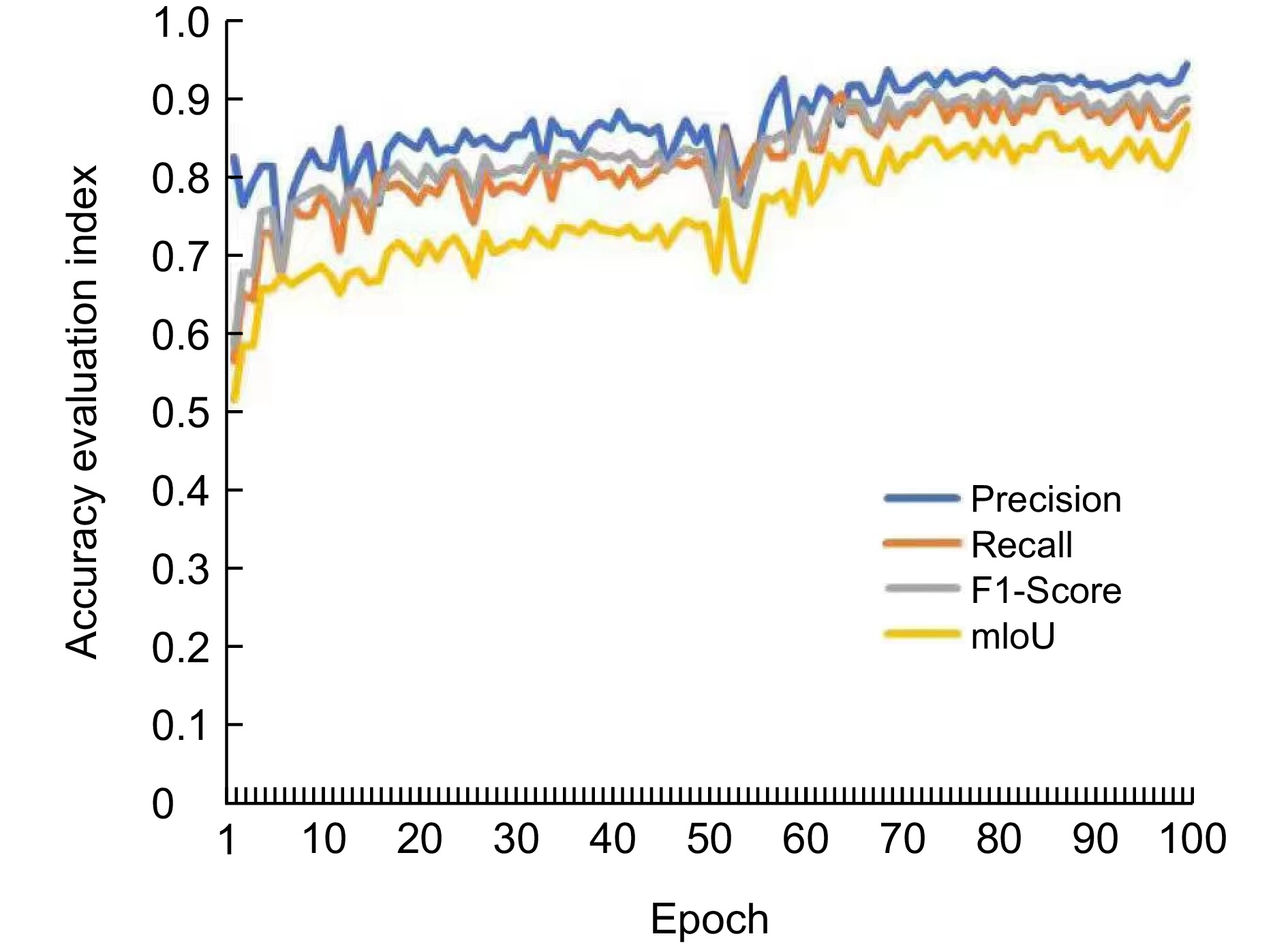
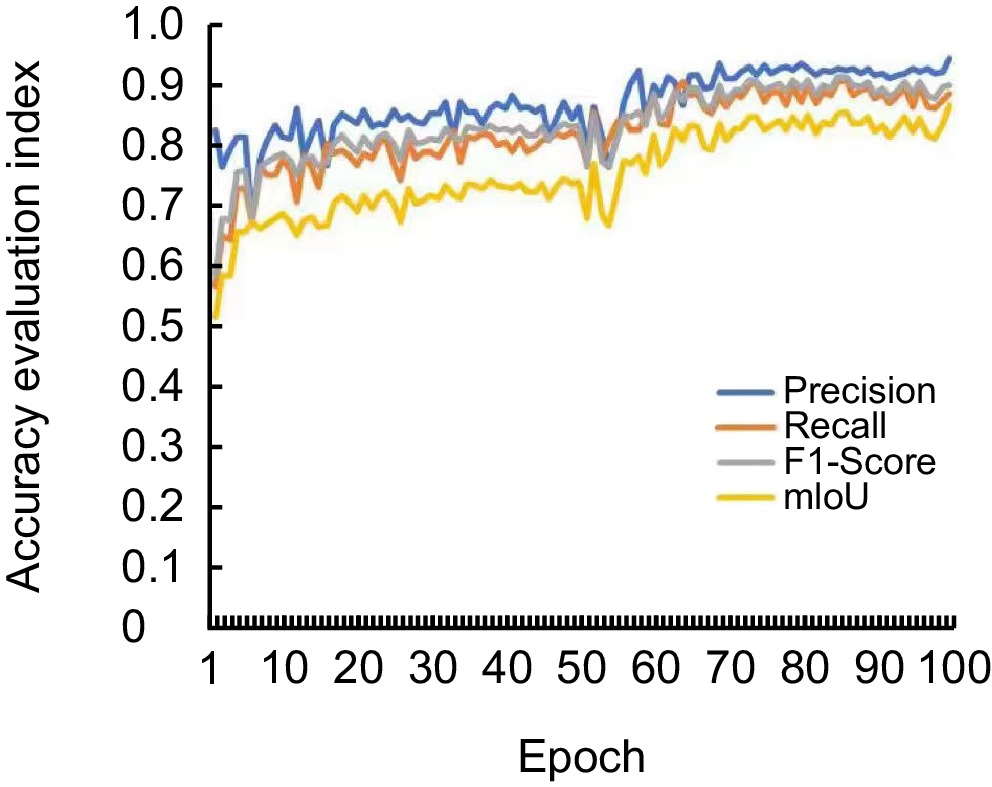
Accuracy diagram of evaluation index of the improved model
-
Figure 8.
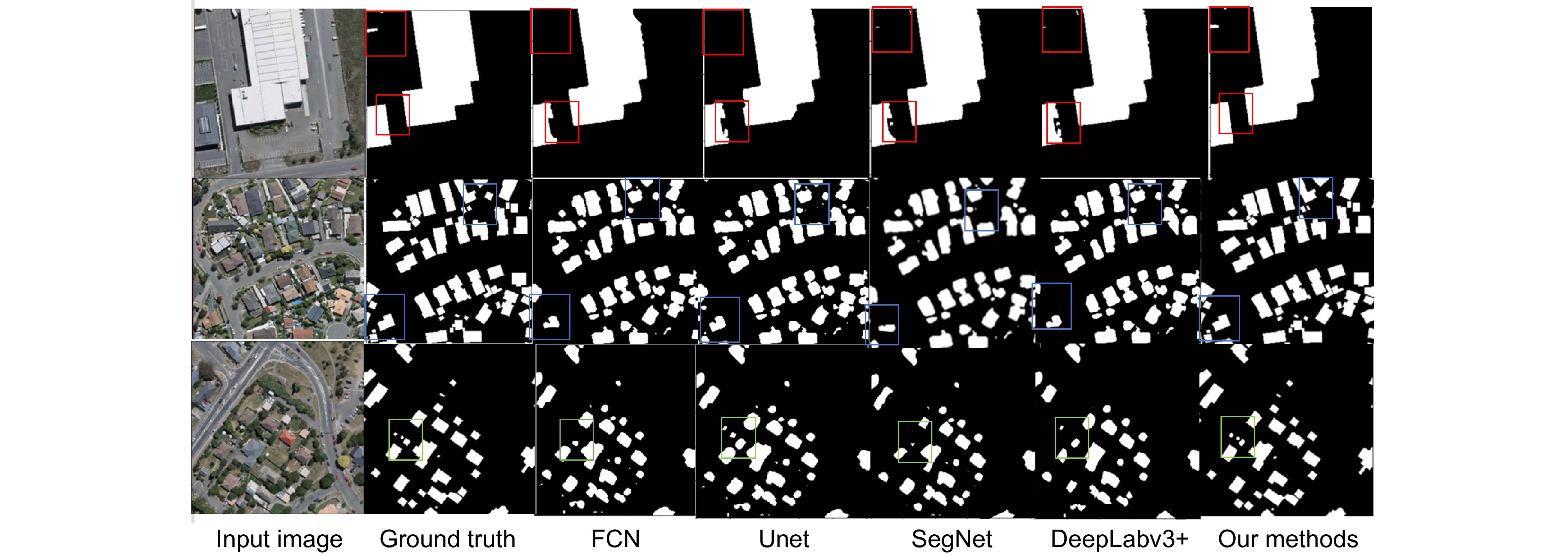
Comparison of segmentation effects of different models
- Figure .


