
 E-mail Alert
E-mail Alert RSS
RSS
| Citation: |
Cai H Y, Yang Z Q, Cui Z Y, et al. Image-guided and point cloud space-constrained method for detection and localization of abandoned objects on the road[J]. Opto-Electron Eng, 2024, 51(3): 230317. doi: 10.12086/oee.2024.230317

|
Image-guided and point cloud space-constrained method for detection and localization of abandoned objects on the road
-
Abstract
Abandoned objects on the road significantly impact traffic safety. To address issues such as missed detections, false alarms, and localization difficulties encountered in detecting of small-to-medium-sized abandoned objects, this paper proposes a method for detecting and locating abandoned objects on the road using image guidance and point cloud spatial constraints. The method employs an improved YOLOv7-OD network to process image data, extracting information about two-dimensional target bounding boxes. Subsequently, these bounding boxes are projected onto the coordinate system of the LiDAR sensor to get a pyramidal region of interest (ROI). Under the spatial constraints of the point cloud within the ROI, the detection and localization results of abandoned objects on the road in three-dimensional space are obtained through a combination of point cloud clustering and point cloud generation algorithms. The experimental results show that the improved YOLOv7-OD network achieves recall and average precision rates of 85.4% and 82.0%, respectively, for medium-sized objects, representing an improvement of 6.6% and 8.0% compared to the YOLOv7. The recall and average precision rates for small-sized objects are 66.8% and 57.3%, respectively, with an increase of 5.3%. Regarding localization, for targets located 30-40 m away from the detecting vehicle, the depth localization error is 0.19 m, and the angular localization error is 0.082°, enabling the detection and localization of multi-scale abandoned objects on the road.-
Keywords:
- abandoned objects on the road /
- image /
- LiDAR point cloud /
- object detection
-

-
References
[1] Liu W, Anguelov D, Erhan D, et al. SSD: single shot multibox detector[C]//14th European Conference on Computer Vision, Amsterdam, 2016: 21–37. https://doi.org/10.1007/978-3-319-46448-0_2. [2] Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, 2017: 2999–3007. https://doi.org/10.1109/ICCV.2017.324. [3] Carion N, Massa F, Synnaeve G, et al. End-to-end object detection with transformers[C]//16th European Conference on Computer Vision, Glasgow, 2020: 213–229. https://doi.org/10.1007/978-3-030-58452-8_13. [4] Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: optimal speed and accuracy of object detection[Z]. arXiv: 2004.10934, 2020. https://doi.org/10.48550/arXiv.2004.10934. [5] Redmon J, Farhadi A. YOLOv3: an Incremental Improvement[Z]. arXiv: 1804.02767, 2018. https://doi.org/10.48550/arXiv.1804.02767. [6] Li C Y, Li L L, Jiang H L, et al. YOLOv6: a single-stage object detection framework for industrial applications[Z]. arXiv: 2209.02976, 2022. https://doi.org/10.48550/arXiv.2209.02976. [7] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Trans Pattern Anal Mach Intell, 2017, 39(6): 1137−1149. doi: 10.1109/TPAMI.2016.2577031 [8] He K M, Gkioxari G, Dollár P, et al. Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision (ICCV), Venice, 2017: 2980–2988. https://doi.org/10.1109/ICCV.2017.322. [9] 金瑶, 张锐, 尹东. 城市道路视频中小像素目标检测[J]. 光电工程, 2019, 46(9): 190053. Jin Y, Zhang R, Yin D. Object detection for small pixel in urban roads videos[J]. Opto-Electron Eng, 2019, 46(9): 190053. [10] Charles R Q, Hao S, Mo K C, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, 2017: 77–85. https://doi.org/10.1109/CVPR.2017.16. [11] Qi C R, Yi L, Su H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, 2017: 5105–5114. https://doi.org/10.5555/3295222.3295263. [12] Qian G C, Li Y C, Peng H W, et al. PointNeXt: Revisiting pointnet++ with improved training and scaling strategies[C]//36th Conference on Neural Information Processing Systems, New Orleans, 2022: 23192–23204. [13] Qi C R, Liu W, Wu C X, et al. Frustum PointNets for 3D object detection from RGB-D data[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 2018: 918–927. https://doi.org/10.1109/CVPR.2018.00102. [14] Vora S, Lang A H, Helou B, et al. PointPainting: sequential fusion for 3D object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2020: 4603–4611. https://doi.org/10.1109/CVPR42600.2020.00466. [15] 梁浩林, 蔡怀宇, 刘博翀, 等. 基于图像与点云融合的公路撒落物检测算法[J]. 激光与光电子学进展, 2023, 60(10): 1010001. doi: 10.3788/LOP213044 Liang H L, Cai H Y, Liu B C, et al. Road falling objects detection algorithm based on image and point cloud fusion[J]. Laser Optoelectron Prog, 2023, 60(10): 1010001. doi: 10.3788/LOP213044 [16] 郑欣悦, 赖际舟, 吕品, 等. 基于红外视觉/激光雷达融合的目标识别与定位方法[J]. 导航定位与授时, 2021, 8(3): 34−41. doi: 10.19306/j.cnki.2095-8110.2021.03.005 Zheng X Y, Lai J Z, Lv P, et al. Object detection and positioning method based on infrared vision/lidar fusion[J]. Navig Position Timing, 2021, 8(3): 34−41. doi: 10.19306/j.cnki.2095-8110.2021.03.005 [17] 范婉舒, 赖际舟, 吕品, 等. 基于改进DeepSORT的视觉/激光雷达目标跟踪与定位方法[J]. 导航定位与授时, 2022, 9(4): 77−84. doi: 10.19306/j.cnki.2095-8110.2022.04.009 Fan W S, Lai J Z, Lv P, et al. Vision/lidar object tracking and localization method based on improved DeepSORT[J]. Navig Position Timing, 2022, 9(4): 77−84. doi: 10.19306/j.cnki.2095-8110.2022.04.009 [18] Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, 2023: 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721. [19] Zhang W M, Qi J B, Wan P, et al. An easy-to-use airborne LiDAR data filtering method based on cloth simulation[J]. Remote Sens, 2016, 8(6): 501. doi: 10.3390/rs8060501 [20] Huang J K, Grizzle J W. Improvements to target-based 3D LiDAR to camera calibration[J]. IEEE Access, 2020, 8: 134101−134110. doi: 10.1109/ACCESS.2020.3010734 [21] Sun P, Kretzschmar H, Dotiwalla X, et al. Scalability in perception for autonomous driving: waymo open dataset[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, 2020: 2443–2451. https://doi.org/10.1109/CVPR42600.2020.00252. [22] Ge Z, Liu S T, Wang F, et al. YOLOX: exceeding YOLO series in 2021[Z]. arXiv: 2107.08430, 2021. https://doi.org/10.48550/arXiv.2107.08430. [23] Jocher G, Chaurasia A, Stoken A, et al. ultralytics/yolov5: v7.0 - YOLOv5 SOTA Realtime Instance Segmentation[EB/OL]. (2022-11-22). https://github.com/ultralytics/yolov5. [24] Jocher G, Chaurasia A, Qiu J. Ultralytics YOLO[EB/OL]. (2023-01-10). https://github.com/ultralytics/ultralytics. -
Overview
Highways constitute a vital economic lifeline for a nation. With the continuous increase in highway mileage and traffic volume, the significance of daily maintenance work on the road has become more pronounced. The detection and localization of abandoned objects on the road are among the primary tasks in highway maintenance. Because if abandoned objects are not promptly cleared, they can easily lead to traffic congestion or even cause accidents. Detecting and locating abandoned objects on the road is a specific object detection task. In order to fully leverage the advantages of both image and point cloud data, solutions based on multisensor fusion have become a research hotspot. However, due to the sparse nature of the LiDAR point clouds, existing multisensor fusion methods usually encounter challenges such as missed detection, false alarms, and difficulties in localization when detecting small-to-medium-sized abandoned objects. To address the aforementioned issues, this paper proposes a method for detecting and locating abandoned objects on the road using image guidance and point cloud spatial constraints. Firstly, on the foundation of the YOLOv7, a small object detection layer has been added, and a channel attention mechanism has been introduced to enhance the network's ability to extract two-dimensional bounding boxes for small-to-medium-sized targets within the image. Subsequently, the predicted bounding boxes are projected onto the LiDAR coordinate system to generate a pyramidal region of interest (ROI). For larger targets, sufficient point cloud data allows for three-dimensional spatial position estimation through point cloud clustering within the ROI. For smaller targets, which have insufficient point cloud data for clustering within the ROI, spatial constraints from surrounding ground point cloud data are used. Using projection transformation relationships, point cloud data is generated to obtain spatial position information for the smaller targets, achieving the detection and localization of multiscale abandoned objects on the road in three-dimensional space. The experimental results show that the improved YOLOv7-OD network achieves recall and average precision rates of 85.4% and 82.0%, respectively, for medium-sized objects, representing improvements of 6.6% and 8% compared to the YOLOv7. The recall and average precision rates for small-sized objects are 66.8% and 57.3%, respectively, with an increase of 5.3%. In terms of localization, for abandoned objects located 30~40 m away from the detecting vehicle, the depth localization error is 0.19 m, and the angular localization error is 0.082°. The proposed algorithm can process 36 frames of data per second, effectively achieving real-time detection and localization of abandoned objects on the road.
-
Access History
Figures(12)
Tables(6)
Article Metrics


Export File
Citation
Cai H Y, Yang Z Q, Cui Z Y, et al. Image-guided and point cloud space-constrained method for detection and localization of abandoned objects on the road[J]. Opto-Electron Eng, 2024, 51(3): 230317. doi: 10.12086/oee.2024.230317
Format
Content
 DownLoad:
DownLoad:

-
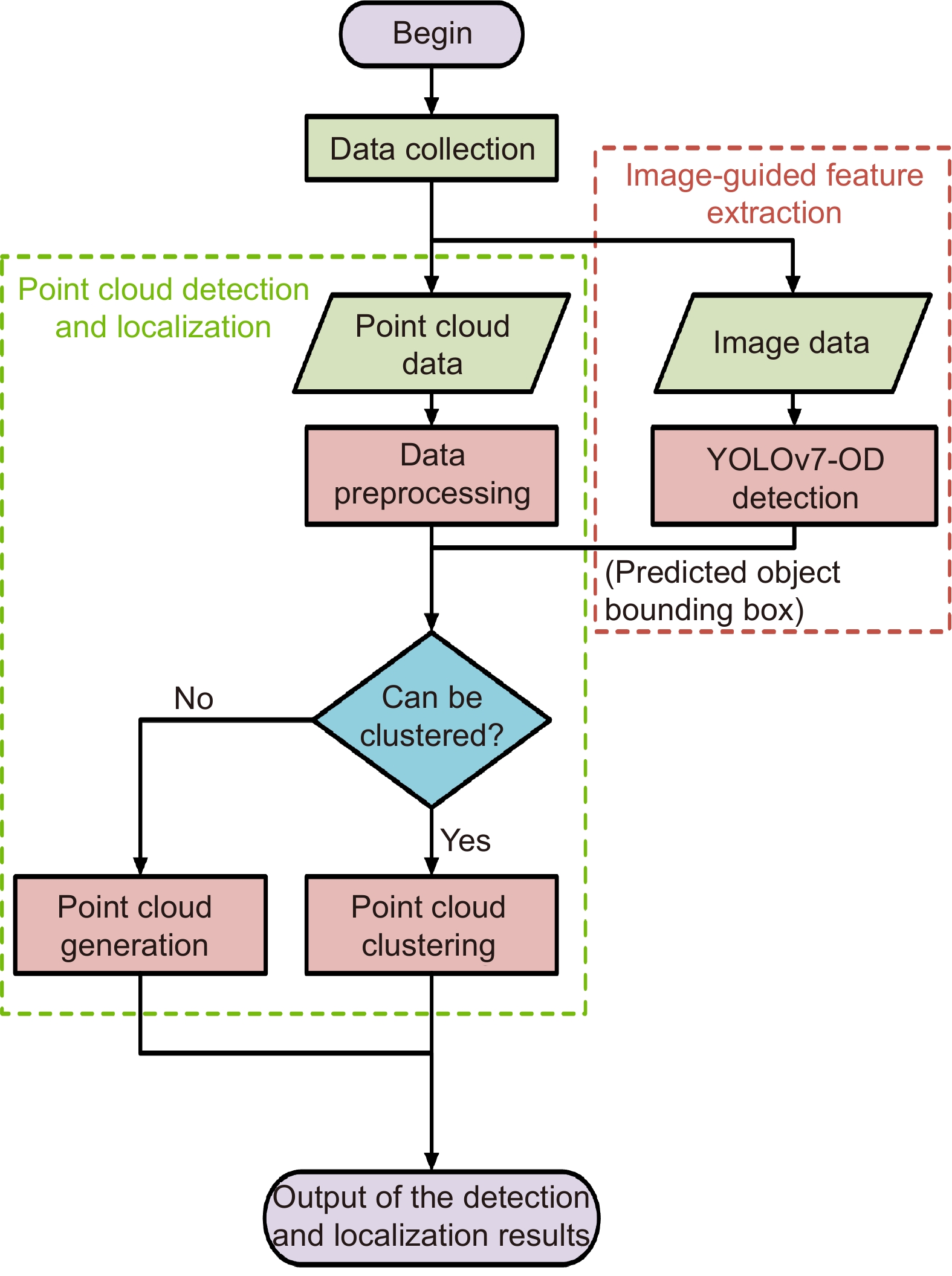
Figure 1.
The overall framework of the proposed method
-
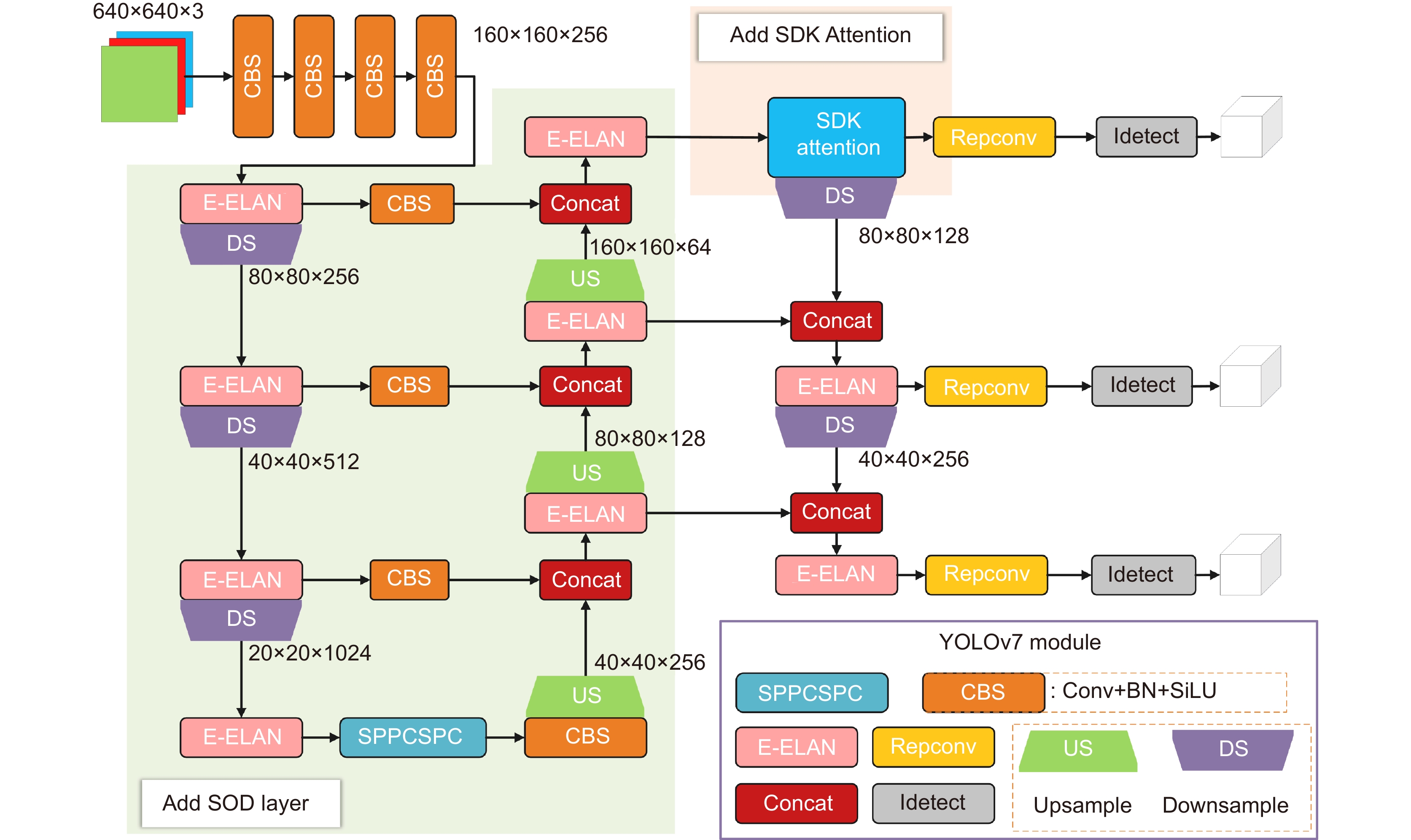
Figure 2.
The network architecture of YOLOv7-OD
-
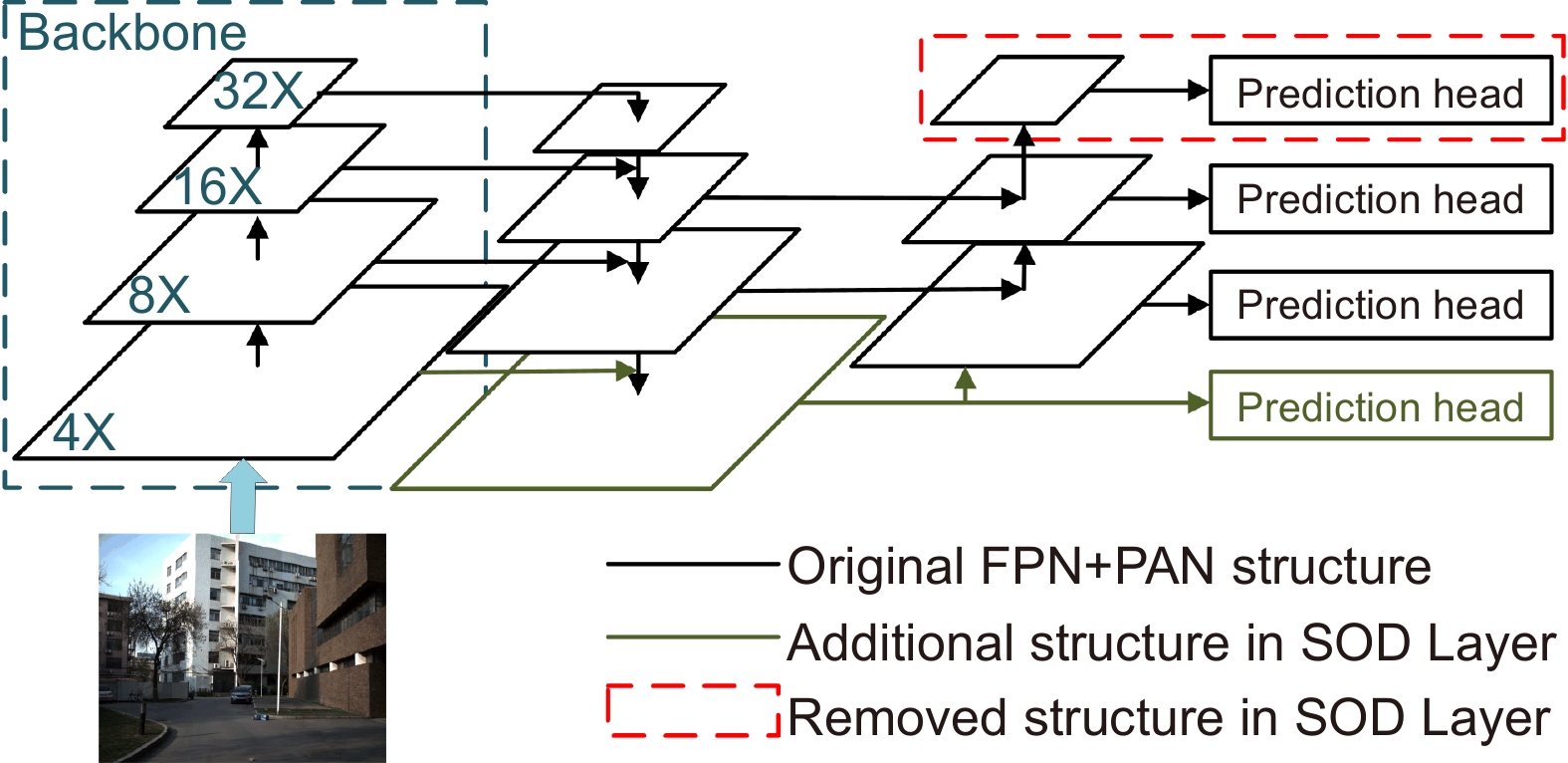
Figure 3.
The network structure of SOD Layer
-
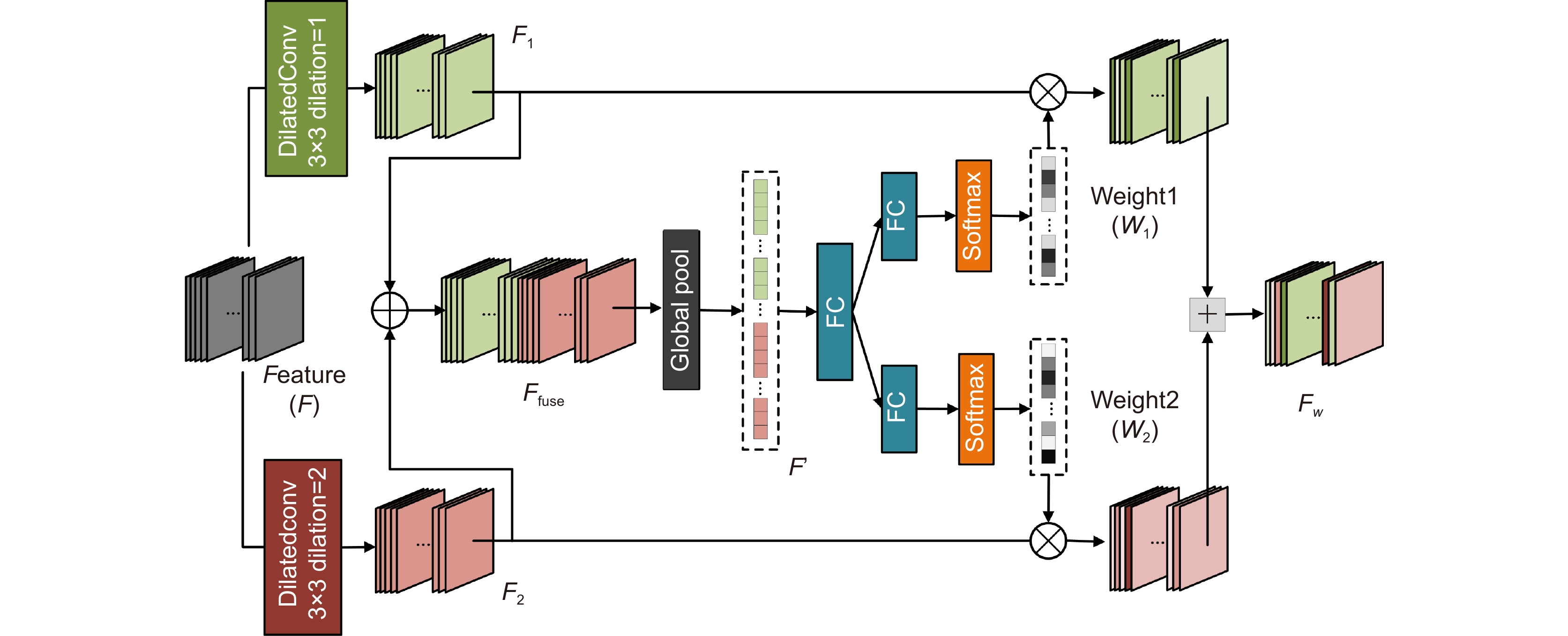
Figure 4.
SDK Attention module
-
Figure 5.
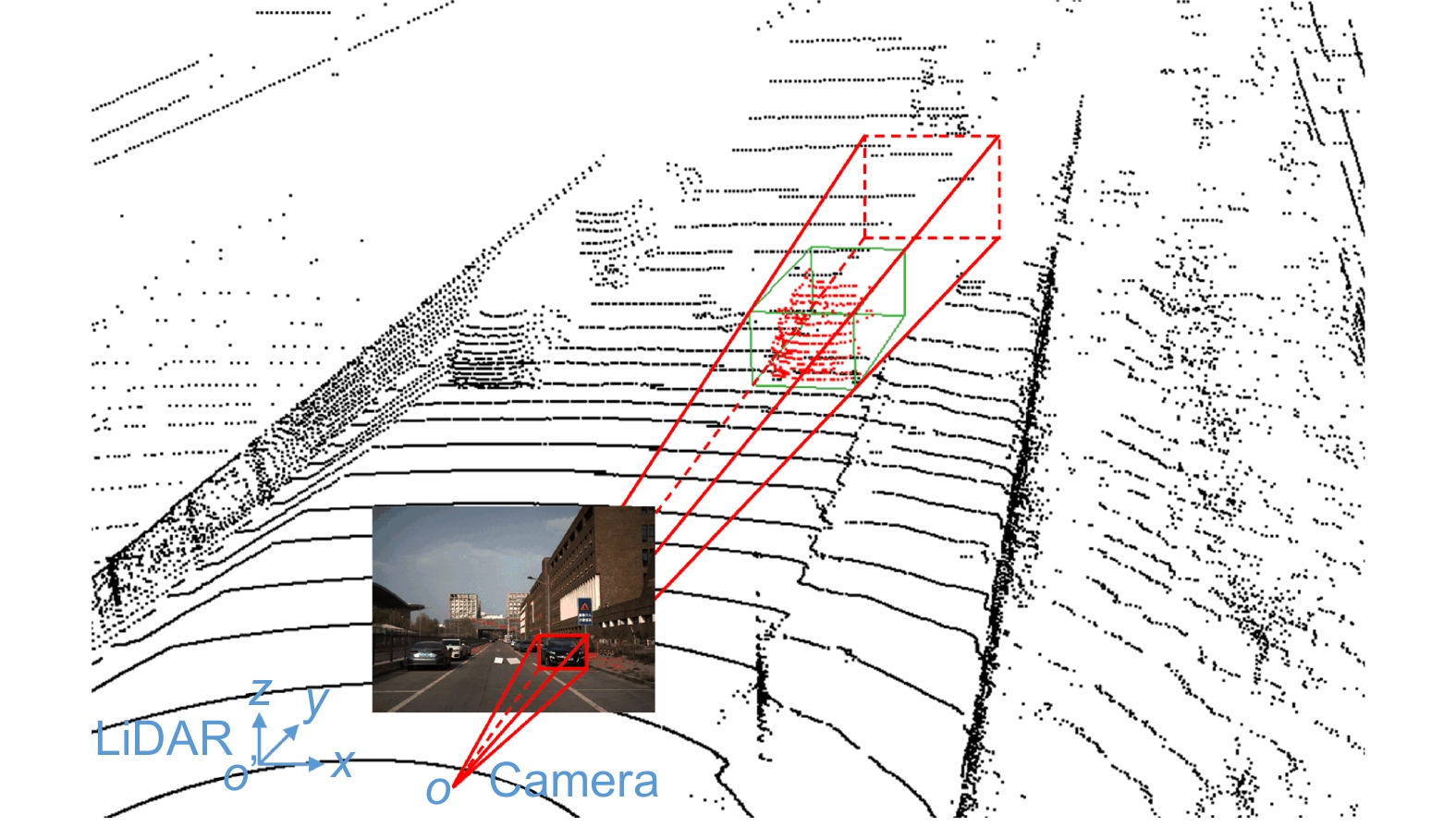
Generation of ROI areas in the LiDAR coordinate system based on image object detection bounding boxes
-
Figure 6.
Structural diagram of the experimental device
-
Figure 7.
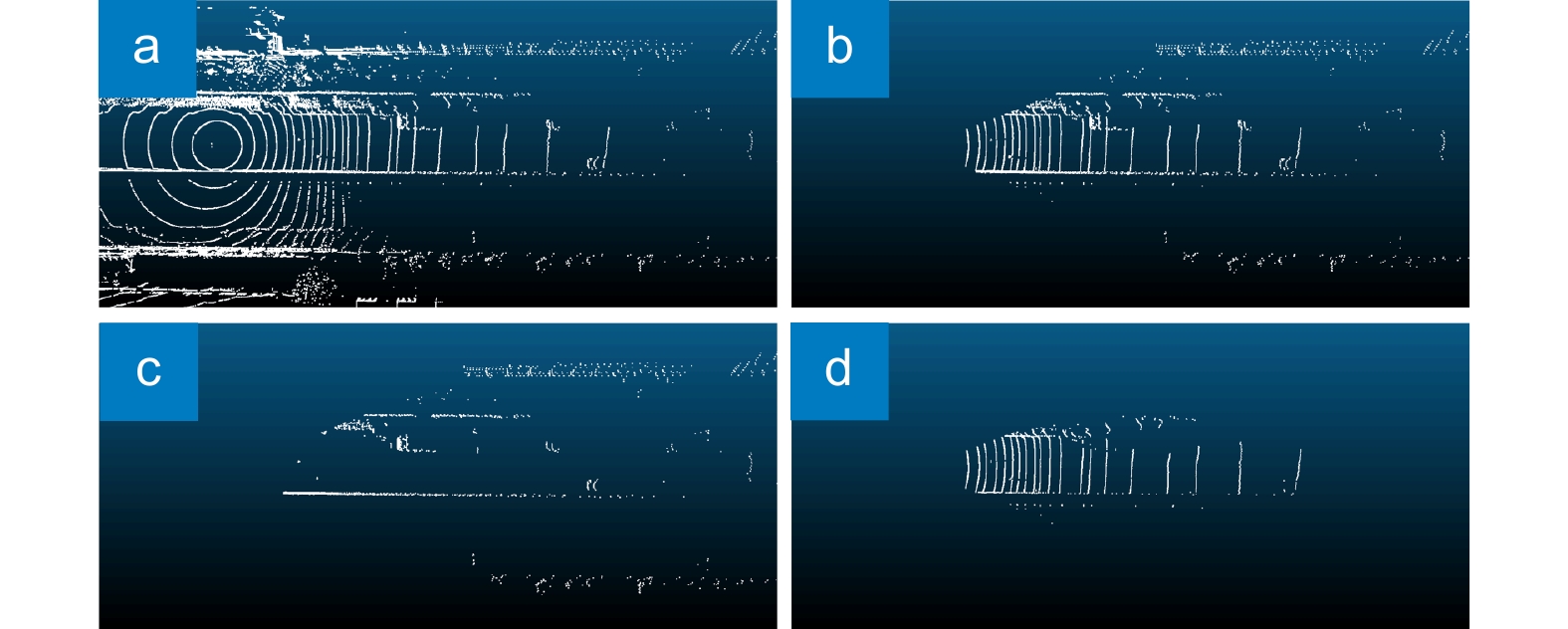
Filtering results. (a) Original point cloud data; (b) Effective point cloud data obtained by field-of-view matching; (c) Non-ground point cloud after CSF filtering; (d) Ground point cloud after CSF filtering
-
Figure 8.
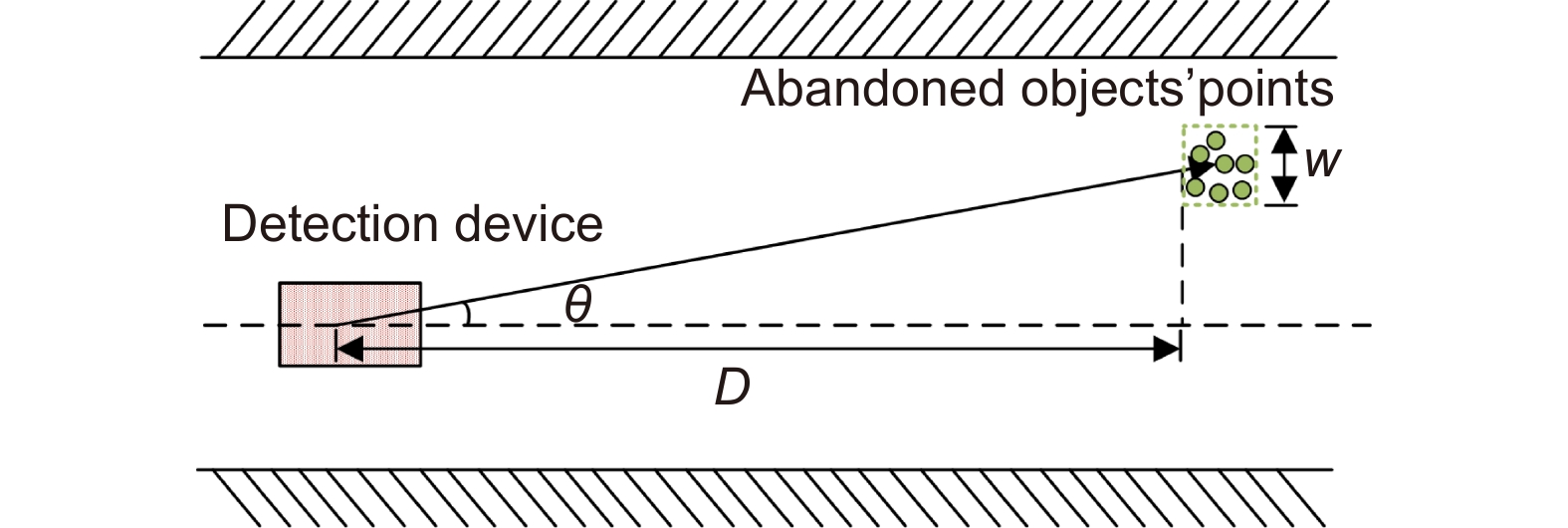
The specific meanings of various evaluation metrics in space
-
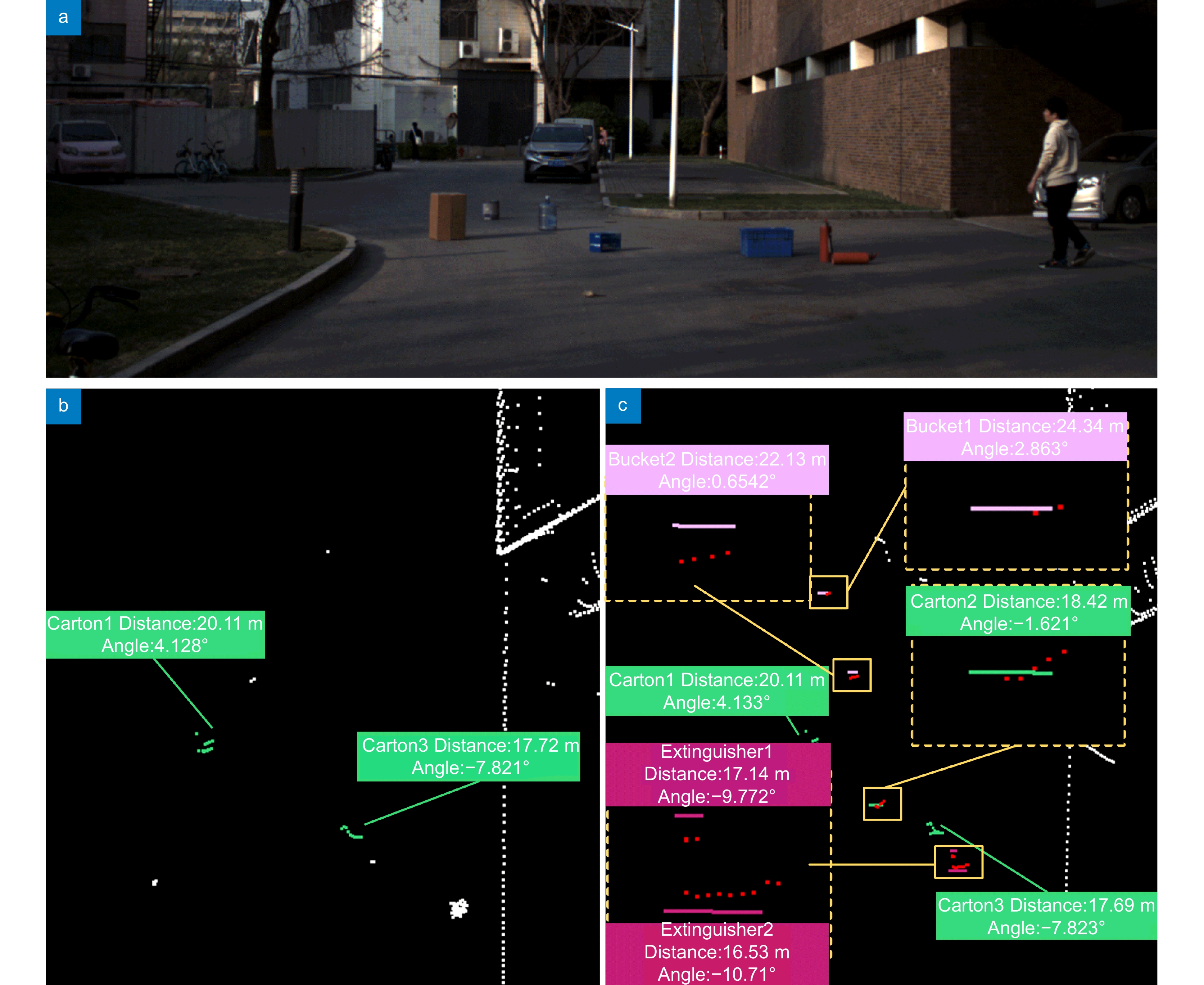
Figure 9.
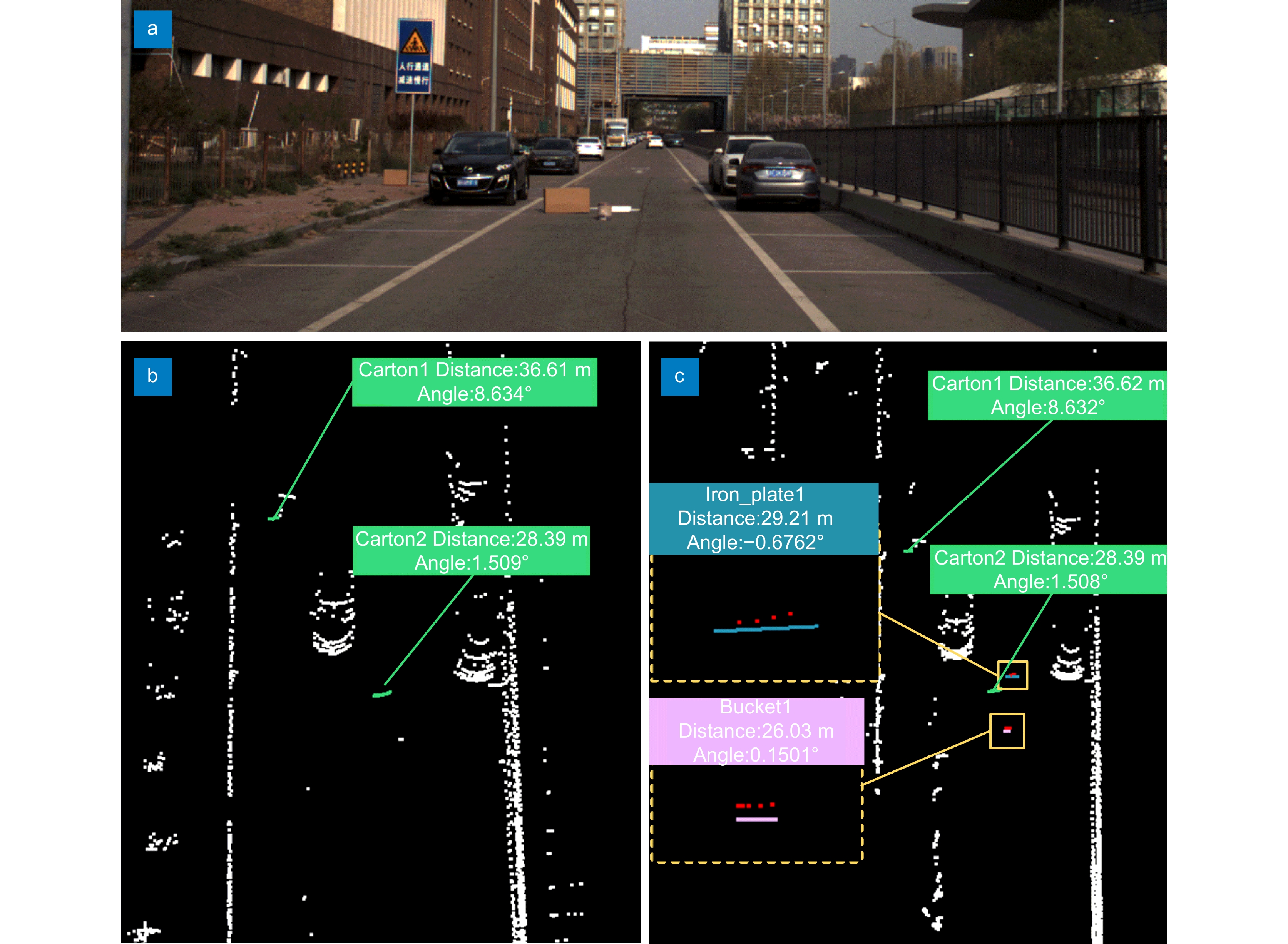
Detection and localization results for abandoned objects on the road (Scene one, selected partial area). (a) Image of the scene to be tested; (b) Detection and localization results by method A; (c) Detection and localization results by our method
-
Figure 10.
Detection and localization results for abandoned objects on the road (Scene two, selected partial area). (a) Image of the scene to be tested; (b) Detection and localization results by method A; (c) Detection and localization results by our method
-
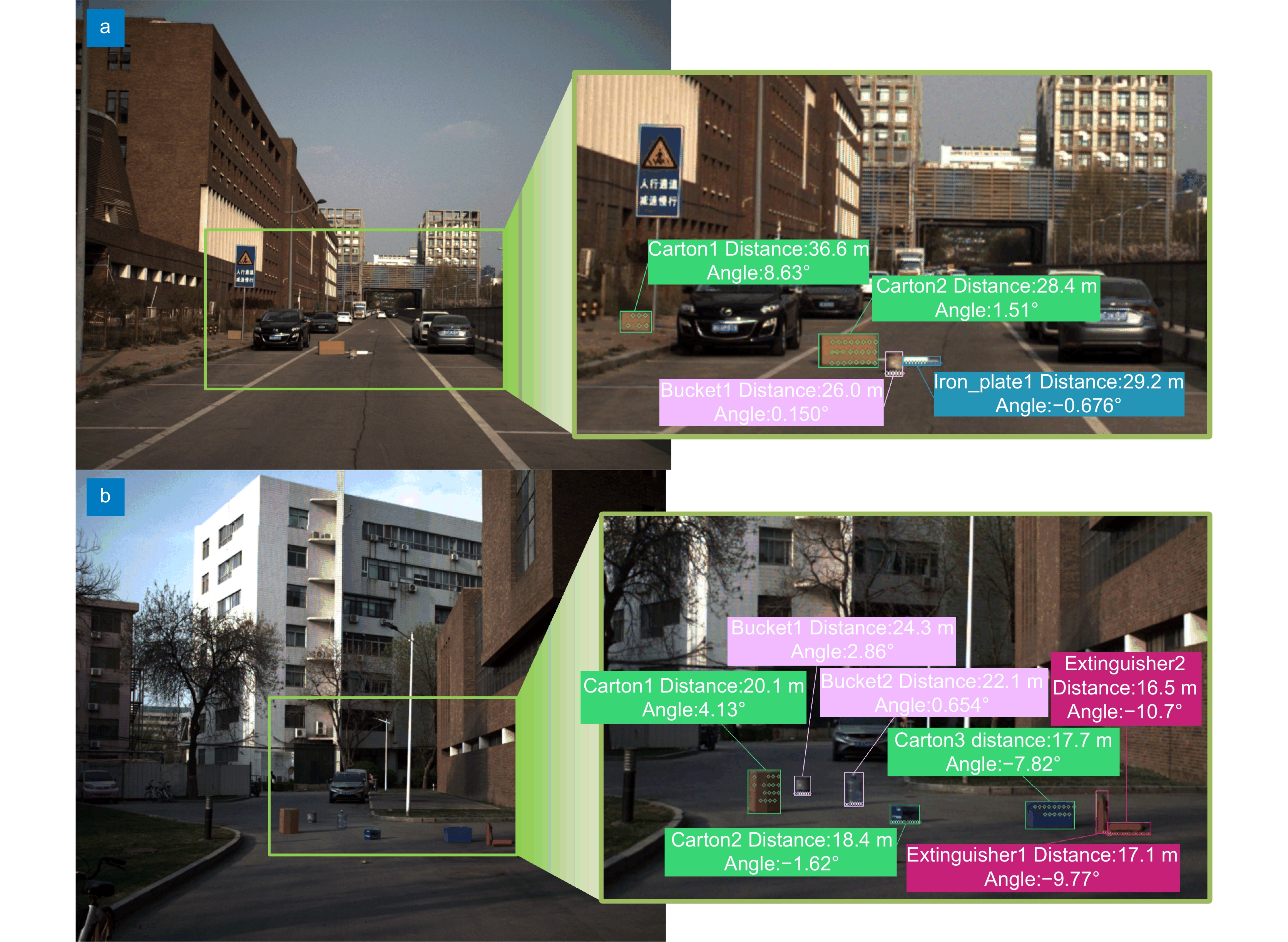
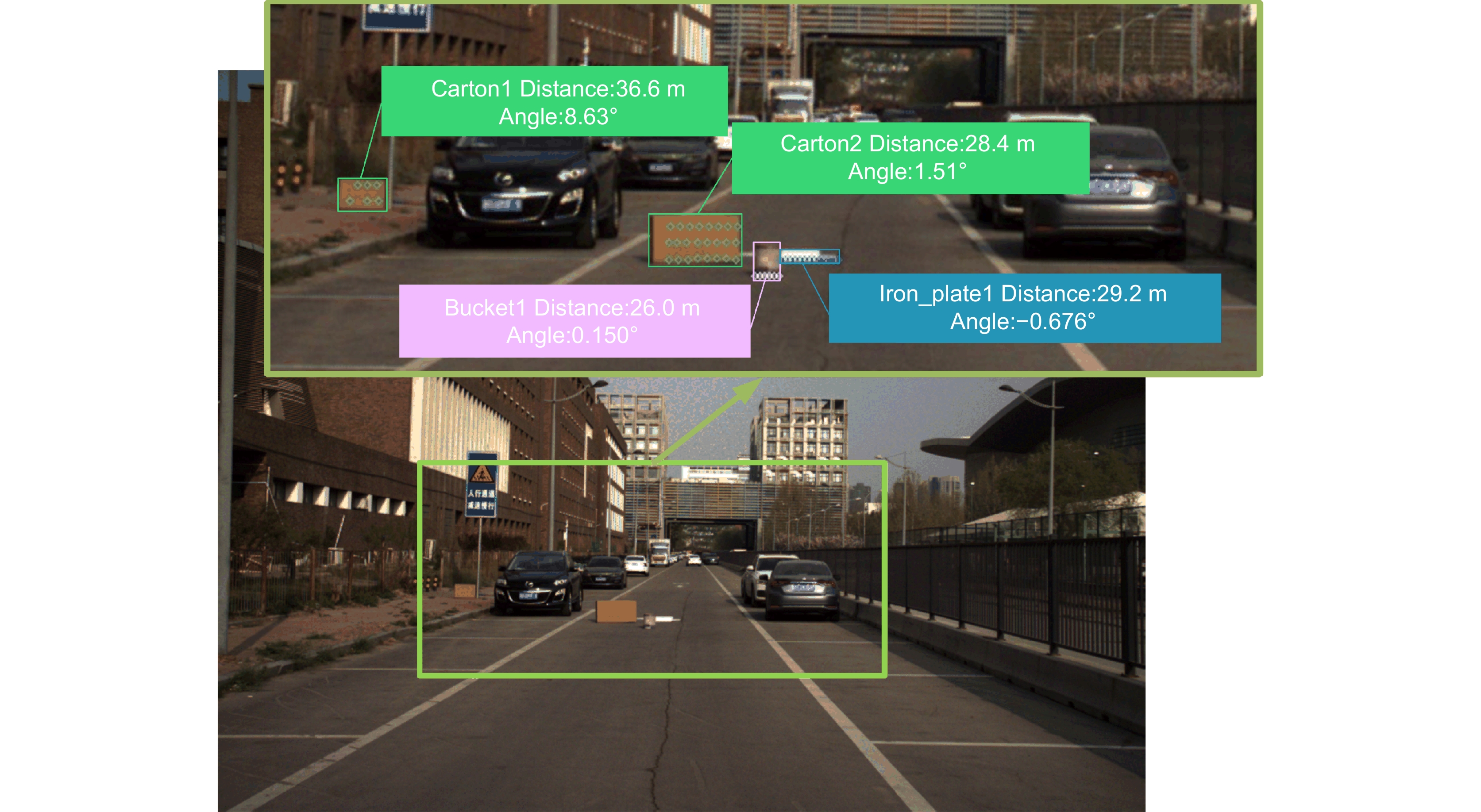
Figure 11.
Experimental results for detecting and locating abandoned objects on the road. (a) Scene one; (b) Scene two
- Figure .


